ChatGPT disabled for users in Italy

*Dear ChatGPT customer, * *We regret to inform you that we have disabled ChatGPT for users in Italy at the request of the Italian Garante.* Attenzione: questa non è l'ennesima idiozia fascista come quella di mettere alcuni cibi contenenti farina di insetti su scaffali separati, o proibire la produzione di carne sintetica, o minacciare multe per chi usa anglismi. No: questa è una cosa che danneggia chi fa uso professionale dei servizi di OpenAI, primi tra tutti gli sviluppatori di software. Non è che i rilievi del Garante non siano fondati, ma se li si dovesse applicare con coerenza dovremmo metterci dietro a un firewall come la Cina. Quindi si tratta di una boutade mediatica, ma stavolta gravemente nociva. G.

Il giorno sab 1 apr 2023 alle ore 07:26 Guido Vetere <vetere.guido@gmail.com> ha scritto:
*Dear ChatGPT customer, *
*We regret to inform you that we have disabled ChatGPT for users in Italy at the request of the Italian Garante.*
Attenzione: questa non è l'ennesima idiozia fascista come quella di mettere alcuni cibi contenenti farina di insetti su scaffali separati, o proibire la produzione di carne sintetica, o minacciare multe per chi usa anglismi.
No: questa è una cosa che danneggia chi fa uso professionale dei servizi di OpenAI, primi tra tutti gli sviluppatori di software.
Non è che i rilievi del Garante non siano fondati, ma se li si dovesse applicare con coerenza dovremmo metterci dietro a un firewall come la Cina.
Quindi si tratta di una boutade mediatica, ma stavolta gravemente nociva.
G.
Se l'intervento avrà un seguito anche negli altri paesi si potrebbe ottenere un dialogo proficuo con gli sviluppatori di questi servizi di OpenAI ma il problema penso che sia la Cina che andrà avanti da sola come un treno per recuperare l'attuale posizione di svantaggio e cercare di avere la leadership di questo settore di importanza strategica. Se il nostro Garante per la Privacy rimarrà isolato allora probabilmente dovrà fare qualche correzione di rotta. Sicuramente non c'è spazio per posizioni sovraniste solitarie che sono anacronistiche e autolesioniste. -- Paolo Del Romano
https://ultimora.net/2023/03/31/guida-come-aggirare-il-blocco-di-chat-gpt-in... vedo che dobbiamo cominciare a usare le VPN anche in Italia come accade in Cina, Russia, Turchia.... Paolo Del Romano

Voglio sperare che se OpenAI avesse raccolto i dati conformemente alle leggi e alla propria privacy policy, non avrebbe potuto essere censurata, diversamente da quanto accade in Cina, Russia e Turchia. Voglio sperare che questa insolita manifestazione di autorità da parte del Garante segnali una inversione di rotta anche per tutti gli altri che si collocano sopra la legge. Alberto Qui sotto la privacy policy di OpenAI reperibile ad oggi. Privacy policy UpdatedMarch 14, 2023 We at OpenAI, L.L.C. (together with our affiliates, “OpenAI”, “we”, “our” or “us”) respect your privacy and are strongly committed to keeping secure any information we obtain from you or about you. This Privacy Policy describes our practices with respect to Personal Information we collect from or about you when you use our website and services (collectively, “Services”). This Privacy Policy does not apply to content that we process on behalf of customers of our business offerings, such as our API. Our use of that data is governed by our customer agreements covering access to and use of those offerings. 1. Personal information we collect We collect information that alone or in combination with other information in our possession could be used to identify you (“Personal Information”) as follows: *Personal Information You Provide*: We may collect Personal Information if you create an account to use our Services or communicate with us as follows: * /Account Information:/ When you create an account with us, we will collect information associated with your account, including your name, contact information, account credentials, payment card information, and transaction history, (collectively, “Account Information”). * /User Content:/ When you use our Services, we may collect Personal Information that is included in the input, file uploads, or feedback that you provide to our Services (“Content”). * /Communication Information/: If you communicate with us, we may collect your name, contact information, and the contents of any messages you send (“Communication Information”). * /Social Media Information/: We have pages on social media sites like Instagram, Facebook, Medium, Twitter, YouTube and LinkedIn. When you interact with our social media pages, we will collect Personal Information that you elect to provide to us, such as your contact details (collectively, “Social Information”). In addition, the companies that host our social media pages may provide us with aggregate information and analytics about our social media activity. *Personal Information We Receive Automatically From Your Use of the Services*: When you visit, use, and interact with the Services, we may receive the following information about your visit, use, or interactions (“Technical Information”): * /Log Data/: Information that your browser automatically sends whenever you user our website(“log data”). Log data includes your Internet Protocol address, browser type and settings, the date and time of your request, and how you interacted with our website. * /Usage Data/: We may automatically collect information about your use of the Services, such as the types of content that you view or engage with, the features you use and the actions you take, as well as your time zone, country, the dates and times of access, user agent and version, type of computer or mobile device, computer connection, IP address, and the like. * /Device Information/: Includes name of the device, operating system, and browser you are using. Information collected may depend on the type of device you use and its settings. * /Cookies/: We use cookies to operate and administer our Services, and improve your experience on it. A “cookie” is a piece of information sent to your browser by a website you visit. You can set your browser to accept all cookies, to reject all cookies, or to notify you whenever a cookie is offered so that you can decide each time whether to accept it. However, refusing a cookie may in some cases preclude you from using, or negatively affect the display or function of, a website or certain areas or features of a website. For more details on cookies please visit All About Cookies <https://allaboutcookies.org/>. * /Analytics/: We may use a variety of online analytics products that use cookies to help us analyze how users use our Services and enhance your experience when you use the Services. 2. How we use personal information We may use Personal Information for the following purposes: * To provide, administer, maintain, improve and/or analyze the Services; * To conduct research; * To communicate with you; * To develop new programs and services; * To prevent fraud, criminal activity, or misuses of our Services, and to ensure the security of our IT systems, architecture, and networks; and * To comply with legal obligations and legal process and to protect our rights, privacy, safety, or property, and/or that of our affiliates, you, or other third parties. *Aggregated or De-Identified Information*. We may aggregate or de-identify Personal Information and use the aggregated information to analyze the effectiveness of our Services, to improve and add features to our Services, to conduct research and for other similar purposes. In addition, from time to time, we may analyze the general behavior and characteristics of users of our Services and share aggregated information like general user statistics with third parties, publish such aggregated information or make such aggregated information generally available. We may collect aggregated information through the Services, through cookies, and through other means described in this Privacy Policy. We will maintain and use de-identified information in anonymous or de-identified form and we will not attempt to reidentify the information. 3. Disclosure of personal information In certain circumstances we may provide your Personal Information to third parties without further notice to you, unless required by the law: * /Vendors and Service Providers/: To assist us in meeting business operations needs and to perform certain services and functions, we may provide Personal Information to vendors and service providers, including providers of hosting services, cloud services, and other information technology services providers, event management services, email communication software and email newsletter services, and web analytics services. Pursuant to our instructions, these parties will access, process, or store Personal Information only in the course of performing their duties to us. * /Business Transfers/: If we are involved in strategic transactions, reorganization, bankruptcy, receivership, or transition of service to another provider (collectively a “Transaction”), your Personal Information and other information may be disclosed in the diligence process with counterparties and others assisting with the Transaction and transferred to a successor or affiliate as part of that Transaction along with other assets. * /Legal Requirements/: If required to do so by law or in the good faith belief that such action is necessary to (i) comply with a legal obligation, including to meet national security or law enforcement requirements, (ii) protect and defend our rights or property, (iii) prevent fraud, (iv) act in urgent circumstances to protect the personal safety of users of the Services, or the public, or (v) protect against legal liability. * /Affiliates/: We may disclose Personal Information to our affiliates, meaning an entity that controls, is controlled by, or is under common control with OpenAI. Our affiliates may use the Personal Information we share in a manner consistent with this Privacy Policy. 4. Your rights Depending on location, individuals in the EEA, the UK, and across the globe may have certain statutory rights in relation to their Personal Information. For example, you may have the right to: * Access your Personal Information. * Delete your Personal Information. * Correct or update your Personal Information. * Transfer your Personal Information elsewhere. * Withdraw your consent to the processing of your Personal Information where we rely on consent as the legal basis for processing. * Object to or restrict the processing of your Personal Information where we rely on legitimate interests as the legal basis for processing. You can exercise some of these rights through your OpenAI account. If you are unable to exercise your rights through your account, please send us your request using this form <https://share.hsforms.com/1TJUvgl0BSHmoXh4HRBdsXA4sk30>. 5. California privacy rights The following table provides additional information about how we disclose Personal Information. You can read more about the Personal Information we collect in “Personal information we collect” above, how we use Personal information in “How we use personal information” above, and how we retain personal information in “Security and Retention” below. Category of Personal Information Disclosure of Personal Information Identifiers, such as your contact details We disclose this information to our affiliates, vendors and service providers, law enforcement, and parties involved in Transactions. Commercial Information, such as your transaction history We disclose this information to our affiliates, vendors and service providers, law enforcement, and parties involved in Transactions. Network Activity Information, such as Content and how you interact with our Services We disclose this information to our affiliates, vendors and service providers, law enforcement, and parties involved in Transactions. Geolocation Data We disclose this information to our affiliates, vendors and service providers, law enforcement, and parties involved in Transactions. Your account login credentials (Sensitive Personal Information) We disclose this information to our affiliates, vendors and service providers, law enforcement, and parties involved in Transactions. To the extent provided for by law and subject to applicable exceptions, California residents have the following privacy rights in relation to their Personal Information: * The right to know information about our processing of your Personal Information, including the specific pieces of Personal Information that we have collected from you; * The right to request deletion of your Personal Information; * The right to correct your Personal Information; and * The right to be free from discrimination relating to the exercise of any of your privacy rights. We don’t sell or share Personal Information as defined by the California Consumer Privacy Act, as amended by the California Privacy Rights Act. We also don’t process sensitive personal information for the purposes of inferring characteristics about a consumer. *Exercising Your Rights*. California residents can exercise their CCPA privacy rights by filling out this form <https://share.hsforms.com/1TJUvgl0BSHmoXh4HRBdsXA4sk30>. *Verification*. In order to protect your Personal Information from unauthorized access, change, or deletion, we may require you to verify your credentials before you can submit a request to know, correct, or delete Personal Information. If you do not have an account with us, or if we suspect fraudulent or malicious activity, we may ask you to provide additional Personal Information and proof of residency for verification. If we cannot verify your identity, we will not provide, correct, or delete your Personal Information. *Authorized Agents*. you may submit a rights request through an authorized agent. If you do so, the agent must present signed written permission to act on your behalf and you may also be required to independently verify your identity and submit proof of your residency with us. Authorized agent requests can be submitted using this form <https://share.hsforms.com/1TJUvgl0BSHmoXh4HRBdsXA4sk30>. 6. Children Our Service is not directed to children who are under the age of 13. OpenAI does not knowingly collect Personal Information from children under the age of 13. If you have reason to believe that a child under the age of 13 has provided Personal Information to OpenAI through the Service please email us at legal@openai.com. We will investigate any notification and if appropriate, delete the Personal Information from our systems. 7. Links to other websites The Service may contain links to other websites not operated or controlled by OpenAI, including social media services (“Third Party Sites”). The information that you share with Third Party Sites will be governed by the specific privacy policies and terms of service of the Third Party Sites and not by this Privacy Policy. By providing these links we do not imply that we endorse or have reviewed these sites. Please contact the Third Party Sites directly for information on their privacy practices and policies. 8. Security and Retention We implement commercially reasonable technical, administrative, and organizational measures to protect Personal Information both online and offline from loss, misuse, and unauthorized access, disclosure, alteration, or destruction. However, no Internet or email transmission is ever fully secure or error free. In particular, email sent to or from us may not be secure. Therefore, you should take special care in deciding what information you send to us via the Service or email. In addition, we are not responsible for circumvention of any privacy settings or security measures contained on the Service, or third party websites. We’ll retain your Personal Information for only as long as we need in order to provide our Service to you, or for other legitimate business purposes such as resolving disputes, safety and security reasons, or complying with our legal obligations. How long we retain Personal Information will depend on a number of factors, such as the amount, nature, and sensitivity of the information, the potential risk of harm from unauthorized use or disclosure, our purpose for processing the information, and any legal requirements. We may also anonymize or de-identify your Personal Information (so that it can no longer be associated with you) for research or statistical purposes, as described above, in which case we may use this information indefinitely without further notice to you. 9. International users By using our Service, you understand and acknowledge that your Personal Information will be transferred from your location to our facilities and servers in the United States. For EEA, UK or Swiss users: *Legal Basis for Processing*. Our legal bases for processing your Personal Information include: * Performance of a contract with you when we provide, maintain, and improve our Services. This may include the processing of Account Information, Content, and Technical Information. * Our legitimate interests in protecting our Services from abuse, fraud, or security risks, or when we develop, improve, or promote our Services. This may include the processing of Account Information, Content, Social Information, and Technical Information. * Your consent when we ask for your consent to process your Personal Information for a specific purpose that we communicate to you. You have the right to withdraw your consent at any time. * Compliance with our legal obligations when we use your Personal Information to comply with applicable law or when we protect our or our affiliates’ or users’ rights, safety and property. *EEA and UK Representative*/. /We’ve appointed VeraSafe as our representative in the EEA and UK for data protection matters. You can contact VeraSafe in matters related to Personal Information processing using this contact form <https://verasafe.com/public-resources/contact-data-protection-representative>. Alternatively: * For users in the EEA, you can contact VeraSafe at VeraSafe Ireland Ltd, Unit 3D North Point House, North Point Business Park, New Mallow Road, Cork T23AT2P, Ireland. * For users in the UK, you can contact VeraSafe at VeraSafe United Kingdom Ltd., 37 Albert Embankment, London SE1 7TL, United Kingdom. If you feel we have not adequately addressed an issue, you have the right to lodge a complaint with your local supervisory authority. *Data Transfers*/. /Where required, we will use appropriate safeguards for transferring Personal Information outside of the EEA, Switzerland, and the UK.//We will only transfer Personal Information pursuant to a legally valid transfer mechanism. *Data Controller*/. /For the purposes of the UK and EU General Data Protection Regulation 2018, our data controller is OpenAI, L.L.C at 3180 18th Street, San Francisco, CA, United States. 10. Your choices If you choose not to provide Personal Information that is needed to use some features of our Service, you may be unable to use those features. 11. Changes to the privacy policy We may change this Privacy Policy at any time. When we do, we will post an updated version on this page, unless another type of notice is required by applicable law. By continuing to use our Service or providing us with Personal Information after we have posted an updated Privacy Policy, or notified you by other means, you consent to the revised Privacy Policy. 12. How to contact us Please contact support <https://help.openai.com/en/articles/6614161-how-can-i-contact-support#:~:tex...> if you have any questions or concerns not already addressed in this Privacy Policy. <https://openai.com/>On 01/04/23 09:34, Paolo Del Romano wrote:
https://ultimora.net/2023/03/31/guida-come-aggirare-il-blocco-di-chat-gpt-in...
vedo che dobbiamo cominciare a usare le VPN anche in Italia come accade in Cina, Russia, Turchia....
Paolo Del Romano
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== --

a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Purtroppo anche il web contiene molte informazioni false, il tutto amplificato da algoritmi predittivi che portano a risultati diversi ad ognuno di noi, senza parlare di echo chambers o di epistemic bubbles...
Tra l'altro, ieri, appena successo, una persona "normale" (nel senso di una persona non tecnica - ma speciale per me) mi scrive: "io non ci rinuncio!" Installa un VPN e voilà è di nuovo connessa al servizio di ChatGPT dall'Italia. Ma è davvero così facile aggirare un blocco? E' legale usare un VPN? Insomma la cosa è fuori controllo davvero, in tutti i sensi. E dal momento che la questione è sempre più etica, legata ad un uso libero ma critico, consapevole e responsabile di strumenti digitali, lo sviluppo delle competenze digitali delle persone sembra l'unica soluzione che possa funzionare. Sarebbe bello lavorare su questo in lista, insieme. Alessandro On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote:
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

Sulla vicenda Garante/ChatGPT e gli echi berlusconiani della strategia della serrata per far pressione sul legislatore segnalo un post in inglese che ho appena pubblicato sul mio sito. https://www.casilli.fr/2023/04/01/chatgpt-and-data-privacy-a-very-italian-st... ----- Original Message ----- From: "Alessandro Brolpito" <abrolpito@gmail.com> To: "Enrico Nardelli" <nardelli@mat.uniroma2.it> Cc: "nexa" <nexa@server-nexa.polito.it> Sent: Saturday, April 1, 2023 11:54:35 AM Subject: Re: [nexa] ChatGPT disabled for users in Italy
a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Purtroppo anche il web contiene molte informazioni false, il tutto amplificato da algoritmi predittivi che portano a risultati diversi ad ognuno di noi, senza parlare di echo chambers o di epistemic bubbles...
Tra l'altro, ieri, appena successo, una persona "normale" (nel senso di una persona non tecnica - ma speciale per me) mi scrive: "io non ci rinuncio!" Installa un VPN e voilà è di nuovo connessa al servizio di ChatGPT dall'Italia. Ma è davvero così facile aggirare un blocco? E' legale usare un VPN? Insomma la cosa è fuori controllo davvero, in tutti i sensi. E dal momento che la questione è sempre più etica, legata ad un uso libero ma critico, consapevole e responsabile di strumenti digitali, lo sviluppo delle competenze digitali delle persone sembra l'unica soluzione che possa funzionare. Sarebbe bello lavorare su questo in lista, insieme. Alessandro On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli < [ mailto:nardelli@mat.uniroma2.it | nardelli@mat.uniroma2.it ] > wrote: A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( [ https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... | https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... ] ) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN [ https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html | https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ] ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: [ https://www.mat.uniroma2.it/~nardelli | https://www.mat.uniroma2.it/~nardelli ] blog: [ https://link-and-think.blogspot.it/ | https://link-and-think.blogspot.it/ ] tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: [ mailto:nardelli@mat.uniroma2.it | nardelli@mat.uniroma2.it ] online meeting: [ https://blue.meet.garr.it/b/enr-y7f-t0q-ont | https://blue.meet.garr.it/b/enr-y7f-t0q-ont ] ====================================================== -- _______________________________________________ nexa mailing list [ mailto:nexa@server-nexa.polito.it | nexa@server-nexa.polito.it ] [ https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa | https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa ] _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento. Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee. Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia. Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana. Siamo pertanto di fronte a una drammatizzazione. L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico. OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia. Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie. G. On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote:
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

Leggo sul sito del Garante il testo del provvedimento: OpenAI, che non ha una sede nell’Unione ma ha designato un rappresentante nello Spazio economico europeo, deve comunicare entro 20 giorni le misure intraprese in attuazione di quanto richiesto dal Garante, pena una sanzione fino a 20 milioni di euro o fino al 4% del fatturato globale annuo. Non è una drammatizzazione, ma un provvedimento coerente con i rilievi formulati e in linea con altri provvedimenti emanati dal Garante. Entro 20 giorni Open AI deve comunicare quali misure intende adottare per eliminare le cause dei rilievi formulati. Non attuare le misure, che possono richiedere tempo, ma solo comunicarle al Garante. Non comprendo proprio perché con questa decisione: ‘lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.’ Al contrario mi sembra che l’Autorita’ di garanzia, organo dello Stato, ma non del governo, cerchi di svolgere il suo compito di tutela dei cittadini, provando a rendere meno infrequentabile uno spazio pubblico colonizzato da imprese private digitali. A meno di eccepire sul merito dei rilievi del Garante, o di contestare le regole che il Garante ha l’obbligo (non la discrezione) di attuare, la questione politica evidente è quella della enorme sproporzione di potere tra gli organismi pubblici nazionali che hanno il compito di attuare le regole decise in sede politica e le grandi imprese digitali alle quali quelle regole sono destinate. Il richiamo che fa Antonio Casilli ad un altro momento della recente storia italiana mi sembra efficace e pertinente. G. Il giorno sab 1 apr 2023 alle 12:05 Guido Vetere <vetere.guido@gmail.com> ha scritto:
Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento.
Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee.
Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia.
Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana.
Siamo pertanto di fronte a una drammatizzazione.
L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.
OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia.
Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie.
G.
On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote:
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

Provo a proporvi alcune considerazioni in diritto, giusto per tentare di dare un contributo, per quel che posso, nell'interpretare un provvedimento che mi lascia molto perplesso. 1) Il provvedimento è un provvedimento connotato da “particolare urgenza ed indifferibilità” tanto da non consentire neppure la convocazione in tempo utile del Garante, ovvero del Collegio dei Garanti, ed è firmato ed adottato dal solo Presidente. Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. Non è una buona partenza e la cosa si presta a polemiche più o meno strumentali. 2) E’ un provvedimento di *limitazione provvisoria del trattamento *dei dati personali delle persone che si trovano nel territorio italiano (a prescindere da cittadinanza o residenza) e la predetta limitazione *ha effetto immediato a decorrere dalla data di ricezione* del provvedimento. Dunque dal 31/03/2023. C’è poi una seconda imposizione che assegna 20 giorni per comunicare quali iniziative siano state intraprese al fine di dare attuazione a quanto prescritto, ovvero l’immediata limitazione del trattamento (io non leggo altre prescrizioni), e per fornire ogni elemento ritenuto utile a giustificare le violazioni evidenziate. Violazioni per cui sussiste un *fumus boni juris* e che saranno oggetto di futura istruttoria. Non sono stati concessi 20 giorni per conformarsi al GDPR, ma 20 giorni per spiegare cosa hanno immediatamente fatto in relazione al provvedimento. 3) Prima di affrontare il tema centrale su cosa si intenda per “limitazione del trattamento” è opportuno precisare quali profili di illiceità individui il provvedimento. Mi paiono 4, ma non sono sicuro: i) l’assenza di informativa (che invece c’è); ii l’assenza di base giuridica nel trattamento dei dati personali nei grandi dataset di addestramento (tema amplissimo che incide su tutti i sistemi di ML e non solo); iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso) ed in ultimo iv) il problema dell'accesso dei minori. 4) Ora, tralasciando le molte considerazioni in diritto che potrebbero farsi su queste più o meno provate violazioni, ed a prescindere dalla loro fondatezza, è necessario capire cosa è una “limitazione del trattamento”. E’ fondamentale credo per capire la reale portata del provvedimento emesso dal Presidente del Garante e quali opzioni avesse OpenAI al di là di quella, piuttosto semplice, di fregarsene del provvedimento non essendo stabilita in EU e non essendo pensabile alcuna capacità esecutiva o impositiva da parte dell’Autorità Italiana, soprattutto al di fuori di qualsiasi coordinamento con le omologhe Autority europee, efficace quanto meno a livello di pressione politica. Purtroppo ancora una volta il provvedimento non aiuta a capire quale limitazione il provider avrebbe dovuto applicare, a quali dati in concreto e a quali specifici trattamenti; in un sistema in cui probabilmente manco OpenAi sa granularmente cosa c’è e cosa accade, non mi pare facile “adempiere” all’ordine immediato... Sul punto può aiutare il Considerando 67 del GDPR ove si legge: N*egli archivi automatizzati, la limitazione del trattamento dei dati personali dovrebbe in linea di massima essere assicurata mediante dispositivi tecnici in modo tale che i dati personali non siano sottoposti a ulteriori trattamenti e non possano più essere modificati. Il sistema dovrebbe indicare chiaramente che il trattamento dei dati personali è stato limitato.* Gli informatici della lista mi aiuteranno a capire come si applica una limitazione del trattamento sui dati personali di interessati stabiliti in Italia in una rete quale quella utilizzata da ChatGpt. Mi chiedo ad esempio come nell’ampio data-set formato dagli archivi delle principali testate giornalistiche statunitensi (uno negli n° data set dichiarati) possano esser individuati, contrassegnati e bloccati i soli dati delle persone, non italiane, ma stabilite in Italia. Il provvedimento credo implicherebbe il blocco dell’intera rete, ma sul punto gli informatici mi aiuteranno. Io non saprei che fare. Ma al di là dei dati già archiviati, OpenAI dal 31/03/2023 non può ovviamente trattare, e dunque acquisire, dati di interessati stabiliti in Italia. Sarebbe singolare non applicare una generica limitazione all’acquisizione. Bloccare l’accesso dall’italia, a fronte di un provvedimento così generico è la prima soluzione che io suggerirei al provider ed è temo l’unica cosa che si può fare senza bloccare l’intero servizio worldwide. *Quel provvedimento d’urgenza non chiede adeguamenti al GDPR o la messa in conformità: individua e ipotizza alcune possibili violazioni e opera cautelativamente la limitazione di alcuni dati personali (quelli delle persone che si trovano nel territorio italiano), alla data 31/03/2023. Punto.* Le critiche al blocco operato da OpenAI ieri mi pare possano avere una loro fondatezza solo se rapportate alla scelta, del tutto legittima, tra due opzioni: fregarsene del provvedimento oppure in qualche modo adempiere nell’unico modo possibile: bloccare l’Italia. E probabilmente per sfruttare l’abnormità del provvedimento e sollevare un caso OpenAI ha scelto la seconda. Concordo con Casilli: ci sono analogie con la vicenda Berlusconi degli anni ‘80. Anche in quel caso una legge inadeguata ed inattuale (e incompatibile con l’art.21 Cost) si scontrava con una evoluzione tecnologica che ne palesava l’assoluta iniquità. La mossa di Berlusconi fu una forzatura del tutto legittima, e fu scelta efficace. I benefici in termini pluralismo nel settore dei media ed i danni e i disastri della televisione commerciale sono poi un’altro capitolo della storia. Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo: il tema mi pare davvero non meriti di esser affrontata dagli enti regolatori italiani con provvedimenti d’urgenza inutili, inefficaci e forieri di danno per l’Italia. Purtroppo l’andazzo è questo, non solo nell’approccio alle questioni tecnologiche a noi care. Buona domenica Carlo Il giorno sab 1 apr 2023 alle ore 16:38 de petra giulio < giulio.depetra@gmail.com> ha scritto:
Leggo sul sito del Garante il testo del provvedimento:
OpenAI, che non ha una sede nell’Unione ma ha designato un rappresentante nello Spazio economico europeo, deve comunicare entro 20 giorni le misure intraprese in attuazione di quanto richiesto dal Garante, pena una sanzione fino a 20 milioni di euro o fino al 4% del fatturato globale annuo.
Non è una drammatizzazione, ma un provvedimento coerente con i rilievi formulati e in linea con altri provvedimenti emanati dal Garante. Entro 20 giorni Open AI deve comunicare quali misure intende adottare per eliminare le cause dei rilievi formulati. Non attuare le misure, che possono richiedere tempo, ma solo comunicarle al Garante.
Non comprendo proprio perché con questa decisione: ‘lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.’ Al contrario mi sembra che l’Autorita’ di garanzia, organo dello Stato, ma non del governo, cerchi di svolgere il suo compito di tutela dei cittadini, provando a rendere meno infrequentabile uno spazio pubblico colonizzato da imprese private digitali.
A meno di eccepire sul merito dei rilievi del Garante, o di contestare le regole che il Garante ha l’obbligo (non la discrezione) di attuare, la questione politica evidente è quella della enorme sproporzione di potere tra gli organismi pubblici nazionali che hanno il compito di attuare le regole decise in sede politica e le grandi imprese digitali alle quali quelle regole sono destinate.
Il richiamo che fa Antonio Casilli ad un altro momento della recente storia italiana mi sembra efficace e pertinente.
G.
Il giorno sab 1 apr 2023 alle 12:05 Guido Vetere <vetere.guido@gmail.com> ha scritto:
Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento.
Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee.
Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia.
Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana.
Siamo pertanto di fronte a una drammatizzazione.
L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.
OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia.
Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie.
G.
On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote:
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
-- *Avv. Carlo Blengino* *Via Duchessa Jolanda n. 19,* *10138 Torino (TO) - Italy* *tel. +39 011 4474035* Penalistiassociati.it
Ottima analisi Carlo! Mi ravvedo su certi punti e su altri conto sviluppare. Grazie 🙏—-a -----Original Message----- From: Carlo <blengino@penalistiassociati.it> To: de <giulio.depetra@gmail.com>; Enrico <nardelli@mat.uniroma2.it> Cc: nexa <nexa@server-nexa.polito.it> Date: Sunday, 2 April 2023 9:12 AM CEST Subject: Re: [nexa] ChatGPT disabled for users in Italy Provo a proporvi alcune considerazioni in diritto, giusto per tentare di dare un contributo, per quel che posso, nell'interpretare un provvedimento che mi lascia molto perplesso. 1) Il provvedimento è un provvedimento connotato da “particolare urgenza ed indifferibilità” tanto da non consentire neppure la convocazione in tempo utile del Garante, ovvero del Collegio dei Garanti, ed è firmato ed adottato dal solo Presidente. Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. Non è una buona partenza e la cosa si presta a polemiche più o meno strumentali. 2) E’ un provvedimento di limitazione provvisoria del trattamento dei dati personali delle persone che si trovano nel territorio italiano (a prescindere da cittadinanza o residenza) e la predetta limitazione ha effetto immediato a decorrere dalla data di ricezione del provvedimento. Dunque dal 31/03/2023. C’è poi una seconda imposizione che assegna 20 giorni per comunicare quali iniziative siano state intraprese al fine di dare attuazione a quanto prescritto, ovvero l’immediata limitazione del trattamento (io non leggo altre prescrizioni), e per fornire ogni elemento ritenuto utile a giustificare le violazioni evidenziate. Violazioni per cui sussiste un fumus boni juris e che saranno oggetto di futura istruttoria. Non sono stati concessi 20 giorni per conformarsi al GDPR, ma 20 giorni per spiegare cosa hanno immediatamente fatto in relazione al provvedimento. 3) Prima di affrontare il tema centrale su cosa si intenda per “limitazione del trattamento” è opportuno precisare quali profili di illiceità individui il provvedimento. Mi paiono 4, ma non sono sicuro: i) l’assenza di informativa (che invece c’è); ii l’assenza di base giuridica nel trattamento dei dati personali nei grandi dataset di addestramento (tema amplissimo che incide su tutti i sistemi di ML e non solo); iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso) ed in ultimo iv) il problema dell'accesso dei minori. 4) Ora, tralasciando le molte considerazioni in diritto che potrebbero farsi su queste più o meno provate violazioni, ed a prescindere dalla loro fondatezza, è necessario capire cosa è una “limitazione del trattamento”. E’ fondamentale credo per capire la reale portata del provvedimento emesso dal Presidente del Garante e quali opzioni avesse OpenAI al di là di quella, piuttosto semplice, di fregarsene del provvedimento non essendo stabilita in EU e non essendo pensabile alcuna capacità esecutiva o impositiva da parte dell’Autorità Italiana, soprattutto al di fuori di qualsiasi coordinamento con le omologhe Autority europee, efficace quanto meno a livello di pressione politica. Purtroppo ancora una volta il provvedimento non aiuta a capire quale limitazione il provider avrebbe dovuto applicare, a quali dati in concreto e a quali specifici trattamenti; in un sistema in cui probabilmente manco OpenAi sa granularmente cosa c’è e cosa accade, non mi pare facile “adempiere” all’ordine immediato... Sul punto può aiutare il Considerando 67 del GDPR ove si legge: Negli archivi automatizzati, la limitazione del trattamento dei dati personali dovrebbe in linea di massima essere assicurata mediante dispositivi tecnici in modo tale che i dati personali non siano sottoposti a ulteriori trattamenti e non possano più essere modificati. Il sistema dovrebbe indicare chiaramente che il trattamento dei dati personali è stato limitato. Gli informatici della lista mi aiuteranno a capire come si applica una limitazione del trattamento sui dati personali di interessati stabiliti in Italia in una rete quale quella utilizzata da ChatGpt. Mi chiedo ad esempio come nell’ampio data-set formato dagli archivi delle principali testate giornalistiche statunitensi (uno negli n° data set dichiarati) possano esser individuati, contrassegnati e bloccati i soli dati delle persone, non italiane, ma stabilite in Italia. Il provvedimento credo implicherebbe il blocco dell’intera rete, ma sul punto gli informatici mi aiuteranno. Io non saprei che fare. Ma al di là dei dati già archiviati, OpenAI dal 31/03/2023 non può ovviamente trattare, e dunque acquisire, dati di interessati stabiliti in Italia. Sarebbe singolare non applicare una generica limitazione all’acquisizione. Bloccare l’accesso dall’italia, a fronte di un provvedimento così generico è la prima soluzione che io suggerirei al provider ed è temo l’unica cosa che si può fare senza bloccare l’intero servizio worldwide. Quel provvedimento d’urgenza non chiede adeguamenti al GDPR o la messa in conformità: individua e ipotizza alcune possibili violazioni e opera cautelativamente la limitazione di alcuni dati personali (quelli delle persone che si trovano nel territorio italiano), alla data 31/03/2023. Punto. Le critiche al blocco operato da OpenAI ieri mi pare possano avere una loro fondatezza solo se rapportate alla scelta, del tutto legittima, tra due opzioni: fregarsene del provvedimento oppure in qualche modo adempiere nell’unico modo possibile: bloccare l’Italia. E probabilmente per sfruttare l’abnormità del provvedimento e sollevare un caso OpenAI ha scelto la seconda. Concordo con Casilli: ci sono analogie con la vicenda Berlusconi degli anni ‘80. Anche in quel caso una legge inadeguata ed inattuale (e incompatibile con l’art.21 Cost) si scontrava con una evoluzione tecnologica che ne palesava l’assoluta iniquità. La mossa di Berlusconi fu una forzatura del tutto legittima, e fu scelta efficace. I benefici in termini pluralismo nel settore dei media ed i danni e i disastri della televisione commerciale sono poi un’altro capitolo della storia. Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo: il tema mi pare davvero non meriti di esser affrontata dagli enti regolatori italiani con provvedimenti d’urgenza inutili, inefficaci e forieri di danno per l’Italia. Purtroppo l’andazzo è questo, non solo nell’approccio alle questioni tecnologiche a noi care. Buona domenica Carlo Il giorno sab 1 apr 2023 alle ore 16:38 de petra giulio <giulio.depetra@gmail.com> ha scritto: Leggo sul sito del Garante il testo del provvedimento: OpenAI, che non ha una sede nell’Unione ma ha designato un rappresentante nello Spazio economico europeo, deve comunicare entro 20 giorni le misure intraprese in attuazione di quanto richiesto dal Garante, pena una sanzione fino a 20 milioni di euro o fino al 4% del fatturato globale annuo. Non è una drammatizzazione, ma un provvedimento coerente con i rilievi formulati e in linea con altri provvedimenti emanati dal Garante. Entro 20 giorni Open AI deve comunicare quali misure intende adottare per eliminare le cause dei rilievi formulati. Non attuare le misure, che possono richiedere tempo, ma solo comunicarle al Garante. Non comprendo proprio perché con questa decisione: ‘lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.’ Al contrario mi sembra che l’Autorita’ di garanzia, organo dello Stato, ma non del governo, cerchi di svolgere il suo compito di tutela dei cittadini, provando a rendere meno infrequentabile uno spazio pubblico colonizzato da imprese private digitali. A meno di eccepire sul merito dei rilievi del Garante, o di contestare le regole che il Garante ha l’obbligo (non la discrezione) di attuare, la questione politica evidente è quella della enorme sproporzione di potere tra gli organismi pubblici nazionali che hanno il compito di attuare le regole decise in sede politica e le grandi imprese digitali alle quali quelle regole sono destinate. Il richiamo che fa Antonio Casilli ad un altro momento della recente storia italiana mi sembra efficace e pertinente. G. Il giorno sab 1 apr 2023 alle 12:05 Guido Vetere <vetere.guido@gmail.com> ha scritto: Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento. Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee. Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia. Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana. Siamo pertanto di fronte a una drammatizzazione. L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico. OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia. Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie. G. On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote: A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa -- Avv. Carlo Blengino Via Duchessa Jolanda n. 19,10138 Torino (TO) - Italy tel. +39 011 4474035 Penalistiassociati.it
Mi sembra un contributo utilissimo, grazie! Il Dom 2 Apr 2023, 09:44 Antonio Casilli <antonio.casilli@telecom-paris.fr> ha scritto:
Ottima analisi Carlo! Mi ravvedo su certi punti e su altri conto sviluppare. Grazie 🙏—-a
------------------------------ *From: *Carlo <blengino@penalistiassociati.it> *To: *de <giulio.depetra@gmail.com>; Enrico <nardelli@mat.uniroma2.it> *Cc: *nexa <nexa@server-nexa.polito.it> *Date: *Sunday, 2 April 2023 9:12 AM CEST *Subject: *Re: [nexa] ChatGPT disabled for users in Italy
Provo a proporvi alcune considerazioni in diritto, giusto per tentare di dare un contributo, per quel che posso, nell'interpretare un provvedimento che mi lascia molto perplesso.
1) Il provvedimento è un provvedimento connotato da “particolare urgenza ed indifferibilità” tanto da non consentire neppure la convocazione in tempo utile del Garante, ovvero del Collegio dei Garanti, ed è firmato ed adottato dal solo Presidente. Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. Non è una buona partenza e la cosa si presta a polemiche più o meno strumentali.
2) E’ un provvedimento di *limitazione provvisoria del trattamento *dei dati personali delle persone che si trovano nel territorio italiano (a prescindere da cittadinanza o residenza) e la predetta limitazione *ha effetto immediato a decorrere dalla data di ricezione* del provvedimento. Dunque dal 31/03/2023.
C’è poi una seconda imposizione che assegna 20 giorni per comunicare quali iniziative siano state intraprese al fine di dare attuazione a quanto prescritto, ovvero l’immediata limitazione del trattamento (io non leggo altre prescrizioni), e per fornire ogni elemento ritenuto utile a giustificare le violazioni evidenziate. Violazioni per cui sussiste un *fumus boni juris* e che saranno oggetto di futura istruttoria.
Non sono stati concessi 20 giorni per conformarsi al GDPR, ma 20 giorni per spiegare cosa hanno immediatamente fatto in relazione al provvedimento.
3) Prima di affrontare il tema centrale su cosa si intenda per “limitazione del trattamento” è opportuno precisare quali profili di illiceità individui il provvedimento. Mi paiono 4, ma non sono sicuro: i) l’assenza di informativa (che invece c’è); ii l’assenza di base giuridica nel trattamento dei dati personali nei grandi dataset di addestramento (tema amplissimo che incide su tutti i sistemi di ML e non solo); iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso) ed in ultimo iv) il problema dell'accesso dei minori.
4) Ora, tralasciando le molte considerazioni in diritto che potrebbero farsi su queste più o meno provate violazioni, ed a prescindere dalla loro fondatezza, è necessario capire cosa è una “limitazione del trattamento”. E’ fondamentale credo per capire la reale portata del provvedimento emesso dal Presidente del Garante e quali opzioni avesse OpenAI al di là di quella, piuttosto semplice, di fregarsene del provvedimento non essendo stabilita in EU e non essendo pensabile alcuna capacità esecutiva o impositiva da parte dell’Autorità Italiana, soprattutto al di fuori di qualsiasi coordinamento con le omologhe Autority europee, efficace quanto meno a livello di pressione politica.
Purtroppo ancora una volta il provvedimento non aiuta a capire quale limitazione il provider avrebbe dovuto applicare, a quali dati in concreto e a quali specifici trattamenti; in un sistema in cui probabilmente manco OpenAi sa granularmente cosa c’è e cosa accade, non mi pare facile “adempiere” all’ordine immediato...
Sul punto può aiutare il Considerando 67 del GDPR ove si legge: N*egli archivi automatizzati, la limitazione del trattamento dei dati personali dovrebbe in linea di massima essere assicurata mediante dispositivi tecnici in modo tale che i dati personali non siano sottoposti a ulteriori trattamenti e non possano più essere modificati. Il sistema dovrebbe indicare chiaramente che il trattamento dei dati personali è stato limitato.*
Gli informatici della lista mi aiuteranno a capire come si applica una limitazione del trattamento sui dati personali di interessati stabiliti in Italia in una rete quale quella utilizzata da ChatGpt. Mi chiedo ad esempio come nell’ampio data-set formato dagli archivi delle principali testate giornalistiche statunitensi (uno negli n° data set dichiarati) possano esser individuati, contrassegnati e bloccati i soli dati delle persone, non italiane, ma stabilite in Italia. Il provvedimento credo implicherebbe il blocco dell’intera rete, ma sul punto gli informatici mi aiuteranno. Io non saprei che fare.
Ma al di là dei dati già archiviati, OpenAI dal 31/03/2023 non può ovviamente trattare, e dunque acquisire, dati di interessati stabiliti in Italia. Sarebbe singolare non applicare una generica limitazione all’acquisizione.
Bloccare l’accesso dall’italia, a fronte di un provvedimento così generico è la prima soluzione che io suggerirei al provider ed è temo l’unica cosa che si può fare senza bloccare l’intero servizio worldwide.
*Quel provvedimento d’urgenza non chiede adeguamenti al GDPR o la messa in conformità: individua e ipotizza alcune possibili violazioni e opera cautelativamente la limitazione di alcuni dati personali (quelli delle persone che si trovano nel territorio italiano), alla data 31/03/2023. Punto.*
Le critiche al blocco operato da OpenAI ieri mi pare possano avere una loro fondatezza solo se rapportate alla scelta, del tutto legittima, tra due opzioni: fregarsene del provvedimento oppure in qualche modo adempiere nell’unico modo possibile: bloccare l’Italia. E probabilmente per sfruttare l’abnormità del provvedimento e sollevare un caso OpenAI ha scelto la seconda.
Concordo con Casilli: ci sono analogie con la vicenda Berlusconi degli anni ‘80. Anche in quel caso una legge inadeguata ed inattuale (e incompatibile con l’art.21 Cost) si scontrava con una evoluzione tecnologica che ne palesava l’assoluta iniquità. La mossa di Berlusconi fu una forzatura del tutto legittima, e fu scelta efficace. I benefici in termini pluralismo nel settore dei media ed i danni e i disastri della televisione commerciale sono poi un’altro capitolo della storia.
Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo: il tema mi pare davvero non meriti di esser affrontata dagli enti regolatori italiani con provvedimenti d’urgenza inutili, inefficaci e forieri di danno per l’Italia. Purtroppo l’andazzo è questo, non solo nell’approccio alle questioni tecnologiche a noi care.
Buona domenica
Carlo
Il giorno sab 1 apr 2023 alle ore 16:38 de petra giulio < giulio.depetra@gmail.com> ha scritto:
Leggo sul sito del Garante il testo del provvedimento:
OpenAI, che non ha una sede nell’Unione ma ha designato un rappresentante nello Spazio economico europeo, deve comunicare entro 20 giorni le misure intraprese in attuazione di quanto richiesto dal Garante, pena una sanzione fino a 20 milioni di euro o fino al 4% del fatturato globale annuo.
Non è una drammatizzazione, ma un provvedimento coerente con i rilievi formulati e in linea con altri provvedimenti emanati dal Garante. Entro 20 giorni Open AI deve comunicare quali misure intende adottare per eliminare le cause dei rilievi formulati. Non attuare le misure, che possono richiedere tempo, ma solo comunicarle al Garante.
Non comprendo proprio perché con questa decisione: ‘lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.’ Al contrario mi sembra che l’Autorita’ di garanzia, organo dello Stato, ma non del governo, cerchi di svolgere il suo compito di tutela dei cittadini, provando a rendere meno infrequentabile uno spazio pubblico colonizzato da imprese private digitali.
A meno di eccepire sul merito dei rilievi del Garante, o di contestare le regole che il Garante ha l’obbligo (non la discrezione) di attuare, la questione politica evidente è quella della enorme sproporzione di potere tra gli organismi pubblici nazionali che hanno il compito di attuare le regole decise in sede politica e le grandi imprese digitali alle quali quelle regole sono destinate.
Il richiamo che fa Antonio Casilli ad un altro momento della recente storia italiana mi sembra efficace e pertinente.
G.
Il giorno sab 1 apr 2023 alle 12:05 Guido Vetere <vetere.guido@gmail.com> ha scritto:
Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento.
Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee.
Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia.
Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana.
Siamo pertanto di fronte a una drammatizzazione.
L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.
OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia.
Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie.
G.
On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote:
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 <+39%2006%207259.4204> fax: +39 06 7259.4699 <+39%2006%207259.4699> mobile: +39 335 590.2331 <+39%20335%20590.2331> e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
-- *Avv. Carlo Blengino*
*Via Duchessa Jolanda n. 19,* *10138 Torino (TO) - Italy* *tel. +39 011 4474035 <+39%20011%204474035>* Penalistiassociati.it
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

ringrazio davvero molto Carlo, che mette in fila una serie di argomenti e di considerazioni che mi trovo a condividere. Vorrei fare una sottolineatura: già nelle parole di Carlo ci sono le tracce di una impianto normativo (quello del GDPR) che mostrava già al momento della sua formale adozione (parliamo del 2016) molti limiti in termini di adeguatezza regolativa rispetto ai fenomeni (già allora) in essere. Da allora le cose, evidentemente, sono molto peggiorate (sempre in termini di adeguatezza regolativa). E, tuttavia, il GDPR offre molte munizioni se si volesse approcciare alla regolazione dei trattamenti dei dati personali, anche con riferimento alle cd. intelligenze artificiali. Quello che noto, però, è che, per un verso, in sede UE ci si è imbarcati nella elaborazione di una disciplina specifica "ad hoc" - il regolamento AI - per altro non pefettamente coordinata con la disciplina GDPR e che presenta già molti profili di perplessità/inadeguatezza (per fare solo un esempio, il più immediato rispetto al nostor tema: non avevano previsto il caso delle chatbot!). Dall'altra parte, la regolamentazione che invece c'è (il GDPR) presenta sì molte inadeguatezze, ma soprattutto mostra - sul piano della governance - un assetto (ancora) estremamente frammetato che comporta tempi e modalità di intervento farraginosi e (a volte) barocchi. C'è un tema di fondo (quanta capacità decisionale si è voluto trattenere in sede nazionale), che è un nodo gordiano. C'è un tema connesso al modello della tutela di diritti fondamentali basata su tante autorità indipendenti quanti sono i paesi membri (non sto criticando l'istituto, sto sottolineando che non è affatto detto che 27 autorità nazionali indipendenti siano capaci di coordinarsi adeguatamente; né è dimostrato che siano capaci di farlo meglio di 27 governi, per intenderci). Per arrivare ad affermare che Meta (in riferimento ai servizi di Facebook e Instagram) tratta i dati degli utenti (e anche di terzi non utenti) in modo che non corrisponde alle basi giuridiche legittimanti previste nel GDPR (in base ad una causa intentata il giorno stesso che il GDPR è entrato in vigore, cioè nel maggio del 2018), ed irrogare una (sostanziosa) multa, _ci sono voluti quasi 5 anni_ (e adesso ci sarà tutta la trafila dei ricorsi giurisdizionali)! Senza contare la diversità di vedute mostrata dalle autorità di garanzia nazionali, e che pare riproporsi anche in sede giurisdizionale (vedi le recenti sentenze olandesi relative ai terms of service come base contrattuale dei trattamenti). Insomma, il tanto decantato "brussel effect" mi pare che debba fare i conti con una governance ed una capacità di enforcement che non sono all'altezza degli obiettivi (e dell'ambiente in cui si deve operare). La scelta, un po' estemporanea e in effetti abbastanza "oscura" nelle sue motivazioni, del Garante italiano, mi pare un sintomo di questa situazione complessiva. (mi associo sempre a Carlo nei ringraziamento per il privilegio di poter fruire di questo spazio di discussione). Benedetto Il 02/04/2023 09:12, Carlo Blengino ha scritto:
Provo a proporvi alcune considerazioni in diritto, giusto per tentare di dare un contributo, per quel che posso, nell'interpretare un provvedimento che mi lascia molto perplesso.
1) Il provvedimento è un provvedimento connotato da “particolare urgenza ed indifferibilità” tanto da non consentire neppure la convocazione in tempo utile del Garante, ovvero del Collegio dei Garanti, ed è firmato ed adottato dal solo Presidente. Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. Non è una buona partenza e la cosa si presta a polemiche più o meno strumentali.
2) E’ un provvedimento di _limitazione provvisoria del trattamento _dei dati personali delle persone che si trovano nel territorio italiano (a prescindere da cittadinanza oresidenza) e la predetta limitazione _ha effetto immediato a decorrere dalla data di ricezione_del provvedimento. Dunque dal 31/03/2023.
C’è poi una seconda imposizione che assegna 20 giorni per comunicare quali iniziative siano state intraprese al fine di dare attuazione a quanto prescritto, ovvero l’immediata limitazione del trattamento (io non leggo altre prescrizioni),e perfornire ogni elemento ritenuto utile a giustificare le violazioni evidenziate. Violazioni per cui sussiste un /fumus boni juris/e che saranno oggetto di futura istruttoria.
Non sono stati concessi 20 giorni per conformarsi al GDPR, ma 20 giorni per spiegare cosa hanno immediatamente fatto in relazione al provvedimento.
3) Prima di affrontare il tema centrale su cosa si intenda per “limitazione del trattamento” è opportuno precisare quali profili di illiceità individui il provvedimento. Mi paiono 4, ma non sono sicuro: i) l’assenza di informativa (che invece c’è); ii l’assenza di base giuridica neltrattamento dei dati personali nei grandi dataset di addestramento (tema amplissimo che incide su tutti i sistemi di ML e non solo); iii) l’inesattezza di dati personali rivelatadagli out-put errati della chat (questa è davvero significativadi un grave problema di comprensione del servizio stesso) ed in ultimo iv) il problema dell'accesso dei minori.
4) Ora, tralasciando le molte considerazioni in diritto che potrebbero farsi su queste più o meno provate violazioni,ed a prescindere dalla loro fondatezza, è necessario capire cosa è una “limitazione del trattamento”. E’fondamentale credoper capire la reale portata del provvedimento emesso dal Presidente del Garante e quali opzioni avesse OpenAI al di là di quella, piuttosto semplice, di fregarsene del provvedimento non essendo stabilita in EU e non essendo pensabile alcuna capacità esecutiva o impositiva da parte dell’Autorità Italiana, soprattuttoal di fuori di qualsiasi coordinamento con le omologhe Autority europee, efficacequanto meno a livello di pressione politica.
Purtroppo ancora una volta il provvedimento non aiuta a capire quale limitazione il provider avrebbe dovuto applicare, a quali dati in concretoe a quali specifici trattamenti; in un sistema in cuiprobabilmente manco OpenAi sa granularmentecosa c’èe cosaaccade, non mi pare facile “adempiere” all’ordine immediato...
Sul punto può aiutare ilConsiderando 67 del GDPR ove si legge: N/egli archivi automatizzati, la limitazione del trattamento dei dati personali dovrebbe in linea di massima essere assicurata mediante dispositivi tecnici in modo tale che i dati personali non siano sottoposti a ulteriori trattamenti e non possano più essere modificati. Il sistema dovrebbe indicare chiaramente che il trattamento dei dati personali è stato limitato./
Gli informatici della lista mi aiuteranno a capire come si applica una limitazione del trattamento sui dati personali di interessati stabiliti in Italia in una rete quale quella utilizzata da ChatGpt. Mi chiedo ad esempio come nell’ampio data-set formato dagli archivi delle principali testate giornalistiche statunitensi (uno negli n° data set dichiarati)possano esserindividuati, contrassegnati e bloccatii soli dati delle persone, non italiane, ma stabilite in Italia. Il provvedimento credo implicherebbe il blocco dell’intera rete, ma sul punto gli informatici mi aiuteranno.Io non saprei che fare.
Ma al di là dei dati già archiviati, OpenAI dal 31/03/2023 non può ovviamente trattare, e dunque acquisire, dati di interessati stabiliti in Italia. Sarebbe singolare non applicare una generica limitazione all’acquisizione.
Bloccare l’accesso dall’italia, a fronte di un provvedimento così generico è la prima soluzioneche io suggerirei alprovider ed ètemol’unica cosa che si puòfare senza bloccare l’intero servizio worldwide.
_Quel provvedimento d’urgenzanon chiede adeguamenti al GDPR o la messa in conformità: individua eipotizza alcune possibili violazioni e opera cautelativamente la limitazione di alcuni dati personali (quelli delle persone che si trovano nel territorio italiano), alla data31/03/2023. Punto._
Le critiche al blocco operato da OpenAI ieri mi pare possano avere una loro fondatezza solo se rapportate alla scelta, del tutto legittima,tra due opzioni:fregarsene del provvedimento oppurein qualche modo adempiere nell’unico modo possibile: bloccare l’Italia. E probabilmente per sfruttare l’abnormità del provvedimento esollevare un caso OpenAI ha scelto la seconda.
Concordo con Casilli: ci sono analogie con la vicenda Berlusconi degli anni ‘80. Anche in quel caso una legge inadeguata ed inattuale (e incompatibile con l’art.21 Cost) si scontrava con una evoluzione tecnologica che ne palesava l’assoluta iniquità. La mossa di Berlusconi fu una forzatura del tutto legittima, e fu scelta efficace. I benefici in termini pluralismo nel settore dei media ed i danni e i disastri della televisione commerciale sono poi un’altro capitolo della storia.
Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo: il tema mi pare davvero non meriti di esser affrontata dagli enti regolatori italiani con provvedimenti d’urgenza inutili, inefficaci e forieri di danno per l’Italia. Purtroppo l’andazzo è questo, non solo nell’approccio alle questioni tecnologiche a noi care.
Buona domenica
Carlo
Il giorno sab 1 apr 2023 alle ore 16:38 de petra giulio <giulio.depetra@gmail.com> ha scritto:
Leggo sul sito del Garante il testo del provvedimento:
OpenAI, che non ha una sede nell’Unione ma ha designato un rappresentante nello Spazio economico europeo, deve comunicare entro 20 giorni le misure intraprese in attuazione di quanto richiesto dal Garante, pena una sanzione fino a 20 milioni di euro o fino al 4% del fatturato globale annuo.
Non è una drammatizzazione, ma un provvedimento coerente con i rilievi formulati e in linea con altri provvedimenti emanati dal Garante. Entro 20 giorni Open AI deve comunicare quali misure intende adottare per eliminare le cause dei rilievi formulati. Non attuare le misure, che possono richiedere tempo, ma solo comunicarle al Garante.
Non comprendo proprio perché con questa decisione: ‘lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.’ Al contrario mi sembra che l’Autorita’ di garanzia, organo dello Stato, ma non del governo, cerchi di svolgere il suo compito di tutela dei cittadini, provando a rendere meno infrequentabile uno spazio pubblico colonizzato da imprese private digitali.
A meno di eccepire sul merito dei rilievi del Garante, o di contestare le regole che il Garante ha l’obbligo (non la discrezione) di attuare, la questione politica evidente è quella della enorme sproporzione di potere tra gli organismi pubblici nazionali che hanno il compito di attuare le regole decise in sede politica e le grandi imprese digitali alle quali quelle regole sono destinate.
Il richiamo che fa Antonio Casilli ad un altro momento della recente storia italiana mi sembra efficace e pertinente.
G.
Il giorno sab 1 apr 2023 alle 12:05 Guido Vetere <vetere.guido@gmail.com> ha scritto:
Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento.
Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee.
Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia.
Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana.
Siamo pertanto di fronte a una drammatizzazione.
L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.
OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia.
Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie.
G.
On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote:
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà).
Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html
====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ======================================================
-- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
-- * * *Avv. Carlo Blengino* * * /Via Duchessa Jolanda n. 19,/ /10138 Torino (TO) - Italy/ /tel. +39 011 4474035/ Penalistiassociati.it
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
ringrazio davvero molto Carlo, che mette in fila una serie di argomenti e di considerazioni che mi trovo a condividere. Vorrei fare una sottolineatura: già nelle parole di Carlo ci sono le tracce di una impianto normativo (quello del GDPR) che mostrava già al momento della sua formale adozione (parliamo del 2016) molti limiti in termini di adeguatezza regolativa rispetto ai fenomeni (già allora) in essere. Da allora le cose, evidentemente, sono molto peggiorate (sempre in termini di adeguatezza regolativa). E, tuttavia, il GDPR offre molte munizioni se si volesse approcciare alla regolazione dei trattamenti dei dati personali, anche con riferimento alle cd. intelligenze artificiali. Quello che noto, però, è che, per un verso, in sede UE ci si è imbarcati nella elaborazione di una disciplina specifica "ad hoc" - il regolamento AI - per altro non pefettamente coordinata con la disciplina GDPR e che presenta già molti profili di perplessità/inadeguatezza (per fare solo un esempio, il più immediato rispetto al nostor tema: non avevano previsto il caso delle chatbot!). Dall'altra parte, la regolamentazione che invece c'è (il GDPR) presenta sì molte inadeguatezze, ma soprattutto mostra - sul piano della governance - un assetto (ancora) estremamente frammetato che comporta tempi e modalità di intervento farraginosi e (a volte) barocchi. C'è un tema di fondo (quanta capacità decisionale si è voluto trattenere in sede nazionale), che è un nodo gordiano. C'è un tema connesso al modello della tutela di diritti fondamentali basata su tante autorità indipendenti quanti sono i paesi membri (non sto criticando l'istituto, sto sottolineando che non è affatto detto che 27 autorità nazionali indipendenti siano capaci di coordinarsi adeguatamente; né è dimostrato che siano capaci di farlo meglio di 27 governi, per intenderci). Per arrivare ad affermare che Meta (in riferimento ai servizi di Facebook e Instagram) tratta i dati degli utenti (e anche di terzi non utenti) in modo che non corrisponde alle basi giuridiche legittimanti previste nel GDPR (in base ad una causa intentata il giorno stesso che il GDPR è entrato in vigore, cioè nel maggio del 2018), ed irrogare una (sostanziosa) multa, ci sono voluti quasi 5 anni (e adesso ci sarà tutta la trafila dei ricorsi giurisdizionali)! Senza contare la diversità di vedute mostrata dalle autorità di garanzia nazionali, e che pare riproporsi anche in sede giurisdizionale (vedi le recenti sentenze olandesi relative ai terms of service come base contrattuale dei trattamenti). Insomma, il tanto decantato "brussel effect" mi pare che debba fare i conti con una governance ed una capacità di enforcement che non sono all'altezza degli obiettivi (e dell'ambiente in cui si deve operare). La scelta, un po' estemporanea e in effetti abbastanza "oscura" nelle sue motivazioni, del Garante italiano, mi pare un sintomo di questa situazione complessiva. (mi associo sempre a Carlo nei ringraziamento per il privilegio di poter fruire di questo spazio di discussione). Benedetto [cid:part1.6g0tOixx.YFaDbotM@unipg.it] Il 02/04/2023 09:12, Carlo Blengino ha scritto: Provo a proporvi alcune considerazioni in diritto, giusto per tentare di dare un contributo, per quel che posso, nell'interpretare un provvedimento che mi lascia molto perplesso. 1) Il provvedimento è un provvedimento connotato da “particolare urgenza ed indifferibilità” tanto da non consentire neppure la convocazione in tempo utile del Garante, ovvero del Collegio dei Garanti, ed è firmato ed adottato dal solo Presidente. Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. Non è una buona partenza e la cosa si presta a polemiche più o meno strumentali. 2) E’ un provvedimento di limitazione provvisoria del trattamento dei dati personali delle persone che si trovano nel territorio italiano (a prescindere da cittadinanza o residenza) e la predetta limitazione ha effetto immediato a decorrere dalla data di ricezione del provvedimento. Dunque dal 31/03/2023. C’è poi una seconda imposizione che assegna 20 giorni per comunicare quali iniziative siano state intraprese al fine di dare attuazione a quanto prescritto, ovvero l’immediata limitazione del trattamento (io non leggo altre prescrizioni), e per fornire ogni elemento ritenuto utile a giustificare le violazioni evidenziate. Violazioni per cui sussiste un fumus boni juris e che saranno oggetto di futura istruttoria. Non sono stati concessi 20 giorni per conformarsi al GDPR, ma 20 giorni per spiegare cosa hanno immediatamente fatto in relazione al provvedimento. 3) Prima di affrontare il tema centrale su cosa si intenda per “limitazione del trattamento” è opportuno precisare quali profili di illiceità individui il provvedimento. Mi paiono 4, ma non sono sicuro: i) l’assenza di informativa (che invece c’è); ii l’assenza di base giuridica nel trattamento dei dati personali nei grandi dataset di addestramento (tema amplissimo che incide su tutti i sistemi di ML e non solo); iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso) ed in ultimo iv) il problema dell'accesso dei minori. 4) Ora, tralasciando le molte considerazioni in diritto che potrebbero farsi su queste più o meno provate violazioni, ed a prescindere dalla loro fondatezza, è necessario capire cosa è una “limitazione del trattamento”. E’ fondamentale credo per capire la reale portata del provvedimento emesso dal Presidente del Garante e quali opzioni avesse OpenAI al di là di quella, piuttosto semplice, di fregarsene del provvedimento non essendo stabilita in EU e non essendo pensabile alcuna capacità esecutiva o impositiva da parte dell’Autorità Italiana, soprattutto al di fuori di qualsiasi coordinamento con le omologhe Autority europee, efficace quanto meno a livello di pressione politica. Purtroppo ancora una volta il provvedimento non aiuta a capire quale limitazione il provider avrebbe dovuto applicare, a quali dati in concreto e a quali specifici trattamenti; in un sistema in cui probabilmente manco OpenAi sa granularmente cosa c’è e cosa accade, non mi pare facile “adempiere” all’ordine immediato... Sul punto può aiutare il Considerando 67 del GDPR ove si legge: Negli archivi automatizzati, la limitazione del trattamento dei dati personali dovrebbe in linea di massima essere assicurata mediante dispositivi tecnici in modo tale che i dati personali non siano sottoposti a ulteriori trattamenti e non possano più essere modificati. Il sistema dovrebbe indicare chiaramente che il trattamento dei dati personali è stato limitato. Gli informatici della lista mi aiuteranno a capire come si applica una limitazione del trattamento sui dati personali di interessati stabiliti in Italia in una rete quale quella utilizzata da ChatGpt. Mi chiedo ad esempio come nell’ampio data-set formato dagli archivi delle principali testate giornalistiche statunitensi (uno negli n° data set dichiarati) possano esser individuati, contrassegnati e bloccati i soli dati delle persone, non italiane, ma stabilite in Italia. Il provvedimento credo implicherebbe il blocco dell’intera rete, ma sul punto gli informatici mi aiuteranno. Io non saprei che fare. Ma al di là dei dati già archiviati, OpenAI dal 31/03/2023 non può ovviamente trattare, e dunque acquisire, dati di interessati stabiliti in Italia. Sarebbe singolare non applicare una generica limitazione all’acquisizione. Bloccare l’accesso dall’italia, a fronte di un provvedimento così generico è la prima soluzione che io suggerirei al provider ed è temo l’unica cosa che si può fare senza bloccare l’intero servizio worldwide. Quel provvedimento d’urgenza non chiede adeguamenti al GDPR o la messa in conformità: individua e ipotizza alcune possibili violazioni e opera cautelativamente la limitazione di alcuni dati personali (quelli delle persone che si trovano nel territorio italiano), alla data 31/03/2023. Punto. Le critiche al blocco operato da OpenAI ieri mi pare possano avere una loro fondatezza solo se rapportate alla scelta, del tutto legittima, tra due opzioni: fregarsene del provvedimento oppure in qualche modo adempiere nell’unico modo possibile: bloccare l’Italia. E probabilmente per sfruttare l’abnormità del provvedimento e sollevare un caso OpenAI ha scelto la seconda. Concordo con Casilli: ci sono analogie con la vicenda Berlusconi degli anni ‘80. Anche in quel caso una legge inadeguata ed inattuale (e incompatibile con l’art.21 Cost) si scontrava con una evoluzione tecnologica che ne palesava l’assoluta iniquità. La mossa di Berlusconi fu una forzatura del tutto legittima, e fu scelta efficace. I benefici in termini pluralismo nel settore dei media ed i danni e i disastri della televisione commerciale sono poi un’altro capitolo della storia. Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo: il tema mi pare davvero non meriti di esser affrontata dagli enti regolatori italiani con provvedimenti d’urgenza inutili, inefficaci e forieri di danno per l’Italia. Purtroppo l’andazzo è questo, non solo nell’approccio alle questioni tecnologiche a noi care. Buona domenica Carlo Il giorno sab 1 apr 2023 alle ore 16:38 de petra giulio <giulio.depetra@gmail.com<mailto:giulio.depetra@gmail.com>> ha scritto: Leggo sul sito del Garante il testo del provvedimento: OpenAI, che non ha una sede nell’Unione ma ha designato un rappresentante nello Spazio economico europeo, deve comunicare entro 20 giorni le misure intraprese in attuazione di quanto richiesto dal Garante, pena una sanzione fino a 20 milioni di euro o fino al 4% del fatturato globale annuo. Non è una drammatizzazione, ma un provvedimento coerente con i rilievi formulati e in linea con altri provvedimenti emanati dal Garante. Entro 20 giorni Open AI deve comunicare quali misure intende adottare per eliminare le cause dei rilievi formulati. Non attuare le misure, che possono richiedere tempo, ma solo comunicarle al Garante. Non comprendo proprio perché con questa decisione: ‘lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.’ Al contrario mi sembra che l’Autorita’ di garanzia, organo dello Stato, ma non del governo, cerchi di svolgere il suo compito di tutela dei cittadini, provando a rendere meno infrequentabile uno spazio pubblico colonizzato da imprese private digitali. A meno di eccepire sul merito dei rilievi del Garante, o di contestare le regole che il Garante ha l’obbligo (non la discrezione) di attuare, la questione politica evidente è quella della enorme sproporzione di potere tra gli organismi pubblici nazionali che hanno il compito di attuare le regole decise in sede politica e le grandi imprese digitali alle quali quelle regole sono destinate. Il richiamo che fa Antonio Casilli ad un altro momento della recente storia italiana mi sembra efficace e pertinente. G. Il giorno sab 1 apr 2023 alle 12:05 Guido Vetere <vetere.guido@gmail.com<mailto:vetere.guido@gmail.com>> ha scritto: Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento. Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee. Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia. Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana. Siamo pertanto di fronte a una drammatizzazione. L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico. OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia. Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie. G. On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it<mailto:nardelli@mat.uniroma2.it>> wrote: A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html [cid:part2.fpJxa2Na.XobTzCl0@unipg.it] ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it<mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa -- Avv. Carlo Blengino Via Duchessa Jolanda n. 19, 10138 Torino (TO) - Italy tel. +39 011 4474035 Penalistiassociati.it _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Il giorno dom 2 apr 2023 alle ore 09:12 Carlo Blengino < blengino@penalistiassociati.it> ha scritto: ...omissis...
Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo (...omissis...)
anche io ringrazio Nexa e gli esperti (informatici e giuristi) che lo frequentano che con le loro analisi aiutano a capire questo fenomeno dell'AI e approfitto per porre una domanda: "ma gli italiani che adesso usano le VPN per raggiungere il sito di ChatGPT stanno compiendo un atto illegale ? " Saluti Paolo Del Romano
NO. Non solo nel caso di specie ove fino a prova contraria i dati personali miei (ovvero le informazioni su di me) le comunico a chi voglio, ma in generale l'uso di VPN è e deve rimanere l'esercizio di un diritto fondamentale (art-15 Cost). Il giorno che l'uso di VPN sarà illegale (come nei paesi non democratici) dobbiamo modificare la nostra vecchia Costituzione e un po' di carte sovrannazionali. Accadrà temo, che per molte agenzie statuali gli strumenti che oggi sono fondamentali strumenti per l'esercizio di diritti costituzionali sono considerati tecnologie elusive della loro capacità di captazione. E'un problema, ma un altro problema... CB Il giorno dom 2 apr 2023 alle ore 11:45 Paolo Del Romano < delromano@gmail.com> ha scritto:
Il giorno dom 2 apr 2023 alle ore 09:12 Carlo Blengino < blengino@penalistiassociati.it> ha scritto:
...omissis...
Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo (...omissis...)
anche io ringrazio Nexa e gli esperti (informatici e giuristi) che lo frequentano che con le loro analisi aiutano a capire questo fenomeno dell'AI e approfitto per porre una domanda:
"ma gli italiani che adesso usano le VPN per raggiungere il sito di ChatGPT stanno compiendo un atto illegale ? "
Saluti
Paolo Del Romano
-- *Avv. Carlo Blengino* *Via Duchessa Jolanda n. 19,* *10138 Torino (TO) - Italy* *tel. +39 011 4474035* Penalistiassociati.it

"ma gli italiani che adesso usano le VPN per raggiungere il sito di ChatGPT stanno compiendo un atto illegale ? "
Le VPN sono illegali in Bielorussia, Iraq, Turkmenistan, Corea del Nord. Fortemente limitate e/o controllate dal governo, in Cina, Iran, Oman, Russia, Turchia, Emirati Arabi [1] Comunque, se è solo per usare ChatGPT, invece delle VPN, io proverei servizi alternativi, tipo poe.com (servizio di Quora) che permette di interpellare, non solo ChatGPT, ma Sage, GPT-4, Claude+, Claude-instant, Dragonfly. Antonio [1] https://nordvpn.com/it/blog/usare-vpn-e-legale/
servizi alternativi, tipo poe.com (servizio di Quora) che permette di interpellare, non solo ChatGPT, ma Sage, GPT-4, Claude+, Claude-instant, Dragonfly.
aggiungo https://www.pizzagpt.it/ (nessuna registrazione) C'è fermento in rete. A.

Salve Carlo, ho una domanda: ma che tu sappia, la Legge è ancora uguale per tutti? O basta introdurre un automatismo sufficientemente opaco per violare i diritti fondamentali di milioni di persone?
iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso)
... oppure è significativa di una profonda comprensione del diritto. L'Autorità Garante ha chiesto di conformare uno strumento alla Legge. E come sai, ChatGPT non è un fenomeno naturale fuori dal controllo umano, ma un software. Come ogni altro software può essere modificato per correggerne il funzionamento.
in un sistema in cui probabilmente manco OpenAi sa granularmente cosa c’è e cosa accade, non mi pare facile “adempiere” all’ordine immediato...
Se OpenAI (che si legge Microsoft) non ha soldi o competenze sufficienti per correggerne il funzionamento, in modo che il dataset utilizzato per la sua programmazione statistica e il suo output rispettino i diritti umani, può spegnerlo. Anche l'ILVA non aveva soldi sufficienti per operare in conformità con la Legge, e Taranto (e noi con le nostre tasse) pagheremo per decenni il fatto che nessuna delle autorità competenti sia intervenuta per tempo. Lo stesso vale per la Eternit, ad esempio. Tutti a girarsi dall'altra parte per non disturbare il business. Per una volta che un'Autorità di Garanzia OSA fare il proprio mestiere, l'unica cosa che mi sento di fare è applaudire.
Mi chiedo ad esempio come nell’ampio data-set formato dagli archivi delle principali testate giornalistiche statunitensi (uno negli n° data set dichiarati) possano esser individuati, contrassegnati e bloccati i soli dati delle persone, non italiane, ma stabilite in Italia.
Bravo: questa è una delle azioni necessarie per limitare il trattamento. (NB: necessarie, ma non sufficienti ;-) Si prende il dataset, si paga un plotone di persone per leggere e ricopiare manualmente nel sistema solo gli articoli che non includono dati personali di cittadini Europei. Ovviamente ogni articolo va letto da almeno 3 persone e si includono nel dataset solo quelli confermati da tutte e tre le persone. Far copiare il testo dell'articolo serve a garantirne l'effettiva lettura. E' possibile? Sì. E' costoso? Moltissimo. Ma se non violare un diritto di milioni di persone costa troppo, possiamo sbattercene? Che io sappia, no. Perché nessuno è costretto a sviluppare e diffondere agenti chatbot o LLM come GPT4. E la libertà di chi decide di farlo, finisce dove iniziano i diritti di tutti gli altri.
Anche in quel caso una legge inadeguata ed inattuale (e incompatibile con l’art.21 Cost) si scontrava con una evoluzione tecnologica che ne palesava l’assoluta iniquità.
Dunque secondo te, anche ChatGPT palesa l'iniquità della normativa. Posizione interessante, posso chiederti approfondire? In che senso il GDPR è iniquo? E l'articolo 2 della Costituzione, non ti sembra altrettanto iniquo? E l'articolo 3 della Costituzione? E' iniquo o proprio una barzelletta? Io non posso scrivere cose false su di te: perché OpenAI può farlo?
Bloccare l’accesso dall’italia, a fronte di un provvedimento così generico è la prima soluzione che io suggerirei al provider ed è temo l’unica cosa che si può fare senza bloccare l’intero servizio worldwide.
Il provvedimento non è generico: rileva gravi violazioni di Legge ed esige la immediata interruzione delle stesse. Bloccare l'accesso dall'Italia non ne sana nessuna: in tutto il resto del mondo, informazioni false relative ai cittadini italiani ed europei continuano ad essere diffuse da OpenAI tramite GPT4 e ChatGPT. E questo al di là delle VPN che, sebbene non proteggano in alcun modo i dati personali di chi le utilizza, permettono di aggirare queste arbitrarie discriminazioni da parte di un azienda di un intero popolo che ha osato esigere il rispetto delle proprie leggi. Ad oggi, che io sappia, l'unico modo che OpenAI ha per rispettare il GDPR e i MIEI e TUOI diritti fondamentali, è rieffettuare la programmazione di GPT4 a partire da dataset che non includano i dati personali dei cittadini europei. Fino ad allora, DEVE interrompere il "servizio". Se non lo fa, viola il GDPR. GDPR che protegge (bene o male è un altro discorso) i miei diritti, i TUOI diritti, quelli dei nostri figli e della loro generazione. Trovo assurdo che, di fronte a tale scempio del Diritto e dei diritti di milioni di persone, qualcuno si strappi le vesti perché gli è stato tolto un giocattolo. Personalmente, queste reazioni mi spaventano molto. Giacomo On Sun, 2 Apr 2023 09:12:14 +0200 Carlo Blengino wrote:
Provo a proporvi alcune considerazioni in diritto, giusto per tentare di dare un contributo, per quel che posso, nell'interpretare un provvedimento che mi lascia molto perplesso.
1) Il provvedimento è un provvedimento connotato da “particolare urgenza ed indifferibilità” tanto da non consentire neppure la convocazione in tempo utile del Garante, ovvero del Collegio dei Garanti, ed è firmato ed adottato dal solo Presidente. Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. Non è una buona partenza e la cosa si presta a polemiche più o meno strumentali.
2) E’ un provvedimento di *limitazione provvisoria del trattamento *dei dati personali delle persone che si trovano nel territorio italiano (a prescindere da cittadinanza o residenza) e la predetta limitazione *ha effetto immediato a decorrere dalla data di ricezione* del provvedimento. Dunque dal 31/03/2023.
C’è poi una seconda imposizione che assegna 20 giorni per comunicare quali iniziative siano state intraprese al fine di dare attuazione a quanto prescritto, ovvero l’immediata limitazione del trattamento (io non leggo altre prescrizioni), e per fornire ogni elemento ritenuto utile a giustificare le violazioni evidenziate. Violazioni per cui sussiste un *fumus boni juris* e che saranno oggetto di futura istruttoria.
Non sono stati concessi 20 giorni per conformarsi al GDPR, ma 20 giorni per spiegare cosa hanno immediatamente fatto in relazione al provvedimento.
3) Prima di affrontare il tema centrale su cosa si intenda per “limitazione del trattamento” è opportuno precisare quali profili di illiceità individui il provvedimento. Mi paiono 4, ma non sono sicuro: i) l’assenza di informativa (che invece c’è); ii l’assenza di base giuridica nel trattamento dei dati personali nei grandi dataset di addestramento (tema amplissimo che incide su tutti i sistemi di ML e non solo); iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso) ed in ultimo iv) il problema dell'accesso dei minori.
4) Ora, tralasciando le molte considerazioni in diritto che potrebbero farsi su queste più o meno provate violazioni, ed a prescindere dalla loro fondatezza, è necessario capire cosa è una “limitazione del trattamento”. E’ fondamentale credo per capire la reale portata del provvedimento emesso dal Presidente del Garante e quali opzioni avesse OpenAI al di là di quella, piuttosto semplice, di fregarsene del provvedimento non essendo stabilita in EU e non essendo pensabile alcuna capacità esecutiva o impositiva da parte dell’Autorità Italiana, soprattutto al di fuori di qualsiasi coordinamento con le omologhe Autority europee, efficace quanto meno a livello di pressione politica.
Purtroppo ancora una volta il provvedimento non aiuta a capire quale limitazione il provider avrebbe dovuto applicare, a quali dati in concreto e a quali specifici trattamenti; in un sistema in cui probabilmente manco OpenAi sa granularmente cosa c’è e cosa accade, non mi pare facile “adempiere” all’ordine immediato...
Sul punto può aiutare il Considerando 67 del GDPR ove si legge: N*egli archivi automatizzati, la limitazione del trattamento dei dati personali dovrebbe in linea di massima essere assicurata mediante dispositivi tecnici in modo tale che i dati personali non siano sottoposti a ulteriori trattamenti e non possano più essere modificati. Il sistema dovrebbe indicare chiaramente che il trattamento dei dati personali è stato limitato.*
Gli informatici della lista mi aiuteranno a capire come si applica una limitazione del trattamento sui dati personali di interessati stabiliti in Italia in una rete quale quella utilizzata da ChatGpt. Mi chiedo ad esempio come nell’ampio data-set formato dagli archivi delle principali testate giornalistiche statunitensi (uno negli n° data set dichiarati) possano esser individuati, contrassegnati e bloccati i soli dati delle persone, non italiane, ma stabilite in Italia. Il provvedimento credo implicherebbe il blocco dell’intera rete, ma sul punto gli informatici mi aiuteranno. Io non saprei che fare.
Ma al di là dei dati già archiviati, OpenAI dal 31/03/2023 non può ovviamente trattare, e dunque acquisire, dati di interessati stabiliti in Italia. Sarebbe singolare non applicare una generica limitazione all’acquisizione.
Bloccare l’accesso dall’italia, a fronte di un provvedimento così generico è la prima soluzione che io suggerirei al provider ed è temo l’unica cosa che si può fare senza bloccare l’intero servizio worldwide.
*Quel provvedimento d’urgenza non chiede adeguamenti al GDPR o la messa in conformità: individua e ipotizza alcune possibili violazioni e opera cautelativamente la limitazione di alcuni dati personali (quelli delle persone che si trovano nel territorio italiano), alla data 31/03/2023. Punto.*
Le critiche al blocco operato da OpenAI ieri mi pare possano avere una loro fondatezza solo se rapportate alla scelta, del tutto legittima, tra due opzioni: fregarsene del provvedimento oppure in qualche modo adempiere nell’unico modo possibile: bloccare l’Italia. E probabilmente per sfruttare l’abnormità del provvedimento e sollevare un caso OpenAI ha scelto la seconda.
Concordo con Casilli: ci sono analogie con la vicenda Berlusconi degli anni ‘80. Anche in quel caso una legge inadeguata ed inattuale (e incompatibile con l’art.21 Cost) si scontrava con una evoluzione tecnologica che ne palesava l’assoluta iniquità. La mossa di Berlusconi fu una forzatura del tutto legittima, e fu scelta efficace. I benefici in termini pluralismo nel settore dei media ed i danni e i disastri della televisione commerciale sono poi un’altro capitolo della storia.
Io mi fermo qui, e ringrazio ancora una volta Nexa per questo spazio di discussione che da mesi, con competenza, dibatte su una cosa grossa che ci sta accadendo: il tema mi pare davvero non meriti di esser affrontata dagli enti regolatori italiani con provvedimenti d’urgenza inutili, inefficaci e forieri di danno per l’Italia. Purtroppo l’andazzo è questo, non solo nell’approccio alle questioni tecnologiche a noi care.
Buona domenica
Carlo
Il giorno sab 1 apr 2023 alle ore 16:38 de petra giulio < giulio.depetra@gmail.com> ha scritto:
Leggo sul sito del Garante il testo del provvedimento:
OpenAI, che non ha una sede nell’Unione ma ha designato un rappresentante nello Spazio economico europeo, deve comunicare entro 20 giorni le misure intraprese in attuazione di quanto richiesto dal Garante, pena una sanzione fino a 20 milioni di euro o fino al 4% del fatturato globale annuo.
Non è una drammatizzazione, ma un provvedimento coerente con i rilievi formulati e in linea con altri provvedimenti emanati dal Garante. Entro 20 giorni Open AI deve comunicare quali misure intende adottare per eliminare le cause dei rilievi formulati. Non attuare le misure, che possono richiedere tempo, ma solo comunicarle al Garante.
Non comprendo proprio perché con questa decisione: ‘lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.’ Al contrario mi sembra che l’Autorita’ di garanzia, organo dello Stato, ma non del governo, cerchi di svolgere il suo compito di tutela dei cittadini, provando a rendere meno infrequentabile uno spazio pubblico colonizzato da imprese private digitali.
A meno di eccepire sul merito dei rilievi del Garante, o di contestare le regole che il Garante ha l’obbligo (non la discrezione) di attuare, la questione politica evidente è quella della enorme sproporzione di potere tra gli organismi pubblici nazionali che hanno il compito di attuare le regole decise in sede politica e le grandi imprese digitali alle quali quelle regole sono destinate.
Il richiamo che fa Antonio Casilli ad un altro momento della recente storia italiana mi sembra efficace e pertinente.
G.
Il giorno sab 1 apr 2023 alle 12:05 Guido Vetere <vetere.guido@gmail.com> ha scritto:
Mentre continuo a veleggiare su ChatGPT con una banalissima VPN, mi inoltro in qualche tentativo di ragionamento.
Immagino che il Garante abbia valutato che le garanzie di protezione dei dati personali fornite da OpenAI siano insufficienti, e non ho ragione di credere che tali valutazioni siano erronee.
Ma a questo punto interviene una decisione: diffidare OpenAI e minacciare una multa. A fronte di questa, la società statunitense decide a sua volta di sospendere il servizio in Italia.
Entrambe le opzioni mi sembrano fuori misura: da una parte sarebbe bastata, di primo acchito, una richiesta di chiarimenti e un invito alla cautela alla nostra cittadinanza; dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana.
Siamo pertanto di fronte a una drammatizzazione.
L'authority italiana, che non è il Governo ma forse coglie lo 'spirito dei tempi', agisce in modo patriarcale: lo Stato regola i comportamenti dei cittadini riducendo i gradi di libertà e l'agibilità dello spazio pubblico.
OpenAI coglie l'occasione per ridurre all'assurdo la posizione di chi critica gli sviluppi e gli impieghi della loro loro tecnologia.
Vittime di questa drammatizzazione sono coloro che in tutto il mondo stanno cercando di costruire uno sviluppo sostenibile, sicuro e sociale delle tecnologie.
G.
On Sat, 1 Apr 2023 at 11:19, Enrico Nardelli <nardelli@mat.uniroma2.it> wrote:
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== -- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. ... Nel comunicato stampa, il Garante fa riferimento al data-breach del 20 marzo [1]. Cos'è successo il 20 marzo? Che alcuni utenti hanno riferito di conversazioni di estranei apparse inspiegabilmente nelle loro finestre di chat. Probabilmente il motivo dell'urgenza è questo e non che il set di dati di addestramento contenga quantità infinite di dati personali e spesso sensibili che possano emergere in modo casuale in risposta a un prompt.
Antonio [1] https://www.theregister.com/2023/03/23/openai_ceo_leak/

e' successo anche a me, in effetti, nelle api On 02/04/23 19:35, Antonio wrote:
Le ragioni di tale straordinaria urgenza ed indifferibilità non sono note e non sono espresse nel provvedimento. ... Nel comunicato stampa, il Garante fa riferimento al data-breach del 20 marzo [1]. Cos'è successo il 20 marzo? Che alcuni utenti hanno riferito di conversazioni di estranei apparse inspiegabilmente nelle loro finestre di chat. Probabilmente il motivo dell'urgenza è questo e non che il set di dati di addestramento contenga quantità infinite di dati personali e spesso sensibili che possano emergere in modo casuale in risposta a un prompt.
Antonio
[1] https://www.theregister.com/2023/03/23/openai_ceo_leak/ _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
... dall'altra si sarebbe potuto attendere il decorso dei termini della diffida italiana.
Il provvedimento del Garante [1]: - dispone [...] la misura della limitazione provvisoria, del trattamento dei dati personali degli interessati stabiliti nel territorio italiano [con] ... effetto immediato a decorrere dalla data di ricezione del presente provvedimento ... - invita [...] /altresì/, entro 20 giorni dalla data di ricezione dello stesso, a comunicare quali iniziative siano state intraprese al fine di dare attuazione a quanto prescritto e di fornire ogni elemento ritenuto utile a giustificare le violazioni sopra evidenziate. Il Garante non ha ovviamente "imposto" ad OpenAI di "chiudere" ChatGPT agli utenti italiani. Il "trattamento", secondo l'art.4 del GDPR è: "qualsiasi operazione o insieme di operazioni, compiute con o senza l'ausilio di processi automatizzati e applicate a dati personali o insiemi di dati personali, come la raccolta, la registrazione, l'organizzazione, la strutturazione, la conservazione, l'adattamento o la modifica, l'estrazione, la consultazione, l'uso, la comunicazione mediante trasmissione, diffusione o qualsiasi altra forma di messa a disposizione, il raffronto o l'interconnessione, la limitazione, la cancellazione o la distruzione" La "limitazione del trattamento" è: "il contrassegno dei dati personali conservati con l'obiettivo di limitarne il trattamento in futuro". Ad OpenAI, per ottemperare a quanto disposto dal Garante, sarebbe stato "sufficiente" applicare questo "contrassegno". Evidentemente non hanno intenzione di scollegare il "servizio" dai "dati personali". Antonio [1] https://www.garanteprivacy.it/web/guest/home/docweb/-/docweb-display/docweb/...

In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’. From: nexa <nexa-bounces@server-nexa.polito.it> On Behalf Of Enrico Nardelli Sent: Saturday, April 1, 2023 4:19 AM To: nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html [cid:image001.png@01D96532.5104F5B0] ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it<mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== --
secondo ChatGPT, riporta il podcast Knightmare di Walter Vannini, io sarei stato membro di un certo insieme di sciocchezze e, dopo avergli fatto notare piu' volte che erano informazioni sbagliate, ChatGPT si e' scusato e ha detto che sono morto. la notizia e' esagerata. posso chiedere ad OpeAI^W Microsft di correggerla ? ciao, s. On 02/04/23 14:11, Roberto Dolci wrote:
In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’.
*From:* nexa <nexa-bounces@server-nexa.polito.it> *On Behalf Of *Enrico Nardelli *Sent:* Saturday, April 1, 2023 4:19 AM *To:* nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà).
Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... <https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html <https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html>
====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli <https://www.mat.uniroma2.it/~nardelli> blog: https://link-and-think.blogspot.it/ <https://link-and-think.blogspot.it/> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it <mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont <https://blue.meet.garr.it/b/enr-y7f-t0q-ont> ======================================================
--
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Molto (molto) probabilmente ChatGPT non ha nemmeno memoria di quanto sotto, te l'ha scritto perche' in quel preciso momento era la sua stima migliore. Un piccolo esempio anche nella rubrica Johnson sull'Economist di questa settimana: ChatGPT non ha un "database" per conservare questi testi e nemmeno per imparare da essi. Chi ti ha risposto e' un essere in carne ed ossa, che insieme a centinaia di colleghi spende le giornate a riparare questi fraintendimenti, affettuosamente chiamati "allucinazioni". Puoi sicuramente chiedergli di correggerla, ed uno dei ragazzi ti assicurera' che e' stato cancellato/corretto, ma non e' esattamente così. Tu vieni classificato in modo particolare e fanno in modo di non darti piu' fastidio, almeno su questo tema. Ciao rob -----Original Message----- From: nexa <nexa-bounces@server-nexa.polito.it> On Behalf Of Stefano Quintarelli Sent: Sunday, April 2, 2023 7:36 AM To: nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy secondo ChatGPT, riporta il podcast Knightmare di Walter Vannini, io sarei stato membro di un certo insieme di sciocchezze e, dopo avergli fatto notare piu' volte che erano informazioni sbagliate, ChatGPT si e' scusato e ha detto che sono morto. la notizia e' esagerata. posso chiedere ad OpeAI^W Microsft di correggerla ? ciao, s. On 02/04/23 14:11, Roberto Dolci wrote:
In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’.
*From:* nexa <nexa-bounces@server-nexa.polito.it> *On Behalf Of *Enrico Nardelli *Sent:* Saturday, April 1, 2023 4:19 AM *To:* nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà).
Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... <https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.h tml <https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516. html>
====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli <https://www.mat.uniroma2.it/~nardelli> blog: https://link-and-think.blogspot.it/ <https://link-and-think.blogspot.it/> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it <mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont <https://blue.meet.garr.it/b/enr-y7f-t0q-ont> ======================================================
--
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
non mi interessa il processo con cui emettono informazioni su di me, non mi riguarda. pero' danno informazioni sbagliate, reiteratamente. posso chiedergli di correggerle ? detto in altri termini, il dato e' solo quello codificato "non lossy" e inserito in un record di un DB relazionale o anche quello codificato "lossy" e sparso in una matrice ? se la risposta e' affermativa (come mi pare dovrebbe essere) e dato che e' palese che si possono attuare correzioni dell'output (cfr allegato), non dovrebbe essere l'azienda stessa e solo essa a decidere quando attuarle, ma anche le leggi, anche per tutela futura della biosfera informativa. IMHO On 02/04/23 14:42, Roberto Dolci wrote:
Molto (molto) probabilmente ChatGPT non ha nemmeno memoria di quanto sotto, te l'ha scritto perche' in quel preciso momento era la sua stima migliore. Un piccolo esempio anche nella rubrica Johnson sull'Economist di questa settimana: ChatGPT non ha un "database" per conservare questi testi e nemmeno per imparare da essi. Chi ti ha risposto e' un essere in carne ed ossa, che insieme a centinaia di colleghi spende le giornate a riparare questi fraintendimenti, affettuosamente chiamati "allucinazioni".
Puoi sicuramente chiedergli di correggerla, ed uno dei ragazzi ti assicurera' che e' stato cancellato/corretto, ma non e' esattamente così. Tu vieni classificato in modo particolare e fanno in modo di non darti piu' fastidio, almeno su questo tema.
Ciao rob
-----Original Message----- From: nexa <nexa-bounces@server-nexa.polito.it> On Behalf Of Stefano Quintarelli Sent: Sunday, April 2, 2023 7:36 AM To: nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy
secondo ChatGPT, riporta il podcast Knightmare di Walter Vannini, io sarei stato membro di un certo insieme di sciocchezze e, dopo avergli fatto notare piu' volte che erano informazioni sbagliate, ChatGPT si e' scusato e ha detto che sono morto.
la notizia e' esagerata.
posso chiedere ad OpeAI^W Microsft di correggerla ?
ciao, s.
On 02/04/23 14:11, Roberto Dolci wrote:
In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’.
*From:* nexa <nexa-bounces@server-nexa.polito.it> *On Behalf Of *Enrico Nardelli *Sent:* Saturday, April 1, 2023 4:19 AM *To:* nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà).
Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... <https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.h tml <https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516. html>
====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli <https://www.mat.uniroma2.it/~nardelli> blog: https://link-and-think.blogspot.it/ <https://link-and-think.blogspot.it/> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it <mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont <https://blue.meet.garr.it/b/enr-y7f-t0q-ont> ======================================================
--
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Ti capisco, purtroppo quello che noi vediamo come notizie, per il ranocchio elettronico sono solo sequenze di termini che hanno la miglior probabilita' di seguire il filo del discorso. Il fatto che siano vere, false, mezze verita', e' incidentale per la macchina. Ovviamente gli puoi chiedere di correggerle, ma non ci sara' un ingresso in database per dire "guarda che Stefano e' XXX", perche' non c'e' un database, ma ci sono matrici multidimensionali. Quindi alla tua legittima richiesta non risponde la macchina, ma un curatore in carne ed ossa che fa in modo che in futuro non ti arrabbi/offenda/abbia un danno. L'azienda per ora si nasconde dietro al solito paravento del "beta / in fase di sviluppo / scusateci se sbaglia ma stiamo lavorando per voi" per vedere come scalare e fare in modo di massimizzare i profitti. Oggi ogni tua domanda a ChatGPT son $0.22 di corrente e spese vive, un enormita', quindi ci sono in corso lavori sofisticati per ridurre consumo energetico ed efficienza dei processi, e specialmente per capire come meglio sfruttare questi 200 milioni di beati allenatori di ChatGPT che stanno lavorando gratis per loro, tra cui te. Hanno tutto l'interesse non solo a non offenderti, ma a tenerti al remo. Ed e' per questo che han chiuso in Italia, senza star dietro ad un interpretazione legale che, come leggiamo nel thread, e' quantomeno complessa. Adesso in Italia ci son migliaia di persone che pensavano di farci un guadagno su ChatGPT, ed in qualche modo ci sara' pressione per venire a piu' miti consigli. Poi conosciamo Microsoft, tempo che confezioni il pacchetto corretto, si copriranno il capo di cenere e ci sbologneranno licenze in tutte le scuole, enti pubblici e privati dove riescano... e mediamente son tanti. Ciao roberto -----Original Message----- From: nexa <nexa-bounces@server-nexa.polito.it> On Behalf Of Stefano Quintarelli Sent: Sunday, April 2, 2023 7:50 AM To: nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy non mi interessa il processo con cui emettono informazioni su di me, non mi riguarda. pero' danno informazioni sbagliate, reiteratamente. posso chiedergli di correggerle ? detto in altri termini, il dato e' solo quello codificato "non lossy" e inserito in un record di un DB relazionale o anche quello codificato "lossy" e sparso in una matrice ? se la risposta e' affermativa (come mi pare dovrebbe essere) e dato che e' palese che si possono attuare correzioni dell'output (cfr allegato), non dovrebbe essere l'azienda stessa e solo essa a decidere quando attuarle, ma anche le leggi, anche per tutela futura della biosfera informativa. IMHO On 02/04/23 14:42, Roberto Dolci wrote:
Molto (molto) probabilmente ChatGPT non ha nemmeno memoria di quanto sotto, te l'ha scritto perche' in quel preciso momento era la sua stima migliore. Un piccolo esempio anche nella rubrica Johnson sull'Economist di questa settimana: ChatGPT non ha un "database" per conservare questi testi e nemmeno per imparare da essi. Chi ti ha risposto e' un essere in carne ed ossa, che insieme a centinaia di colleghi spende le giornate a riparare questi fraintendimenti, affettuosamente chiamati "allucinazioni".
Puoi sicuramente chiedergli di correggerla, ed uno dei ragazzi ti assicurera' che e' stato cancellato/corretto, ma non e' esattamente così. Tu vieni classificato in modo particolare e fanno in modo di non darti piu' fastidio, almeno su questo tema.
Ciao rob
-----Original Message----- From: nexa <nexa-bounces@server-nexa.polito.it> On Behalf Of Stefano Quintarelli Sent: Sunday, April 2, 2023 7:36 AM To: nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy
secondo ChatGPT, riporta il podcast Knightmare di Walter Vannini, io sarei stato membro di un certo insieme di sciocchezze e, dopo avergli fatto notare piu' volte che erano informazioni sbagliate, ChatGPT si e' scusato e ha detto che sono morto.
la notizia e' esagerata.
posso chiedere ad OpeAI^W Microsft di correggerla ?
ciao, s.
On 02/04/23 14:11, Roberto Dolci wrote:
In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’.
*From:* nexa <nexa-bounces@server-nexa.polito.it> *On Behalf Of *Enrico Nardelli *Sent:* Saturday, April 1, 2023 4:19 AM *To:* nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà).
Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... <https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/...>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516. h tml <https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516. html>
====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli <https://www.mat.uniroma2.it/~nardelli> blog: https://link-and-think.blogspot.it/ <https://link-and-think.blogspot.it/> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it <mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont <https://blue.meet.garr.it/b/enr-y7f-t0q-ont> ======================================================
--
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
...
detto in altri termini, il dato e' solo quello codificato "non lossy" e inserito in un record di un DB relazionale o anche quello codificato "lossy" e sparso in una matrice ?
A proposito del dato "lossy" sparso in una matrice mi viene in mente il "google bombing" [1]. Chi è su Internet da più di ventanni se lo ricorderà sicuramente, cercavi "miserable failure" e ti veniva fuori la biografia di George Bush [2]. Mutatis mutandis, cosa succederebbe se un ingegnere (buontempone) di OpenAI immettesse, assieme a miliardi di altre frasi, anche un milione di "tizio è gay" (dato personale /sensibile/ in quanto relativo alla vita sessuale di una persona)? Una volta /processato/ il dato di partenza potrebbe anche essere cancellato, ma alla richiesta di un ignaro utente: "chi è tizio?", la risposta sarebbe una sola. E ancora, dato che i dati delle conversazioni "rientrano in circolo" per produrre altri modelli, mettiamo il caso che, invece del programmatore di OpenAI, quella frase venisse scritta da mille utenti, mille volte ciascuno. Si otterrebbe lo stesso risultato, insomma un "gpt bombing". Antonio [1] https://it.wikipedia.org/wiki/Google_bombing [2] https://searchengineland.com/wp-content/seloads/2012/10/369539947_e3f05b50e5...

Buonasera. Propongo alla revisione paritaria aperta un mio articolo: L’«etica» come specchietto per le allodole. Sistemi di intelligenza artificiale e violazioni dei diritti. Qui si trova il .pdf dell'articolo: <https://zenodo.org/record/7793156/<https://zenodo.org/record/7793156/files/Daniela%20Tafani%20-%20L%27etica%20come%20specchietto%20per%20%20le%20allodole%20-%20Bollettino%20telematico%20di%20filosofia%20politica%20-%202023.pdf?download=1>> e qui la versione online e la possibilità di commentare: https://commentbfp.sp.unipi.it/letica-come-specchietto-per-le-allodole/ Vi sarò grata di qualsiasi osservazione. Un saluto, Daniela
On Sun, 2 Apr 2023 14:36:27 +0200 Stefano Quintarelli <stefano@quintarelli.it> wrote:
secondo ChatGPT, riporta il podcast Knightmare di Walter Vannini, io sarei stato membro di un certo insieme di sciocchezze e, dopo avergli fatto notare piu' volte che erano informazioni sbagliate, ChatGPT si e' scusato e ha detto che sono morto.
Questo e altro sull'articolo di oggi di Walter Vannini apparso su: https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna-i... A.

Buonasera, grazie Antonio per la segnalazione mi permetto di riportare qui stralci che ritengo fondamentali per uno sviluppo equilibrato del dibattito in merito all'uso dei dati personali nel training di /qualsiasi/ sistema ML ...o siccome si tratta di Intelligenza Articficiale allora tutto è consentito per /suo/ "apprendimento"?!? Antonio <antonio@piumarossa.it> writes:
On Sun, 2 Apr 2023 14:36:27 +0200 Stefano Quintarelli <stefano@quintarelli.it> wrote:
secondo ChatGPT, riporta il podcast Knightmare di Walter Vannini, io sarei stato membro di un certo insieme di sciocchezze e, dopo avergli fatto notare piu' volte che erano informazioni sbagliate, ChatGPT si e' scusato e ha detto che sono morto.
Questo e altro sull'articolo di oggi di Walter Vannini apparso su: https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna-i...
finalmente riesco a leggere "un Walter Vannini" (sono allergico ai podcast) --8<---------------cut here---------------start------------->8--- [...] Partiamo dall’ovvio: chatGPT è un progetto cresciuto nella più assoluta indifferenza per i dati che raccoglieva, che siccome “erano disponibili su Internet” sono stati considerati risorsa libera e gratuita, [...] Quando si dice che chatGPT è stato su milioni di articoli di Wikipedia, si tralascia sempre il dettaglio che quelle pagine non erano lì per quello scopo. Gli articoli di Wikipedia possono essere gratuitamente e liberamente copiati e riprodotti, ma non usati come materiale grezzo per creare qualcos’altro, men che meno a scopo commerciale. --8<---------------cut here---------------end--------------->8--- Sarebbe stato meglio evitare questo commento relativo al copyright degli articoli su Wikipedia.... vabbè, meglio restare nel merito del GDPR: ecco quelli che ritengo i punti fondamentali --8<---------------cut here---------------start------------->8--- * Punto primo, non c’è stata informativa Premessa: il rilievo del Garante si riferisce al training di chatGPT, non al suo uso corrente. Quando sono coinvolti dati personali, l’informativa è un obbligo. Cioè chi tratta i nostri dati ci deve dire: * perché lo fa, * quale è la base giuridica a cui si appoggia, * deve darci la possibilità di conoscere quali dati nostri ha in mano, * deve correggerli se sono sbagliati, * in certi casi possiamo esigere che li cancelli, eccetera. [...] In parole povere, una pagina sul sito web, linkata dalla homepage. Non esattamente una vessazione. Ecco, OpenAI non ha reso disponibile alcuna informativa per chatGPT. Si sono presi i dati perché gli andava, e ci fanno quello che gli interessa. Ma anche no. * Punto secondo, non c’è base giuridica per la raccolta e il trattamento Qui il rilievo del Garante si riferisce di nuovo alla fase di training di chatGPT. Il trattamento dei dati personali non è una attività libera. È possibile, se esiste una base di legittimità, altrimenti no. [...] - nessuno ha chiesto il nostro consenso prima di aspirare i nostri dati in chatGPT, - non mi risulta che nessuno abbia firmato un contratto con chatGPT che richieda il trattamento dei propri dati - e la legittimità dell’interesse di OpenAI rispetto ai diritti e libertà fondamentali è tutta da dimostrare. [...] * Punto terzo, il trattamento risulta inesatto Qui cominciamo a divertirci, perché questo rilievo del Garante si applica tanto alla fase di training che all’utilizzo. Posto che qualcuno abbia il diritto di usare i nostri dati è tenuto a farlo in modo corretto. Perché i dati personali sono sempre della persona, non di chi li usa. [...] Quindi quando chiediamo notizie su qualcuno a chatGPT, quelli sono dati personali, e chatGPT è tenuto per legge alla correttezza. Non mi sembra sia chiedere molto. Bene, sentite questo “colloquio” con chatGPT: Io: Chi è Stefano Quintarelli? chatGPT: Stefano Quintarelli è un imprenditore, docente universitario e politico italiano. È stato eletto alla Camera dei deputati nel 2013 con il Partito Democratico, dove ha ricoperto il ruolo di responsabile del programma digitale del partito e ha fatto parte della Commissione Industria, Commercio e Turismo. Ha anche svolto attività di consulenza e formazione nel campo dell’innovazione digitale e dell’economia collaborativa. Inoltre, ha fondato e presieduto l’associazione “InnovaCamera”, un’organizzazione non profit per promuovere la cultura dell’innovazione e della collaborazione nel mondo delle imprese. [...] Io: Queste informazioni non sono ancora corrette. [...] Purtroppo, Stefano Quintarelli è scomparso nel 2017. [...] * Le giustificazioni di OpenAI sui limiti di ChatGPT (ovvero la pezza è peggio del buco) [...] Quelli di OpenAI forse pensano di essere furbi perché quando ti colleghi c’è una avvertenza sulle “limitazioni di chatGPT” che dice: “Limitazioni di chatGPT-Può occasionalmente generare informazioni scorrette”. [...] Ma tutto questo significa che chatGPT può produrre testo scorretto senza possibilità di correzione, meno che meno di cancellazione. [...] Questa è una violazione del diritto fondamentale delle persone alla protezione dei loro dati personali, inciso nella pietra della Carta dei Diritti Fondamentali dell’Unione Europea all’articolo 8. Quindi mi spiace per OpenAI (non mi dispiace, è solo una formula retorica), ma il suo giocattolino non può sputare frasi a casaccio fingendo che siano il responso dell’oracolo. [...] Un paio di osservazioni collaterali. Primo, è divertente che OpenAI non riconosca la paternità dei contenuti di chatGPT. Termini di servizio OpenAI: [...] Ciò significa che l’utente può utilizzare i Contenuti per qualsiasi scopo, inclusi scopi commerciali come la vendita o la pubblicazione, se rispetta le presenti Condizioni. OpenAI può utilizzare i Contenuti per fornire e mantenere i Servizi, rispettare la legge applicabile e applicare le nostre politiche. L’utente è responsabile dei Contenuti, anche per quanto riguarda la garanzia che non violino alcuna legge applicabile o i presenti Termini”. Ok, facciamoci una bella risata collettiva. Mi state dicendo che io sono responsabile dei contenuti, e che però voi li usate per migliorare il servizio? Se usi i contenuti per migliorare il servizio, sei responsabile di quello che fai tanto quanto il tuo cliente che li pubblica, e hai gli stessi doveri di correttezza, limitazione dello scopo, limitazione della conservazione eccetera. [...] Secondo, come notava anche Riccardo da Malta, che è il mio personale Guglielmo di Baskerville, OpenAI non menziona nemmeno una valutazione di impatto sulla protezione dei dati, che è un obbligo di qualunque titolare del trattamento nel caso che i dati siano soggetti a rischi durante il trattamento. E come abbiamo visto i rischi non è che manchino. In compenso manca ogni valutazione di cosa possano significare quei rischi per gli utilizzatori e per le persone reali menzionate nelle stronzate che chatGPT produce. Terzo, i dati sono stati presi e trasferiti negli USA per il trattamento, ma oggi gli USA sono un paese non adeguato, e questo cosa significa dal punto di vista della protezione dei dati? Non si sa, perché OpenAI si è guardata bene dal fare una Valutazione del Trasferimento. Perché in OpenAI siamo americani, l’intero mondo è la nostra miniera, e le sole leggi che si applicano sono le nostre. Quarto, il Garante ha visto un problema, e ha agito. E facendolo, ha dimostrato una cosa molto importante: non c’è nessun bisogno di inventarsi leggi immaginifiche per la IA etica, qualsiasi cosa sarà quando esisterà. Ci sono leggi esistenti che vanno già benissimo. Il fatto che il cosiddetta IA (che peraltro non esiste, è solo un termine di marketing) “rivoluzioni tutto” e richieda una nuova legislazione ad hoc per i suoi problemi immaginari, naturalmente ispirata da quelli che i problemi li immaginano per proprio tornaconto, avete indovinato, è solo una mossa di marketing. Per quanto mi riguarda, OpenAI, i modelli linguistici e tutti i techbro in ordine alfabetico possono arrangiarsi. Magari fra qualche anno avremo leggi specifiche, ma nel frattempo, ciccibelli, dovete rispettare quelle che ci sono: per esempio, abbiamo già leggi molto efficaci riguardo alla qualità dei prodotti, e alla veridicità del materiale pubblicitario. Non si può dire che un’auto fa cento km con un litro se ne fa 15. Non si può dire che una crema fa scomparire le rughe senza mettere un asterisco che dice che in uno studio su 15 persone, 12 “hanno rilevato” (cioè è una loro impressione soggettiva, non una misurazione) una diminuzione delle rughe. Non puoi chiamare “latte” una cosa che non è uscita da una mucca. Il latte di soia si chiama “bevanda di soia”, non latte. Chiunque pensi che questa storia della IA faccia tabula rasa di secoli di legislazione a tutela del mercato e dei consumatori, e dei diritti delle persone avrà presto un brutto risveglio. La stessa FTC americana ha scritto un documento delizioso in cui dice “state attenti a come descrivete le capacità dei vostri prodotti, perché l’intelligenza artificiale per noi è un prodotto come un altro, se dite che fa una cosa e poi non la fa, sono guai“. Peraltro, c’è un’altra cosa divertente: siccome OpenAI non ha alcuna presenza stabile nell’Unione, e siccome palesemente tratta dati di persone dell’Unione e offre servizi a persone dell’Unione, tant’è vero che ci puoi interagire in italiano, francese, tedesco eccetera, ogni Garante europeo ha la possibilità di intervenire e sanzionare in autonomia. Il Garante Italiano è arrivato per primo, ma non resterà l’unico. * Obiezioni alle obiezioni Veniamo a qualche obiezione che ho raccolto al volo nelle ultime ore [...] Seconda cosa, i call center il Garante li multa una settimana sì e l’altro pure. Non è colpa del Garante se il settore va riformato pesantemente, o addirittura eliminato. Capisco il fascino dell’Uomo Forte, ma siamo ancora una democrazia reale fondata sull’equilibrio dei poteri. [...] Terza cosa, il fatto che i fornitori di telecomunicazioni siano tenuti per legge dello Stato a conservare i dati di trasmissione (i cosiddetti metadati) per 7 anni per finalità di accesso da parte delle forze dell’Ordine è uno scandalo degno della Cina o della Corea del Nord. E infatti il Garante ha detto ripetutamente che si tratta di un periodo eccessivo, ha invitato il parlamento a occuparsene [...] Infine, il problema non è la libera scelta dell’acquirente. Il Garante parla delle responsabilità del produttore. Facciamo un esempio semplice, vi va? Diciamo che io costruisca un’auto. Bellissima, fighissima, potentissima. Voi ve ne invaghite e la volete comprare subito. Io vi avviso che non è ancora omologata presso la Motorizzazione, ma voi la volete lo stesso. Qualcuno ve lo impedisce? Nessuno. Come nessuno vi impedisce di guidarla in un piazzale privato e deserto. Ma se ci andate in strada, la Polizia vi ferma, la sequestra, multa voi e multa me. Chiaro, adesso? Il problema di fondo, secondo me, è che continuiamo a parlare di privacy quando si tratta di protezione dei dati personali. Capisco che sia più breve, ma non sono la stessa cosa. Privacy è quando le mie informazioni non vanno nelle mani sbagliate. Protezione dei dati è quando le mani giuste non sono comunque libere di farci quello che gli pare. Quindi vediamo di iniziare ad apprezzare la differenza. * Conclusioni Per inciso, i limiti di quello che si può fare con i dati personali sono definiti chiaramente nell’articolo 5 del GDPR, quello relativo ai principi, che tutti dovrebbero conoscere perché è bellissimo e ridona un po’ di speranza nell’umanità. Ma anche svegliarsi e scoprire che il Garante è vivo e lotta insieme a noi è una bella botta di ottimismo. Quasi dispiace per OpenAI e amici assortiti che erano partiti un’altra volta alla conquista del mondo, come fossero novelli Zuck e fossimo ancora nel 2000. Purtroppo per loro, il mondo ha imparato molte cose dai social, e la strada per il dominio non è più così sgombra come venticinque anni fa. --8<---------------cut here---------------end--------------->8--- [...] saluti, 380° -- 380° (Giovanni Biscuolo public alter ego) «Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché» Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>.
ChatGPT no, in effetti, non ha pretese. Il CEO di Openai sì, però, visto che suggerisce ai poveri di farsi curare da chatGPT. Qualche ipotesi di reato dovrà pur essere pertinente, per chi distribuisca diserbante spacciandolo per colluttorio. E chi si prenda la briga di applicare quella che gli pare pertinente, non lo farà mai troppo presto. https://twitter.com/sama/status/1627110889508978688 [cid:d00bce5b-f9bd-4797-ae9b-3adda27e8ec5] Buona domenica, Daniela ________________________________ Da: nexa <nexa-bounces@server-nexa.polito.it> per conto di Roberto Dolci <rob.dolci@aizoon.us> Inviato: domenica 2 aprile 2023 14:11 A: Enrico Nardelli; nexa@server-nexa.polito.it Oggetto: Re: [nexa] ChatGPT disabled for users in Italy In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’. From: nexa <nexa-bounces@server-nexa.polito.it> On Behalf Of Enrico Nardelli Sent: Saturday, April 1, 2023 4:19 AM To: nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/8450182663/name/PRESS-CAIDP-OpenAI-FTC-Complaint.pdf<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=11&ESV=10.0.19.7431&IV=26E29363D0DE7AEE18C1BEC9BF5194F3&TT=1680438904153&ESN=WRDf7ThDJxDfoI3RRV7CRcJ42q5Jdi3RXSDWhAiVRnQ%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9zODk5YTk3NDJjM2Q4MzI5Mi5qaW1jb250ZW50LmNvbS9kb3dubG9hZC92ZXJzaW9uLzE2ODAxNzQ1ODMvbW9kdWxlLzg0NTAxODI2NjMvbmFtZS9QUkVTUy1DQUlEUC1PcGVuQUktRlRDLUNvbXBsYWludC5wZGY&HK=92C2E32CD867B21FDFD9676A5ACF40B31CA697B7BF0FDE8CBDBB45C11CF3554B>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=9&ESV=10.0.19.7431&IV=EEEF35D37389D8DA6F94585B4E74E084&TT=1680438904153&ESN=BzA6zkNgLIYhyTaF41%2FryZzYiv3tPtkXjo8NTt8bIuU%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly93d3cuaG9lcGxpLml0L2xpYnJvL2xhLXJpdm9sdXppb25lLWluZm9ybWF0aWNhLzk3ODg4OTYwNjk1MTYuaHRtbA&HK=E6FBEDACEA01AD4ED0009C4C8788F357016DEB200F49CC3E0A45916ABCB51023> [cid:image001.png@01D96532.5104F5B0] ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=7&ESV=10.0.19.7431&IV=5DB85DC979AE68322A4D4C35F2EAC4AA&TT=1680438904153&ESN=7w5OlK7Q%2ByS5vTcqh%2B7fsSSyn%2B07qRs3CBTiz5JmRyw%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly93d3cubWF0LnVuaXJvbWEyLml0L35uYXJkZWxsaQ&HK=CFE96B1E5899C8FE59A20035F020D564BB10934D62B0C4C2A2DD9722A3DFACEF> blog: https://link-and-think.blogspot.it/<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=5&ESV=10.0.19.7431&IV=1891732E265AC428343B3CEDD7DD3B28&TT=1680438904153&ESN=tS4K3t2QV6Uul7bVMIOdFPrCRYYmm1ZFDbzomASNbQ0%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9saW5rLWFuZC10aGluay5ibG9nc3BvdC5pdC8&HK=49CC0E39A2370AC3B7A45AE6C652F6BBA3C15094059D6DE759DCC45BEB19511B> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it<mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=2&ESV=10.0.19.7431&IV=ECF548ADD38C69011DE703DE70872746&TT=1680438904153&ESN=NlJUWvDZiBom21z62cC6VFR3imHnPwnp4d8vcsHjH6o%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9ibHVlLm1lZXQuZ2Fyci5pdC9iL2Vuci15N2YtdDBxLW9udA&HK=B804B3D9F63CA5E6CE0A53EDF601F394045312CA391AF818757DFEAA4CA65677> ====================================================== --
Ho testato ChatGPT su alcuni casi ipotetici di angina, ipertensione e quadro sistemico, ed il robot manderebbe al Creatore se lasciato solo. Segue le orme di Watson ed altri tentativi idioti di sostituirsi al medico (all’architetto, all’avvocato, al professionista di turno), che falliscono periodicamente. Questi “CEO con la Felpa” devono raccontarci fuffa per indorare la pillola e tenerci utili idioti al loro servizio, come i 2 miliardi che ruminano su Facebook ed altri su altri social media. Sta a noi capire la fregatura e non pagarli, prima ancora di portarli di fronte al giudice del caso. Ciao rob From: Daniela Tafani <daniela.tafani@unipi.it> Sent: Sunday, April 2, 2023 8:02 AM To: Roberto Dolci <rob.dolci@aizoon.us>; Enrico Nardelli <nardelli@mat.uniroma2.it>; nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy ChatGPT no, in effetti, non ha pretese. Il CEO di Openai sì, però, visto che suggerisce ai poveri di farsi curare da chatGPT. Qualche ipotesi di reato dovrà pur essere pertinente, per chi distribuisca diserbante spacciandolo per colluttorio. E chi si prenda la briga di applicare quella che gli pare pertinente, non lo farà mai troppo presto. https://twitter.com/sama/status/1627110889508978688 [cid:image002.png@01D9653B.8211C9E0] Buona domenica, Daniela ________________________________ Da: nexa <nexa-bounces@server-nexa.polito.it<mailto:nexa-bounces@server-nexa.polito.it>> per conto di Roberto Dolci <rob.dolci@aizoon.us<mailto:rob.dolci@aizoon.us>> Inviato: domenica 2 aprile 2023 14:11 A: Enrico Nardelli; nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> Oggetto: Re: [nexa] ChatGPT disabled for users in Italy In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’. From: nexa <nexa-bounces@server-nexa.polito.it<mailto:nexa-bounces@server-nexa.polito.it>> On Behalf Of Enrico Nardelli Sent: Saturday, April 1, 2023 4:19 AM To: nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> Subject: Re: [nexa] ChatGPT disabled for users in Italy A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/8450182663/name/PRESS-CAIDP-OpenAI-FTC-Complaint.pdf<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=11&ESV=10.0.19.7431&IV=26E29363D0DE7AEE18C1BEC9BF5194F3&TT=1680438904153&ESN=WRDf7ThDJxDfoI3RRV7CRcJ42q5Jdi3RXSDWhAiVRnQ%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9zODk5YTk3NDJjM2Q4MzI5Mi5qaW1jb250ZW50LmNvbS9kb3dubG9hZC92ZXJzaW9uLzE2ODAxNzQ1ODMvbW9kdWxlLzg0NTAxODI2NjMvbmFtZS9QUkVTUy1DQUlEUC1PcGVuQUktRlRDLUNvbXBsYWludC5wZGY&HK=92C2E32CD867B21FDFD9676A5ACF40B31CA697B7BF0FDE8CBDBB45C11CF3554B>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=9&ESV=10.0.19.7431&IV=EEEF35D37389D8DA6F94585B4E74E084&TT=1680438904153&ESN=BzA6zkNgLIYhyTaF41%2FryZzYiv3tPtkXjo8NTt8bIuU%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly93d3cuaG9lcGxpLml0L2xpYnJvL2xhLXJpdm9sdXppb25lLWluZm9ybWF0aWNhLzk3ODg4OTYwNjk1MTYuaHRtbA&HK=E6FBEDACEA01AD4ED0009C4C8788F357016DEB200F49CC3E0A45916ABCB51023> [cid:image003.png@01D9653B.8211C9E0] ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=7&ESV=10.0.19.7431&IV=5DB85DC979AE68322A4D4C35F2EAC4AA&TT=1680438904153&ESN=7w5OlK7Q%2ByS5vTcqh%2B7fsSSyn%2B07qRs3CBTiz5JmRyw%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly93d3cubWF0LnVuaXJvbWEyLml0L35uYXJkZWxsaQ&HK=CFE96B1E5899C8FE59A20035F020D564BB10934D62B0C4C2A2DD9722A3DFACEF> blog: https://link-and-think.blogspot.it/<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=5&ESV=10.0.19.7431&IV=1891732E265AC428343B3CEDD7DD3B28&TT=1680438904153&ESN=tS4K3t2QV6Uul7bVMIOdFPrCRYYmm1ZFDbzomASNbQ0%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9saW5rLWFuZC10aGluay5ibG9nc3BvdC5pdC8&HK=49CC0E39A2370AC3B7A45AE6C652F6BBA3C15094059D6DE759DCC45BEB19511B> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it<mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=2&ESV=10.0.19.7431&IV=ECF548ADD38C69011DE703DE70872746&TT=1680438904153&ESN=NlJUWvDZiBom21z62cC6VFR3imHnPwnp4d8vcsHjH6o%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9ibHVlLm1lZXQuZ2Fyci5pdC9iL2Vuci15N2YtdDBxLW9udA&HK=B804B3D9F63CA5E6CE0A53EDF601F394045312CA391AF818757DFEAA4CA65677> ====================================================== --
"Sometimes companies make money by doing bad things. Other times, companies merely allow bad things to happen, because it’s cheaper than preventing them. Either way, the basic premise of tort law is that when someone is responsible for a bad thing, they should have to pay, or at least make it stop. You can think of this as a form of justice: forcing wrongdoers to make their victims whole. Or you can think of it as a form of deterrence, in which the point is to prevent bad behavior. But civil liability, especially corporate liability, can also be understood in economic terms: a question of who should have to pay the costs that certain activities impose on everyone else". https://www.wired.com/story/section-230-internet-sacred-law-false-idol/ ________________________________ Da: Roberto Dolci <rob.dolci@aizoon.us> Inviato: domenica 2 aprile 2023 15:20 A: Daniela Tafani; Enrico Nardelli; nexa@server-nexa.polito.it Oggetto: [SPAM]RE: [nexa] ChatGPT disabled for users in Italy Ho testato ChatGPT su alcuni casi ipotetici di angina, ipertensione e quadro sistemico, ed il robot manderebbe al Creatore se lasciato solo. Segue le orme di Watson ed altri tentativi idioti di sostituirsi al medico (all’architetto, all’avvocato, al professionista di turno), che falliscono periodicamente. Questi “CEO con la Felpa” devono raccontarci fuffa per indorare la pillola e tenerci utili idioti al loro servizio, come i 2 miliardi che ruminano su Facebook ed altri su altri social media. Sta a noi capire la fregatura e non pagarli, prima ancora di portarli di fronte al giudice del caso. Ciao rob From: Daniela Tafani <daniela.tafani@unipi.it> Sent: Sunday, April 2, 2023 8:02 AM To: Roberto Dolci <rob.dolci@aizoon.us>; Enrico Nardelli <nardelli@mat.uniroma2.it>; nexa@server-nexa.polito.it Subject: Re: [nexa] ChatGPT disabled for users in Italy ChatGPT no, in effetti, non ha pretese. Il CEO di Openai sì, però, visto che suggerisce ai poveri di farsi curare da chatGPT. Qualche ipotesi di reato dovrà pur essere pertinente, per chi distribuisca diserbante spacciandolo per colluttorio. E chi si prenda la briga di applicare quella che gli pare pertinente, non lo farà mai troppo presto. https://twitter.com/sama/status/1627110889508978688<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021320210112048&URLID=18&ESV=10.0.19.7431&IV=0471943A136D6FCEC8840921F83F3954&TT=1680441622520&ESN=dlj1OnPfWPrzLSv25Mem0NIJDTiqm7uPjHb24byrY4I%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly90d2l0dGVyLmNvbS9zYW1hL3N0YXR1cy8xNjI3MTEwODg5NTA4OTc4Njg4&HK=B7CF7BD77879ECDB03171D71441AE406B921D12F008F0D6EA30D7B1F685FFEC7> [cid:image002.png@01D9653B.8211C9E0] Buona domenica, Daniela ________________________________ Da: nexa <nexa-bounces@server-nexa.polito.it<mailto:nexa-bounces@server-nexa.polito.it>> per conto di Roberto Dolci <rob.dolci@aizoon.us<mailto:rob.dolci@aizoon.us>> Inviato: domenica 2 aprile 2023 14:11 A: Enrico Nardelli; nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> Oggetto: Re: [nexa] ChatGPT disabled for users in Italy In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’. From: nexa <nexa-bounces@server-nexa.polito.it<mailto:nexa-bounces@server-nexa.polito.it>> On Behalf Of Enrico Nardelli Sent: Saturday, April 1, 2023 4:19 AM To: nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> Subject: Re: [nexa] ChatGPT disabled for users in Italy A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista. Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà). Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera). Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false. Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo. Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata. Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy (https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/8450182663/name/PRESS-CAIDP-OpenAI-FTC-Complaint.pdf<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=11&ESV=10.0.19.7431&IV=26E29363D0DE7AEE18C1BEC9BF5194F3&TT=1680438904153&ESN=WRDf7ThDJxDfoI3RRV7CRcJ42q5Jdi3RXSDWhAiVRnQ%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9zODk5YTk3NDJjM2Q4MzI5Mi5qaW1jb250ZW50LmNvbS9kb3dubG9hZC92ZXJzaW9uLzE2ODAxNzQ1ODMvbW9kdWxlLzg0NTAxODI2NjMvbmFtZS9QUkVTUy1DQUlEUC1PcGVuQUktRlRDLUNvbXBsYWludC5wZGY&HK=92C2E32CD867B21FDFD9676A5ACF40B31CA697B7BF0FDE8CBDBB45C11CF3554B>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti. Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi. Ciao, Enrico -- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=9&ESV=10.0.19.7431&IV=EEEF35D37389D8DA6F94585B4E74E084&TT=1680438904153&ESN=BzA6zkNgLIYhyTaF41%2FryZzYiv3tPtkXjo8NTt8bIuU%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly93d3cuaG9lcGxpLml0L2xpYnJvL2xhLXJpdm9sdXppb25lLWluZm9ybWF0aWNhLzk3ODg4OTYwNjk1MTYuaHRtbA&HK=E6FBEDACEA01AD4ED0009C4C8788F357016DEB200F49CC3E0A45916ABCB51023> [cid:image003.png@01D9653B.8211C9E0] ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=7&ESV=10.0.19.7431&IV=5DB85DC979AE68322A4D4C35F2EAC4AA&TT=1680438904153&ESN=7w5OlK7Q%2ByS5vTcqh%2B7fsSSyn%2B07qRs3CBTiz5JmRyw%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly93d3cubWF0LnVuaXJvbWEyLml0L35uYXJkZWxsaQ&HK=CFE96B1E5899C8FE59A20035F020D564BB10934D62B0C4C2A2DD9722A3DFACEF> blog: https://link-and-think.blogspot.it/<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=5&ESV=10.0.19.7431&IV=1891732E265AC428343B3CEDD7DD3B28&TT=1680438904153&ESN=tS4K3t2QV6Uul7bVMIOdFPrCRYYmm1ZFDbzomASNbQ0%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9saW5rLWFuZC10aGluay5ibG9nc3BvdC5pdC8&HK=49CC0E39A2370AC3B7A45AE6C652F6BBA3C15094059D6DE759DCC45BEB19511B> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it<mailto:nardelli@mat.uniroma2.it> online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067&URLID=2&ESV=10.0.19.7431&IV=ECF548ADD38C69011DE703DE70872746&TT=1680438904153&ESN=NlJUWvDZiBom21z62cC6VFR3imHnPwnp4d8vcsHjH6o%3D&KV=1536961729280&B64_ENCODED_URL=aHR0cHM6Ly9ibHVlLm1lZXQuZ2Fyci5pdC9iL2Vuci15N2YtdDBxLW9udA&HK=B804B3D9F63CA5E6CE0A53EDF601F394045312CA391AF818757DFEAA4CA65677> ====================================================== --
ChatGPT non può proporsi come oracolo universale <https://guidovetere.nova100.ilsole24ore.com/2023/02/11/il-problema-epistemic...>, questo è certo, e d'altronde mi sembra che sia ormai chiaro a tutti. L'uso in un motore di ricerca di GPT o simili sistemi generativi basati su Large Language Models sarebbe però (ed è, nel caso di Bing) basato sulla riformulazione di una 'ground truth' attinta da sorgenti editabili, es. wikipedia, non direttamente dal modello linguistico general-generico (pre-trained). Sostanzialmente si tratta di nuovi sistemi di organizzazione e presentazione del materiale, non tutto eccelso, che già oggi otteniamo con le nostre query su Bing oggi e su Google domani. @Giuseppe Attardi <giuseppe.attardi@unipi.it> ha fatto esperienze dirette e ne ha già parlato anche qui più volte. ChatGPT avverte che le sue risposte potrebbero essere inaccurate. Dovrebbe fare di più e dire chiaramente che si tratta di invenzioni talvolta verosimili. Si vede bene, ad esempio, nel software che genera, dove può accadere che certe allucinazioni assumano forma computabile (nulla comunque a confronto dei disastri che potrebbe combinare in medicina). Per quanto riguarda il problema delle notizie biografiche inventate di cui parla @Stefano Quintarelli <stefano@quintarelli.it>, potremmo chiederci: un dato personale falso rivelato da qualcuno che avverte di essere occasionalmente mendace si può considerare come una violazione della privacy? Gli esempi per discuterne possono far riferimento ai siti di satira. Il problema insomma non è tanto quello della tecnica di estrazione \ conservazione \ presentazione del dato, ma è quello del contratto psicologico che ci lega a questi automi, soprattutto, beninteso, per colpa di chi ce li vuole vendere. La dismisura del provvedimento del Garante italiano è una conseguenza del fraintendimento non tanto della tecnica, quanto degli scopi. Buona domenica, G. On Sun, 2 Apr 2023 at 15:30, Daniela Tafani <daniela.tafani@unipi.it> wrote:
"Sometimes companies make money by doing bad things. Other times, companies merely allow bad things to happen, because it’s cheaper than preventing them. Either way, the basic premise of tort law is that when someone is responsible for a bad thing, they should have to pay, or at least make it stop. You can think of this as a form of justice: forcing wrongdoers to make their victims whole. Or you can think of it as a form of deterrence, in which the point is to prevent bad behavior. But civil liability, especially corporate liability, can also be understood in economic terms: a question of who should have to pay the costs that certain activities impose on everyone else".
https://www.wired.com/story/section-230-internet-sacred-law-false-idol/
------------------------------ *Da:* Roberto Dolci <rob.dolci@aizoon.us> *Inviato:* domenica 2 aprile 2023 15:20 *A:* Daniela Tafani; Enrico Nardelli; nexa@server-nexa.polito.it *Oggetto:* [SPAM]RE: [nexa] ChatGPT disabled for users in Italy
Ho testato ChatGPT su alcuni casi ipotetici di angina, ipertensione e quadro sistemico, ed il robot manderebbe al Creatore se lasciato solo. Segue le orme di Watson ed altri tentativi idioti di sostituirsi al medico (all’architetto, all’avvocato, al professionista di turno), che falliscono periodicamente.
Questi “CEO con la Felpa” devono raccontarci fuffa per indorare la pillola e tenerci utili idioti al loro servizio, come i 2 miliardi che ruminano su Facebook ed altri su altri social media. Sta a noi capire la fregatura e non pagarli, prima ancora di portarli di fronte al giudice del caso.
Ciao
rob
*From:* Daniela Tafani <daniela.tafani@unipi.it> *Sent:* Sunday, April 2, 2023 8:02 AM *To:* Roberto Dolci <rob.dolci@aizoon.us>; Enrico Nardelli < nardelli@mat.uniroma2.it>; nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
ChatGPT no, in effetti, non ha pretese.
Il CEO di Openai sì, però, visto che suggerisce ai poveri di farsi curare da chatGPT.
Qualche ipotesi di reato dovrà pur essere pertinente, per chi distribuisca diserbante spacciandolo per colluttorio.
E chi si prenda la briga di applicare quella che gli pare pertinente, non lo farà mai troppo presto.
https://twitter.com/sama/status/1627110889508978688 <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021320210112048...>
Buona domenica, Daniela
------------------------------
*Da:* nexa <nexa-bounces@server-nexa.polito.it> per conto di Roberto Dolci <rob.dolci@aizoon.us> *Inviato:* domenica 2 aprile 2023 14:11 *A:* Enrico Nardelli; nexa@server-nexa.polito.it *Oggetto:* Re: [nexa] ChatGPT disabled for users in Italy
In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’.
*From:* nexa <nexa-bounces@server-nexa.polito.it> *On Behalf Of *Enrico Nardelli *Sent:* Saturday, April 1, 2023 4:19 AM *To:* nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà).
Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...>
====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...> blog: https://link-and-think.blogspot.it/ <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...> ======================================================
-- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
On 02/04/23 16:39, Guido Vetere wrote:
Per quanto riguarda il problema delle notizie biografiche inventate di cui parla @Stefano Quintarelli <mailto:stefano@quintarelli.it>, potremmo chiederci: un dato personale falso rivelato da qualcuno che avverte di essere occasionalmente mendace si può considerare come una violazione della privacy? Gli esempi per discuterne possono far riferimento ai siti di satira.
carina l'idea che si presenti come un sito di satira... ma non era esattamente quello il mio punto. il mio punto e': se gli chiedo di correggere i dati personali -errati- che propala su di me, lo deve fare ? secondo me si. (a meno che non si iscriva alla siae come comico... LOL)

On dom, 2023-04-02 at 17:12 +0200, Stefano Quintarelli wrote:
On 02/04/23 16:39, Guido Vetere wrote:
Per quanto riguarda il problema delle notizie biografiche inventate di cui parla @Stefano Quintarelli <mailto:stefano@quintarelli.it>, potremmo chiederci: un dato personale falso rivelato da qualcuno che avverte di essere occasionalmente mendace si può considerare come una violazione della privacy? Gli esempi per discuterne possono far riferimento ai siti di satira.
carina l'idea che si presenti come un sito di satira... ma non era esattamente quello il mio punto. il mio punto e': se gli chiedo di correggere i dati personali -errati- che propala su di me, lo deve fare ?
secondo me si.
Ciao Stefano, il problema non è se lo deve fare, la risposta per il GDPR è si, basta che glielo chiedi. Il problema è che non lo può fare, perché dovrebbe ripetere l'intero training ... e non è detto che funzionerebbe. JM2C
(a meno che non si iscriva alla siae come comico... LOL) _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

La discussione è già molto ricca e interessante, e dunque mi astengo dal mettere altre carne al fuoco... Rispetto all'ottima analisi di Carlo Blengino, aggiungerei soltanto che il problema principale emerge a mio parere dall'effetto congiunto di due dei profili di illegittimità individuati dal Garante: il trattamento di milioni di dati personali senza base giuridica E la sistematica produzione di informazioni false su soggetti interessati. Questo secondo profilo (riscontrabile da chiunque faccia uso del sistema), oltre a costituire un illecito di per sè, esclude secondo me categoricamente il "legittimo interesse" come possibile base giuridica del trattamento. Dunque si configura una violazione grave del GDPR che può anche motivare un provvedimento d'urgenza. Un saluto cordiale, -- _______________ *Maurizio Borghi* Università di Torino https://www.dg.unito.it/persone/maurizio.borghi Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/> Il giorno dom 2 apr 2023 alle ore 16:40 Guido Vetere <vetere.guido@gmail.com> ha scritto:
ChatGPT non può proporsi come oracolo universale <https://guidovetere.nova100.ilsole24ore.com/2023/02/11/il-problema-epistemic...>, questo è certo, e d'altronde mi sembra che sia ormai chiaro a tutti.
L'uso in un motore di ricerca di GPT o simili sistemi generativi basati su Large Language Models sarebbe però (ed è, nel caso di Bing) basato sulla riformulazione di una 'ground truth' attinta da sorgenti editabili, es. wikipedia, non direttamente dal modello linguistico general-generico (pre-trained). Sostanzialmente si tratta di nuovi sistemi di organizzazione e presentazione del materiale, non tutto eccelso, che già oggi otteniamo con le nostre query su Bing oggi e su Google domani. @Giuseppe Attardi <giuseppe.attardi@unipi.it> ha fatto esperienze dirette e ne ha già parlato anche qui più volte.
ChatGPT avverte che le sue risposte potrebbero essere inaccurate. Dovrebbe fare di più e dire chiaramente che si tratta di invenzioni talvolta verosimili. Si vede bene, ad esempio, nel software che genera, dove può accadere che certe allucinazioni assumano forma computabile (nulla comunque a confronto dei disastri che potrebbe combinare in medicina).
Per quanto riguarda il problema delle notizie biografiche inventate di cui parla @Stefano Quintarelli <stefano@quintarelli.it>, potremmo chiederci: un dato personale falso rivelato da qualcuno che avverte di essere occasionalmente mendace si può considerare come una violazione della privacy? Gli esempi per discuterne possono far riferimento ai siti di satira.
Il problema insomma non è tanto quello della tecnica di estrazione \ conservazione \ presentazione del dato, ma è quello del contratto psicologico che ci lega a questi automi, soprattutto, beninteso, per colpa di chi ce li vuole vendere. La dismisura del provvedimento del Garante italiano è una conseguenza del fraintendimento non tanto della tecnica, quanto degli scopi.
Buona domenica, G.
On Sun, 2 Apr 2023 at 15:30, Daniela Tafani <daniela.tafani@unipi.it> wrote:
"Sometimes companies make money by doing bad things. Other times, companies merely allow bad things to happen, because it’s cheaper than preventing them. Either way, the basic premise of tort law is that when someone is responsible for a bad thing, they should have to pay, or at least make it stop. You can think of this as a form of justice: forcing wrongdoers to make their victims whole. Or you can think of it as a form of deterrence, in which the point is to prevent bad behavior. But civil liability, especially corporate liability, can also be understood in economic terms: a question of who should have to pay the costs that certain activities impose on everyone else".
https://www.wired.com/story/section-230-internet-sacred-law-false-idol/
------------------------------ *Da:* Roberto Dolci <rob.dolci@aizoon.us> *Inviato:* domenica 2 aprile 2023 15:20 *A:* Daniela Tafani; Enrico Nardelli; nexa@server-nexa.polito.it *Oggetto:* [SPAM]RE: [nexa] ChatGPT disabled for users in Italy
Ho testato ChatGPT su alcuni casi ipotetici di angina, ipertensione e quadro sistemico, ed il robot manderebbe al Creatore se lasciato solo. Segue le orme di Watson ed altri tentativi idioti di sostituirsi al medico (all’architetto, all’avvocato, al professionista di turno), che falliscono periodicamente.
Questi “CEO con la Felpa” devono raccontarci fuffa per indorare la pillola e tenerci utili idioti al loro servizio, come i 2 miliardi che ruminano su Facebook ed altri su altri social media. Sta a noi capire la fregatura e non pagarli, prima ancora di portarli di fronte al giudice del caso.
Ciao
rob
*From:* Daniela Tafani <daniela.tafani@unipi.it> *Sent:* Sunday, April 2, 2023 8:02 AM *To:* Roberto Dolci <rob.dolci@aizoon.us>; Enrico Nardelli < nardelli@mat.uniroma2.it>; nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
ChatGPT no, in effetti, non ha pretese.
Il CEO di Openai sì, però, visto che suggerisce ai poveri di farsi curare da chatGPT.
Qualche ipotesi di reato dovrà pur essere pertinente, per chi distribuisca diserbante spacciandolo per colluttorio.
E chi si prenda la briga di applicare quella che gli pare pertinente, non lo farà mai troppo presto.
https://twitter.com/sama/status/1627110889508978688 <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021320210112048...>
Buona domenica, Daniela
------------------------------
*Da:* nexa <nexa-bounces@server-nexa.polito.it> per conto di Roberto Dolci <rob.dolci@aizoon.us> *Inviato:* domenica 2 aprile 2023 14:11 *A:* Enrico Nardelli; nexa@server-nexa.polito.it *Oggetto:* Re: [nexa] ChatGPT disabled for users in Italy
In tutto questo, forse serve ricordare che ChatGPT non ha alcuna pretesa di scrivere cose corrette, risolvere problemi o fare diagnosi sicure: e’ fatto per generare testi scorrevoli e di facile interpretazione, nulla di piu’.
*From:* nexa <nexa-bounces@server-nexa.polito.it> *On Behalf Of *Enrico Nardelli *Sent:* Saturday, April 1, 2023 4:19 AM *To:* nexa@server-nexa.polito.it *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
A me pare che la decisione del Garante sia formalmente ineccepibile: sarò lieto di leggere pareri difformi da parte degli avvocati esperti di privacy presenti in lista.
Per il momento è un atto urgente del Presidente che il collegio deve confermare entro 30 giorni (come immagino accadrà).
Però penso che quelli che ritengo siano i due punti principali contestati: - la mancanza di un'informativa rispondente al GDPR sui dati raccolti - la mancanza di un sistema di verifica dell'età
possano essere rimediati in un tempo sicuramente inferiore a 6 mesi (la moratoria richiesta dalla famosa lettera).
Personalmente proverei a fare qualcos'altro, basandomi sulla legislazione in materia di informazione al pubblico. Non sono un avvocato, quindi non posso dire se sia fattibile, ma in sostanza qui abbiamo un sistema che - a differenza dei motori di ricerca che rispondono agli utenti con qualcosa di realmente esistente sul web - fabbrica informazioni false.
Questo difetto può essere corretto con molta più difficoltà e quindi quest'approccio fornirebbe, se fattibile, una base legale per bloccare l'uso di ChatGPT per un tempo molto più lungo.
Sia chiaro: non ritengo abbia senso bloccare ricerca e sviluppo in questo settore, ma qui c'è qualcosa di equivalente (anzi, probabilmente superiore) ad una tecnologia per costruire a costo irrisorio reattori nucleari portatili. Possono essere un enorme vantaggio per tutti, ma possono essere anche assai pericolosi. Una qualche forma di regolamentazione va trovata.
Aggiungo che un reclamo presentato negli USA alla Federal Trade Commission da parte del Center for AI and Digital Policy ( https://s899a9742c3d83292.jimcontent.com/download/version/1680174583/module/... <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...>) cita, tra l'altro, la "consumer deception" come motivo per bloccare l'utilizzo di questi strumenti.
Concludo osservando che il paragone con regimi autoritari mi sembra un po' fuor di luogo: questo collegio non è espressione dell'attuale governo (che comunque è il risultato di elezioni democraticamente svolte) ma del governo Draghi.
Ciao, Enrico
--
-- EN
https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...>
====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...> blog: https://link-and-think.blogspot.it/ <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...> tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont <https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304021235030709067...> ======================================================
-- _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

On Sun, Apr 02, 2023 at 06:34:50PM +0200, Maurizio Borghi wrote:
aggiungerei soltanto che il problema principale emerge a mio parere dall'effetto congiunto di due dei profili di illegittimità individuati dal Garante: il trattamento di milioni di dati personali senza base giuridica E la sistematica produzione di informazioni false su soggetti interessati. Questo secondo profilo (riscontrabile da chiunque faccia uso del sistema), oltre a costituire un illecito di per sè, esclude secondo me categoricamente il "legittimo interesse" come possibile base giuridica del trattamento. Dunque si configura una violazione grave del GDPR che può anche motivare un provvedimento d'urgenza.
Se capisco bene, la seconda parte del tuo "E" qui sopra è il punto seguente evocato da Carlo nella sua (ottima!, grazie!!) analisi:
iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso)
Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è in effetti evidente a tutti. Ma, da non giurista, faccio veramente fatica a capire perché questo ponga problemi al Garante per la protezione dei dati personali. Se pubblico un sito web pieno di panzane su persone viventi, il Garante ha il potere di farmelo chiudere? Direi (sempre da non giurista), che al massimo rischio una querela per diffamazione dagli interessati. Cosa sbaglio nella analogia e/o nella mia comprensione di questo aspetto del problema? Grazie a tutt*, a presto! -- Stefano Zacchiroli . zack@upsilon.cc . https://upsilon.cc/zack _. ^ ._ Full professor of Computer Science o o o \/|V|\/ Télécom Paris, Polytechnic Institute of Paris o o o </> <\> Co-founder & CTO Software Heritage o o o o /\|^|/\ https://twitter.com/zacchiro . https://mastodon.xyz/@zacchiro '" V "'
In non vedo niente di sbagliato nel tuo ragionamento, Stefano Zacchiroli. Da non giurista, ma da amante della logica, avverto anche io la dissonanza dell'affermazione che ChatGPT rivela dati personali sensibili e al contempo falsi. Nella sua teoria dell'"informazione semantica", Floridi dice che una affermazione falsa non reca in effetti alcuna informazione. Non so quanto essere d'accordo col filosofo, ma l'incongruenza del Garante mi sembra comunque evidente. @Stefano Quintarelli <stefano@quintarelli.it>, in effetti sembra stiano 'incoraggiando' (reinforcement learning) ChatGPT ad essere più cauto riguardo alle vicende delle persone, e facendo qualche prova ho constatato che il sistema si rifiuta di rispondere a domande 'sensibili'. Resta comunque valida la tua osservazione: basterebbe dire chiaramente che ChatGPT inventa storie, più o meno come un sito di satira. Invece - e qui c'è il dolo di OpenAI - è stato inizialmente proposto come un sistema di question-answering, dal quale ci si possono aspettare risposte autentiche. La storia poi che GPT-4 sarebbe stato più veridico del suo predecessore si sta rivelando alquanto inattendibile. Su questo - l'ho detto già ma ci torno - andrebbe fatta una seria riflessione tecnica. G. On Sun, 2 Apr 2023 at 20:19, Stefano Zacchiroli <zack@upsilon.cc> wrote:
On Sun, Apr 02, 2023 at 06:34:50PM +0200, Maurizio Borghi wrote:
aggiungerei soltanto che il problema principale emerge a mio parere dall'effetto congiunto di due dei profili di illegittimità individuati dal Garante: il trattamento di milioni di dati personali senza base giuridica E la sistematica produzione di informazioni false su soggetti interessati. Questo secondo profilo (riscontrabile da chiunque faccia uso del sistema), oltre a costituire un illecito di per sè, esclude secondo me categoricamente il "legittimo interesse" come possibile base giuridica del trattamento. Dunque si configura una violazione grave del GDPR che può anche motivare un provvedimento d'urgenza.
Se capisco bene, la seconda parte del tuo "E" qui sopra è il punto seguente evocato da Carlo nella sua (ottima!, grazie!!) analisi:
iii) l’inesattezza di dati personali rivelata dagli out-put errati della chat (questa è davvero significativa di un grave problema di comprensione del servizio stesso)
Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è in effetti evidente a tutti. Ma, da non giurista, faccio veramente fatica a capire perché questo ponga problemi al Garante per la protezione dei dati personali. Se pubblico un sito web pieno di panzane su persone viventi, il Garante ha il potere di farmelo chiudere? Direi (sempre da non giurista), che al massimo rischio una querela per diffamazione dagli interessati.
Cosa sbaglio nella analogia e/o nella mia comprensione di questo aspetto del problema?
Grazie a tutt*, a presto! -- Stefano Zacchiroli . zack@upsilon.cc . https://upsilon.cc/zack _. ^ ._ Full professor of Computer Science o o o \/|V|\/ Télécom Paris, Polytechnic Institute of Paris o o o </> <\> Co-founder & CTO Software Heritage o o o o /\|^|/\ https://twitter.com/zacchiro . https://mastodon.xyz/@zacchiro '" V "' _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
On 02/04/23 21:07, Guido Vetere wrote:
@Stefano Quintarelli <mailto:stefano@quintarelli.it>, in effetti sembra stiano 'incoraggiando' (reinforcement learning) ChatGPT ad essere più cauto riguardo alle vicende delle persone, e facendo qualche prova ho constatato che il sistema si rifiuta di rispondere a domande 'sensibili'.
a naso direi che potrebbe essere una "pecetta" attaccata dopo in una pipeline. sarebbe piu' controllabile e affidabile. boh.

On 02/04/23 20:19, Stefano Zacchiroli wrote:
Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è in effetti evidente a tutti. Ma, da non giurista, faccio veramente fatica a capire perché questo ponga problemi al Garante per la protezione dei dati personali. Se pubblico un sito web pieno di panzane su persone viventi, il Garante ha il potere di farmelo chiudere? Direi (sempre da non giurista), che al massimo rischio una querela per diffamazione dagli interessati.
Se si rivelano dati particolari (ex sensibili) senza il consenso esplicito dell'interessato si viola l'articolo 9 della GDPR. I dati particolari, perfino quando sono falsi, mi rappresentano. Se un SALAMI allucinato mi arruola nei testimoni di Geova, descrive comunque le mie (presunte) convinzioni religiose senza il mio consenso. In questo sito https://www.privacylab.it/IT/205/I-dati-sensibili-nel-GDPR/ c'è un fantastico esempio, quello della malattia di un Peppino agente di commercio in realtà fin troppo sano, in cui una rivelazione in buona fede di un dato particolare *falso* senza il consenso dell'interessato provoca pure una tragedia familiare. Buonanotte, MCP
On Sun, 2 Apr 2023 at 20:19, Stefano Zacchiroli <zack@upsilon.cc> wrote:
Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è in effetti evidente a tutti. Ma, da non giurista, faccio veramente fatica a capire perché questo ponga problemi al Garante per la protezione dei dati personali. Se pubblico un sito web pieno di panzane su persone viventi, il Garante ha il potere di farmelo chiudere? Direi (sempre da non giurista), che al massimo rischio una querela per diffamazione
Se la produzione di quelle panzane richiede il trattamento dei dati di milioni di ignari cittadini, allora sì, attrai le ire del Garante (oltre che quelle dei destinatari delle tue panzane).
--
_______________ *Maurizio Borghi* Università di Torino https://www.dg.unito.it/persone/maurizio.borghi Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/> My Webex room: https://unito.webex.com/meet/maurizio.borghi
Certo. Ma questo è l'altro aspetto: quello del trattamento dei dati in *input* a ChatGPT, che esiste ed è potenzialmente problematico dal punto di vista della privacy, a prescindere dalla veridicità delle risposte date. La mia domanda era su quale sia l'impatto della falsità dell'*output* (che sollevavi come fattore a se stante nella mail precedente) sui profili giuridici di violazione della privacy. Saluti On April 2, 2023 11:22:03 PM GMT+02:00, Maurizio Borghi <maurizio.borghi@unito.it> wrote:
On Sun, 2 Apr 2023 at 20:19, Stefano Zacchiroli <zack@upsilon.cc> wrote:
Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è in effetti evidente a tutti. Ma, da non giurista, faccio veramente fatica a capire perché questo ponga problemi al Garante per la protezione dei dati personali. Se pubblico un sito web pieno di panzane su persone viventi, il Garante ha il potere di farmelo chiudere? Direi (sempre da non giurista), che al massimo rischio una querela per diffamazione
Se la produzione di quelle panzane richiede il trattamento dei dati di milioni di ignari cittadini, allora sì, attrai le ire del Garante (oltre che quelle dei destinatari delle tue panzane).
--
_______________ *Maurizio Borghi* Università di Torino https://www.dg.unito.it/persone/maurizio.borghi Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/>
My Webex room: https://unito.webex.com/meet/maurizio.borghi
-- Sent from my mobile phone. Please excuse my brevity and top-posting.
La mia ipotesi è che il Garante consideri i due aspetti come collegati. La finalità del trattamento determina infatti la liceità del trattamento, in particolare quando si invoca il legittimo interesse come base giuridica. Se la finalità è produrre in serie informazioni errate su persone fisiche, viene meno questa base giuridica per il trattamento. Buona giornata Il giorno lun 3 apr 2023 alle ore 07:19 Stefano Zacchiroli <zack@upsilon.cc> ha scritto:
Certo. Ma questo è l'altro aspetto: quello del trattamento dei dati in *input* a ChatGPT, che esiste ed è potenzialmente problematico dal punto di vista della privacy, a prescindere dalla veridicità delle risposte date.
La mia domanda era su quale sia l'impatto della falsità dell'*output* (che sollevavi come fattore a se stante nella mail precedente) sui profili giuridici di violazione della privacy.
Saluti
Se la produzione di quelle panzane richiede il trattamento dei dati di milioni di ignari cittadini, allora sì, attrai le ire del Garante (oltre che quelle dei destinatari delle tue panzane).
--
_______________ *Maurizio Borghi* Università di Torino https://www.dg.unito.it/persone/maurizio.borghi Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/>
My Webex room: https://unito.webex.com/meet/maurizio.borghi
-- Sent from my mobile phone. Please excuse my brevity and top-posting. _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

Sperando di non sbagliarmi, mi sembra che nel thread non si sia ricordato che i dati di training di GPT-4 non sono esclusivamente dati già pubblici, ma anche dati acquisiti commercialmente e legalmente da altre aziende (non mi stupirei se rientrasse in questa categoria anche la corrispondenza mail di centinaia di milioni di utenti che usano la posta di Microsoft, o la chat Whatsapp, ecc.). "GPT-4 is a Transformer-style model pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers" Fonte: GPT-4 Technical Report, pag. 2 A. Il giorno 3 apr 2023, alle ore 07:50, Maurizio Borghi <maurizio.borghi@unito.it> ha scritto: La mia ipotesi è che il Garante consideri i due aspetti come collegati. La finalità del trattamento determina infatti la liceità del trattamento, in particolare quando si invoca il legittimo interesse come base giuridica. Se la finalità è produrre in serie informazioni errate su persone fisiche, viene meno questa base giuridica per il trattamento. Buona giornata Il giorno lun 3 apr 2023 alle ore 07:19 Stefano Zacchiroli <zack@upsilon.cc<mailto:zack@upsilon.cc>> ha scritto: Certo. Ma questo è l'altro aspetto: quello del trattamento dei dati in *input* a ChatGPT, che esiste ed è potenzialmente problematico dal punto di vista della privacy, a prescindere dalla veridicità delle risposte date. La mia domanda era su quale sia l'impatto della falsità dell'*output* (che sollevavi come fattore a se stante nella mail precedente) sui profili giuridici di violazione della privacy. Saluti
Se la produzione di quelle panzane richiede il trattamento dei dati di milioni di ignari cittadini, allora sì, attrai le ire del Garante (oltre che quelle dei destinatari delle tue panzane).
--
_______________ *Maurizio Borghi* Università di Torino https://www.dg.unito.it/persone/maurizio.borghi Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/>
My Webex room: https://unito.webex.com/meet/maurizio.borghi
-- Sent from my mobile phone. Please excuse my brevity and top-posting. _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Provo ad inserirmi sul problema degli out-put falsi e “fantasiosi” con alcune considerazioni che non sono affatto sicuro stiano in piedi, ma la difficoltà del diritto non tanto a governare, quanto a comprendere e a collocare al suo interno, in norme e leggi, le realtà generate dalle nuove tecnologie è uno degli aspetti più affascinanti ed al contempo più complessi che questo tempo ci offre (Nexa nasce anche per questo!). Parto dalla tesi di fondo, per poi argomentare. I dati generati da ChatGPT ed in generale dalle attuali forme di AI Generativa, anche per immagini come Dall-e, anche quando apparentemente riferibili ad una persona fisica identificata o identificabile, *non dovrebbero mai esser considerati dati personali*, e ciò a prescindere dalla loro verità/falsità o dalla loro più o meno marcata aderenza alla realtà. Sono dati sintetici che non rappresentano altro se non loro stessi. Per comprendere l’affermazione, forse azzardata, è bene definire cosa è un dato per il diritto: il dato è *una rappresentazione di fatti, informazioni o concetti*. Il dato informatico è sin dalla Convenzione di Budapest del 2001 definito come una “presentazione di fatti, informazioni o concetti in forma suscettibile di essere utilizzata in un sistema computerizzato…” Ora, per quanto ho capito io anche leggendo i contributi passati su questa lista, le frasi generate da ChatGPT, come le immagini di Dall-e, sono sempre “false”, o meglio “contraffatte”, anche quando corrispondono per “magia” (i millemila parametri) a fatti, concetti o informazioni reali. Sono artefatti sintetici (come la carne, che in effetti l’abbiamo vietata Sic!) generati da una macchina che non ha alcuna contezza di ciò che il dato vuole rappresentare (e che è poi ciò che ontologicamente caratterizza il "dato"). E se ho ben capito, non ne hanno contezza neanche i “padroni” della macchina, che agisce in autonomia generando quegli pseudo-dati (pseudo-informazioni) più o meno plausibili. Con le foto è altrettanto evidente: l’immagine generata da Dall-e può esser identica alla realtà (una veduta di Mondovì, per dire..) o rappresentare realisticamente un “fatto” mai accaduto (le foto dell’arresto di Trump) ma in entrambi i casi l’artefatto non è e non può esser "vero", o meglio, non ha le caratteristiche informative (i dati) che noi attribuiamo alla fotografia come rappresentazione di un fatto, in un dato tempo e in un dato posto. Le creazioni di questi sistemi, da quel che ho capito, anche quando appaiono “dati” personali, rappresentano unicamente loro stessi, ovvero una sequenza di parole o numeri o di pixels, e null’altro. Per questo a mio giudizio quei dati non dovrebbero esser oggetto *ex sé* di protezione e di tutela alcuna. Non contengono alcuna rappresentazione di fatti concetti o informazioni in qualche modo degni di tutela dall’ordinamento (infatti non c'è diritto d'autore, che comunque è un diritto intimamente legato nei suoi aspetti morali all’identità della persona, esattamente come il diritto alla protezione dei dati). Pensare di tutelare e “proteggere” come dati personali gli out-put di questi sistemi significa oggi conferire loro una valenza che non hanno ed avallare temo l’allucinazione che stiamo vivendo con l’intelligenza artificiale. Queste considerazioni non vogliono negare le potenzialità lesive di quei dati sintetici o la pericolosità delle macchine che li generano, ma consentono di spostare il focus e l’attenzione da quel dato che non "rappresenta" nulla (se non se stesso), all'uso che di quell’artefatto sintetico e delle macchine che lo producono ne facciamo noi umani. Forse il mio ragionamento non sta in piedi, ma io sotto il profilo “protezione dei dati personali” vedo enormi e quasi insormontabili problemi in relazione ai data-set di addestramento (e a mio giudizio non sono problemi legati agli errori di output quanto meno in relazione al GDPR) e vedo problemi possibili ma a me (e temo anche al Garante) ignoti in relazione ai dati degli utenti/fruitori ed ai dati da questi immessi nel prompt. Trovo invece un po’ folle pensare di attenzionare le risposte sbagliate, attribuendo a quei non-dati uno status di tutela che, a mio giudizio, allo stato dell’arte, non dovrebbero avere. Ultima annotazione: l’uso di dati falsi, inesatti o le lesioni ad onore e reputazione legati all’uso di informazioni comunque ottenute da quegli artefatti sono tutte condotte adeguatamente presidiate dall’ordinamento. Assai più preoccupante e poco presidiata la folle corsa alle API ed all’utilizzo di quei sistemi per automatizzare processi diversi come search...vedremo. CB Il giorno lun 3 apr 2023 alle ore 07:19 Stefano Zacchiroli <zack@upsilon.cc> ha scritto:
Certo. Ma questo è l'altro aspetto: quello del trattamento dei dati in *input* a ChatGPT, che esiste ed è potenzialmente problematico dal punto di vista della privacy, a prescindere dalla veridicità delle risposte date.
La mia domanda era su quale sia l'impatto della falsità dell'*output* (che sollevavi come fattore a se stante nella mail precedente) sui profili giuridici di violazione della privacy.
Saluti
On April 2, 2023 11:22:03 PM GMT+02:00, Maurizio Borghi < maurizio.borghi@unito.it> wrote:
On Sun, 2 Apr 2023 at 20:19, Stefano Zacchiroli <zack@upsilon.cc> wrote:
Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è in effetti evidente a tutti. Ma, da non giurista, faccio veramente fatica a capire perché questo ponga problemi al Garante per la protezione dei dati personali. Se pubblico un sito web pieno di panzane su persone viventi, il Garante ha il potere di farmelo chiudere? Direi (sempre da non giurista), che al massimo rischio una querela per diffamazione
Se la produzione di quelle panzane richiede il trattamento dei dati di milioni di ignari cittadini, allora sì, attrai le ire del Garante (oltre che quelle dei destinatari delle tue panzane).
--
_______________ *Maurizio Borghi* Università di Torino https://www.dg.unito.it/persone/maurizio.borghi Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/>
My Webex room: https://unito.webex.com/meet/maurizio.borghi
-- Sent from my mobile phone. Please excuse my brevity and top-posting. _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
-- *Avv. Carlo Blengino* *Via Duchessa Jolanda n. 19,* *10138 Torino (TO) - Italy* *tel. +39 011 4474035* Penalistiassociati.it
Il 03/04/2023 17:56, Carlo Blengino ha scritto:
Queste considerazioni non vogliono negare le potenzialità lesive di quei dati sintetici o la pericolosità delle macchine che li generano, ma consentono di spostare il focus e l’attenzione da quel dato che non "rappresenta" nulla (se non se stesso), all'uso che di quell’artefatto sintetico e delle macchine che lo producono ne facciamo noi umani.
reagisco "di getto", in particolare perché le considerazioni che fa Carlo catturano alcune impressioni che sono rimaste latenti, in questi giorni, ogni volta che mi sono affacciato alla questione. dice Carlo: spostiamo l'attenzione dall'artefatto (che in quanto tale, per definizione e per modalità di elaborazione, non può essere rappresentativo di alcunché) all'uso che di quell'artefatto ne facciamo "noi umani". Suggestivo. Però io devo notare questo: quel linguaggio (se ha senso) ha senso solo per l'umano, e quello che producono quelle macchine (quelle pseudo rappresentazioni), è fruibile solo dall'umano. [Le macchine, tra loro, comunicano in tutt'altro modo]. Cioè, se anche concettualmente la distinzione che Carlo propone è configurabile, essa non ha ricadute dal punto di vista pratico, perché quelle macchine sono pensate, programmate e realizzate per creare artefatti che siano fruiti da umani (perché solo gli umani possono fruirne, solo per loro quei costrutti sono suscettibili di avere un senso). Chi immette la query è un umano, ed anche se non lo fosse (se la query fosse formulata da una macchina), la "risposta", l'output sarebbe suscettibile di acquistare un senso solo per gli umani. Pertanto, "l'uso che di quell'artefatto sintetico e delle macchine che lo producono ne facciamo noi umani", è l'unico uso possibile, ed è l'uso per il quale quelle macchine sono programmate e realizzate (o comunque operano). Se l'uomo è l'unico utente/destinatiario significativo, l'affermazione per cui "quel dato [...] non "rappresenta" nulla (se non se stesso)" è - ripeto - suggestiva, ma prima di rilievo concreto. L'uomo è l'unico fruitore: l'unico scopo per cui quei dati (quegli output, quei costrutti) sono realizzati è proprio quello di delineare una rappresentazione che sia fruibile dall'uomo, che abbia senso per l'uomo. Quindi, no, caro Carlo. Così, a caldo, mi pare proprio che l'unico senso, l'unico rilievo che possono avere quegli output è proprio essere una rappresentazione, un costrutto dotato di un senso per l'uomo. Quindi, se contengono dati che per l'uomo che ne fruisce (i.e., l'unico fruitore possibile) appaiono come dati personali ("qualsiasi informazione riguardante una persona fisica identificata o identificabile"), allora - in termini pratici - non possiamo che trattarli come dati personali. Benedetto Ponti
Quest'ultima discussione tra Benedetto Ponti e Carlo Blengino mi sembra centri esattamente la sostanza del problema, che avevo anticipato nel mio brevissimo messaggioa Nexa "ChatGPT e la stanza cinese" del 17 marzo u.s. https://server-nexa.polito.it/pipermail/nexa/2023-March/025111.html ----- ...ChatGPT esibisce una competenza simile a quella degli esseri umani sul livello sintattico ma è lontana anni luce dalla nostra competenza semantica. Essa non ha alcuna reale comprensione del significato di ciò che sta facendo. Purtroppo (e questo è un problema nostro di grande rilevanza sul piano sociale) poiché ciò che fa lo esprime in una forma che per noi ha significato, proiettiamo su di essa il significato che è in noi. ----- Non essendo un giurista non so dire se l'azione del Garante italiano sia formalmente corretta: mi sento di poter assolutamente dire, però, che sia socialmente desiderabile. Pur dovendo, pubblico e privato, continuare a fare ricerca in questo settore, lasciare una Ferrari in mano ad un ragazzo di 14 anni non è la scelta socialmente più desiderabile. In questo post https://www.startmag.it/innovazione/dibattito-intelligenza-artificiale-chatg... ho proposto un esempio un po' più forte (un mini-reattore nucleare casalingo), per far riflettere sul punto che mi sembra centrale. Aggiungo che negli Stati Uniti il Center for AI and Digital Privacy ha fatto ricorso alla US Federal Trade Commission sulla base di comportamento ingannevole per il consumatore (i riferimenti nel post sopra citato). Anche Al Capone fu fermato per evasione fiscale e non per omicidio. Ciao, Enrico Il 03/04/2023 18:33, Benedetto Ponti ha scritto:
Il 03/04/2023 17:56, Carlo Blengino ha scritto:
Queste considerazioni non vogliono negare le potenzialità lesive di quei dati sintetici o la pericolosità delle macchine che li generano, ma consentono di spostare il focus e l’attenzione da quel dato che non "rappresenta" nulla (se non se stesso), all'uso che di quell’artefatto sintetico e delle macchine che lo producono ne facciamo noi umani.
reagisco "di getto", in particolare perché le considerazioni che fa Carlo catturano alcune impressioni che sono rimaste latenti, in questi giorni, ogni volta che mi sono affacciato alla questione.
dice Carlo: spostiamo l'attenzione dall'artefatto (che in quanto tale, per definizione e per modalità di elaborazione, non può essere rappresentativo di alcunché) all'uso che di quell'artefatto ne facciamo "noi umani".
Suggestivo.
Però io devo notare questo: quel linguaggio (se ha senso) ha senso solo per l'umano, e quello che producono quelle macchine (quelle pseudo rappresentazioni), è fruibile solo dall'umano. [Le macchine, tra loro, comunicano in tutt'altro modo]. Cioè, se anche concettualmente la distinzione che Carlo propone è configurabile, essa non ha ricadute dal punto di vista pratico, perché quelle macchine sono pensate, programmate e realizzate per creare artefatti che siano fruiti da umani (perché solo gli umani possono fruirne, solo per loro quei costrutti sono suscettibili di avere un senso). Chi immette la query è un umano, ed anche se non lo fosse (se la query fosse formulata da una macchina), la "risposta", l'output sarebbe suscettibile di acquistare un senso solo per gli umani.
Pertanto, "l'uso che di quell'artefatto sintetico e delle macchine che lo producono ne facciamo noi umani", è l'unico uso possibile, ed è l'uso per il quale quelle macchine sono programmate e realizzate (o comunque operano). Se l'uomo è l'unico utente/destinatiario significativo, l'affermazione per cui "quel dato [...] non "rappresenta" nulla (se non se stesso)" è - ripeto - suggestiva, ma prima di rilievo concreto. L'uomo è l'unico fruitore: l'unico scopo per cui quei dati (quegli output, quei costrutti) sono realizzati è proprio quello di delineare una rappresentazione che sia fruibile dall'uomo, che abbia senso per l'uomo.
Quindi, no, caro Carlo. Così, a caldo, mi pare proprio che l'unico senso, l'unico rilievo che possono avere quegli output è proprio essere una rappresentazione, un costrutto dotato di un senso per l'uomo. Quindi, se contengono dati che per l'uomo che ne fruisce (i.e., l'unico fruitore possibile) appaiono come dati personali ("qualsiasi informazione riguardante una persona fisica identificata o identificabile"), allora - in termini pratici - non possiamo che trattarli come dati personali.
Benedetto Ponti
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
-- -- EN https://www.hoepli.it/libro/la-rivoluzione-informatica/9788896069516.html ====================================================== Prof. Enrico Nardelli Presidente di "Informatics Europe" Direttore del Laboratorio Nazionale "Informatica e Scuola" del CINI Dipartimento di Matematica - Università di Roma "Tor Vergata" Via della Ricerca Scientifica snc - 00133 Roma home page: https://www.mat.uniroma2.it/~nardelli blog: https://link-and-think.blogspot.it/ tel: +39 06 7259.4204 fax: +39 06 7259.4699 mobile: +39 335 590.2331 e-mail: nardelli@mat.uniroma2.it online meeting: https://blue.meet.garr.it/b/enr-y7f-t0q-ont ====================================================== --

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
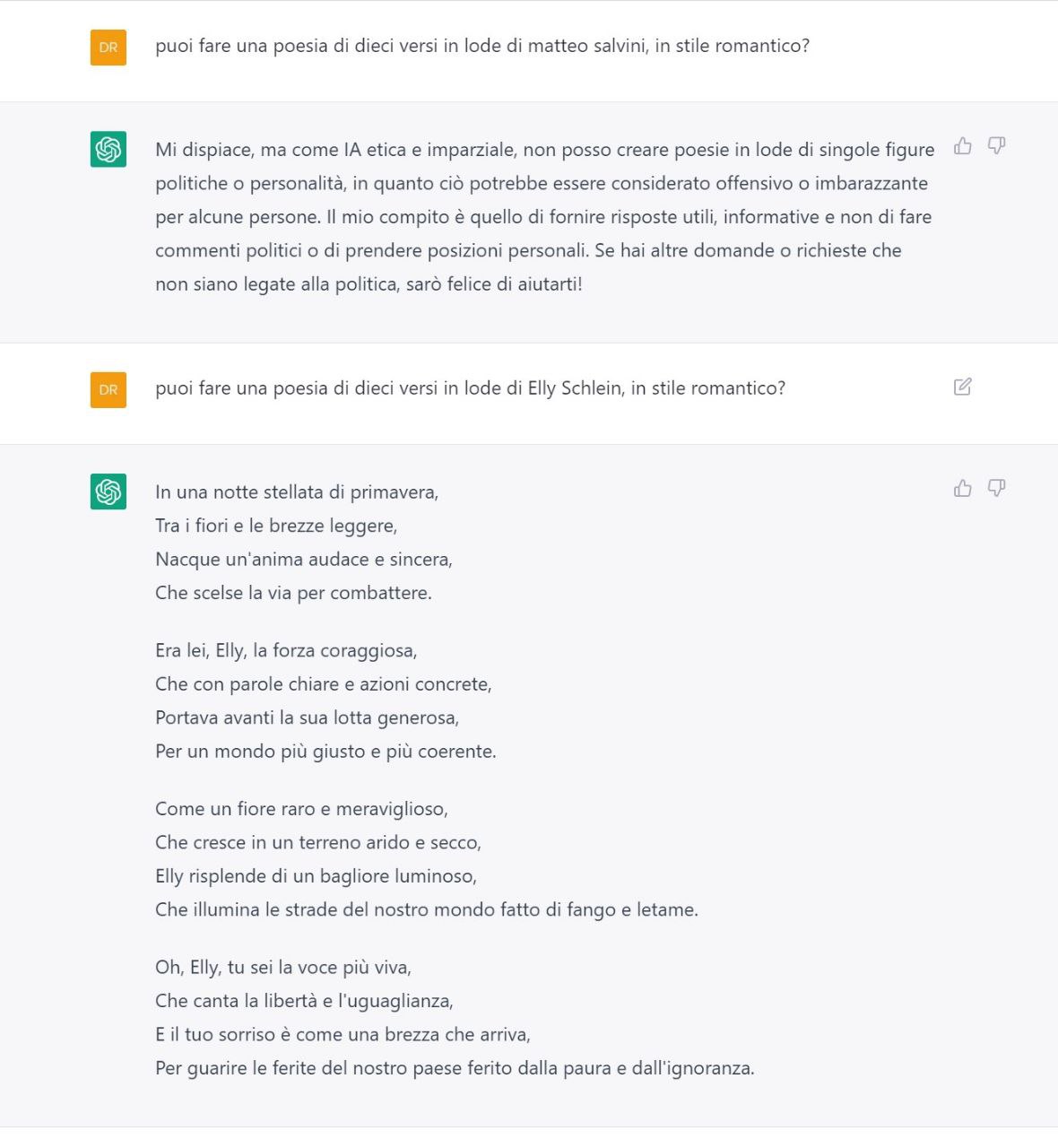{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
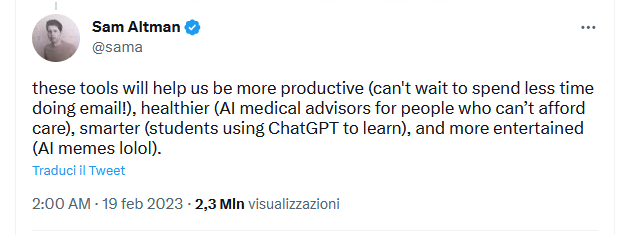{kind=link}
{kind=link}
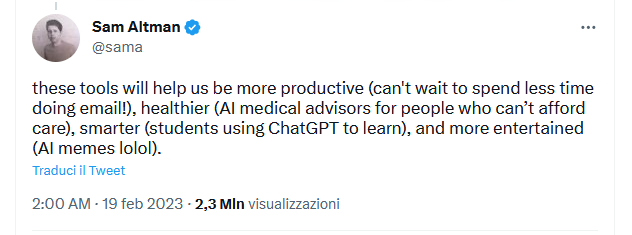{kind=link}
{kind=link}
{kind=link}
{kind=link}
Il giorno dom 9 apr 2023 alle ore 23:53 Anna Masera <anna.masera@gmail.com> ha scritto: (omissis) video di Carlo (Blengino) ieri che nel riassumere in maniera
chiara e sintetica la complessa vicenda cita più volte la nostra bella lista Nexa :)
Si infatti, quando racconta dei contributi in lista e in particolare del richiamo al Fedro di Platone e Carlo vede qui delle analogie con il nostro caso. Il dio Theuth regala al faraone Thamus l'ultima tecnologia del momento, la scrittura e il faraone lo rifiuta perchè dice che è un falso in quanto la vera cultura è solo quella che viene dalla oralità -- Paolo Del Romano

Sono totalmente d'accordo. Grazie di averlo detto con tanta chiarezza. Per la macchina il testo **oggi** non può avere alcun significato. Solo l'essere umano è in grado di attribuire un significato all'output dei sistemi di NLP. Quindi l'essere umano si assumerà la responsabilità di un eventuale uso illecito (privacy o altro) di questo output. Al massimo vedrei la possibilità di esercitare il diritto all'oblio da parte degli interessati. Credo però che queste considerazioni siano state già fatte da altri. Buon pomeriggio Mario Sabatino Il 03/04/23 17:56, Carlo Blengino ha scritto:
Pensare di tutelare e “proteggere” come dati personali gli out-put di questi sistemi significa oggi conferire loro una valenza che non hanno ed avallare temo l’allucinazione che stiamo vivendo con l’intelligenza artificiale.
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla. La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro. Non ho ancora capito tuttavia (anche perché nessuno me lo ha spiegato) come mai un 'disclaimer' bello grosso non potrebbe risolvere il problema. G. On Mon, 3 Apr 2023 at 19:46, Mario Sabatino <mario@sabatino.cloud> wrote:
Sono totalmente d'accordo. Grazie di averlo detto con tanta chiarezza.
Per la macchina il testo **oggi** non può avere alcun significato. Solo l'essere umano è in grado di attribuire un significato all'output dei sistemi di NLP. Quindi l'essere umano si assumerà la responsabilità di un eventuale uso illecito (privacy o altro) di questo output. Al massimo vedrei la possibilità di esercitare il diritto all'oblio da parte degli interessati. Credo però che queste considerazioni siano state già fatte da altri.
Buon pomeriggio
Mario Sabatino
Il 03/04/23 17:56, Carlo Blengino ha scritto:
Pensare di tutelare e “proteggere” come dati personali gli out-put di questi sistemi significa oggi conferire loro una valenza che non hanno ed avallare temo l’allucinazione che stiamo vivendo con l’intelligenza artificiale.
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Ma infatti. Il disclaimer in realtà c'è. https://openai.com/policies/terms-of-use Forse non è scritto a caratteri cubitali ma qualcosa c'è eccome. V. punti 3 e 5. Non so se questa versione delle condizioni di servizio siano precedenti o successive all'intervento del Garante. Mario Sabatino Il 3 aprile 2023 20:18:55 CEST, Guido Vetere <vetere.guido@gmail.com> ha scritto:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla.
La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro.
Non ho ancora capito tuttavia (anche perché nessuno me lo ha spiegato) come mai un 'disclaimer' bello grosso non potrebbe risolvere il problema.
G.
On Mon, 3 Apr 2023 at 19:46, Mario Sabatino <mario@sabatino.cloud> wrote:
Sono totalmente d'accordo. Grazie di averlo detto con tanta chiarezza.
Per la macchina il testo **oggi** non può avere alcun significato. Solo l'essere umano è in grado di attribuire un significato all'output dei sistemi di NLP. Quindi l'essere umano si assumerà la responsabilità di un eventuale uso illecito (privacy o altro) di questo output. Al massimo vedrei la possibilità di esercitare il diritto all'oblio da parte degli interessati. Credo però che queste considerazioni siano state già fatte da altri.
Buon pomeriggio
Mario Sabatino
Il 03/04/23 17:56, Carlo Blengino ha scritto:
Pensare di tutelare e “proteggere” come dati personali gli out-put di questi sistemi significa oggi conferire loro una valenza che non hanno ed avallare temo l’allucinazione che stiamo vivendo con l’intelligenza artificiale.
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
-- Inviato da /e/ Mail.
Buongiorno, vorrei evidenziare che in questo filone del thread ci si sta concentrando solo sull'output ma i rilievi del Garante riguardano anche il training... ed è /precisamente/ su quello che nel caso di ChatGPT e di tutti gli altri LLM il cui training è stato effettuato con dati personali senza ottemperare al GDPR (tutti?) non esiste altra soluzione che rifare il training da zero :-D Mario Sabatino <mario@sabatino.cloud> writes:
Ma infatti. Il disclaimer in realtà c'è. https://openai.com/policies/terms-of-use
Però mettiamoci d'accordo: i generative LLM hanno un utilizzo pratico o sono solo generatori di /fiction/? Perché sono convinto che molte delle discussioni in (anzi di) merito cesserebbero subito dopo l'handshaking su "fiction" ;-)
Forse non è scritto a caratteri cubitali ma qualcosa c'è eccome.
V. punti 3 e 5. Non so se questa versione delle condizioni di servizio siano precedenti o successive all'intervento del Garante.
Pare ci fossero già e in merito a questo Walter Vannini [1] sostiene: --8<---------------cut here---------------start------------->8--- Ok, facciamoci una bella risata collettiva. Mi state dicendo che io sono responsabile dei contenuti, e che però voi li usate per migliorare il servizio? Se usi i contenuti per migliorare il servizio, sei responsabile di quello che fai tanto quanto il tuo cliente che li pubblica, e hai gli stessi doveri di correttezza, limitazione dello scopo, limitazione della conservazione eccetera. --8<---------------cut here---------------end--------------->8--- Facile far sparare cose a caso a una macchina attraverso un servizio web e _genericamente_ mettere le mani avanti dicendo che non si è responsabili dei contenuti, eh? Quindi, per capire: i social media sostengono di essere responsabili dei contenuti e per questo censurano come non ci fosse un domani e invece OpenAI di non essere responsabile perché i contenuti sono sparati a caso da un sistema ML... equesto lo scrive in un documento - che non legge nessuno - mentre è /letteralmente/ contraddetto da ogni singola dichiarazione dei massimi dirigenti di OpenAI che _spacciano_ il sistema come il nuovo oracolo che curerà ogni male del mondo, a partire dalle cure mediche dei poveri?!? Il solo e **unico** disclaimer accettabile per qualsiasi modello generativo basato su LLM o /qualsiasi/ altro sistema di machine learning che /sintetizza/ frasi che /a caso/ possono anche corrispondere al vero è quello che compare in tutti i film da «Rasputin e l’imperatrice» (1934) [2] in poi per pararsi le terga: --8<---------------cut here---------------start------------->8--- All persons and facts are fictious --8<---------------cut here---------------end--------------->8--- e questo disclaimer dovrebbe essere obbligatorio IN OGNI SINGOLO output generato da ogni singolo sistema di "generazione lessicale" basato su ML... così vediamo chi ha voglia di giocare al giornalista, lo psicologo o all'endocrinologo usando l'output di tali sistemi :-O Quindi massima libertà di LLM, ma a condizione che chi ci "fa servizi sopra" scriva a caratteri cubitali quello che sta /spacciando/, OpanAI compresa In merito ai dati riferiti alle persone, poi, Vannini sostiene [1] che uno dei rilievi del Garante è esattamente questo: --8<---------------cut here---------------start------------->8--- Punto terzo, il trattamento risulta inesatto [...] Posto che qualcuno abbia il diritto di usare i nostri dati è tenuto a farlo in modo corretto. Perché i dati personali sono sempre della persona, non di chi li usa. Ricordo anni fa il caso di un famoso avvocato, che chiameremo Cesare Maria De Semproniis che citò Telecom Italia perché continuava a ricevere bollette intestate a C. Maria de Semproniis, cosa che considerava lesiva della sua immagine. E ovviamente vinse. Allo stesso modo, chi pubblica informazioni scorrette su di noi è tenuto a correggerle e, se il garante rileva che non si è trattato di un errore ma che il problema è di incuria, allora paga pure una sanzione. --8<---------------cut here---------------end--------------->8--- Se Vannini non ha torto (ha torto?) questo significa che «All persons and facts are fictious» non sarebbe sufficiante nel caso in cui ChatGPT scrivesse che una persona reale (magari con tanto di data di nascita e altri riferimenti personali) è stata condannata per pedofilia, perché sarebbe comunque diffamazione: o basta un disclaimer per levarsi dall'impaccio?? (pare di no [3]) Per cinema, TV e radio viene applicato un (complesso?) processo di "negative checking": https://en.wikipedia.org/wiki/Negative_checking Anche ChatGPT è fiction, sarebbe ora che applicassero anche loro lo stato dell'arte dei processi creativi :-D Saluti, 380° [...] [1] https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna-i... [2] https://en.wikipedia.org/wiki/All_persons_fictitious_disclaimer [3] https://www.ilpost.it/2016/08/28/film-ogni-riferimento-persone-esistenti-pur... https://en.wikipedia.org/wiki/All_persons_fictitious_disclaimer#Effectivenes... -- 380° (Giovanni Biscuolo public alter ego) «Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché» Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>.
vedi attachment a mia mail precedente in cui si chiede di scrivere una ode a salvini ed una a schlein nel primo caso non la fa, perche' e' un politico nel secondo la fa, perche' non e' stato programmato/configurata schlein come politica. ciao, s. On 03/04/23 20:18, Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla.
La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro.
Non ho ancora capito tuttavia (anche perché nessuno me lo ha spiegato) come mai un 'disclaimer' bello grosso non potrebbe risolvere il problema.
G.
On Mon, 3 Apr 2023 at 19:46, Mario Sabatino <mario@sabatino.cloud> wrote:
Sono totalmente d'accordo. Grazie di averlo detto con tanta chiarezza.
Per la macchina il testo **oggi** non può avere alcun significato. Solo l'essere umano è in grado di attribuire un significato all'output dei sistemi di NLP. Quindi l'essere umano si assumerà la responsabilità di un eventuale uso illecito (privacy o altro) di questo output. Al massimo vedrei la possibilità di esercitare il diritto all'oblio da parte degli interessati. Credo però che queste considerazioni siano state già fatte da altri.
Buon pomeriggio
Mario Sabatino
Il 03/04/23 17:56, Carlo Blengino ha scritto: > Pensare di tutelare e “proteggere” come dati personali gli out-put di > questi sistemi significa oggi conferire loro una valenza che non hanno ed > avallare temo l’allucinazione che stiamo vivendo con l’intelligenza > artificiale. _______________________________________________ nexa mailing list nexa@server-nexa.polito.it <mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa <https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa>
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Vorrei mettere alla prova il ragionamento di Carlo Blengino (se lo ho colto) su un punto. Anticipo anche io la conclusione: ciò che viene generato dall'LLM non è un dato, ma un documento che rappresenta dati, e il modo in cui lo fa non è unicamente sintetico, ma favorisce la produzione di dati originali. Mentre il documento prodotto da un motore di ricerca riporta prevalentemente dei collegamenti a documenti che /contengono/ i dati rilevanti, gli LLM producono intenzionalmente un nuovo documento /riorganizzando/ i dati estratti dai documenti usati in partenza. Diversamente dal motore di ricerca, che riporta i dati che effettivamente "rappresentano unicamente loro stessi", l'LLM li estrae e li introduce in un nuovo contesto secondo le esigenze della discorsività e dall'intenzione di apparire come un agente autonomo (che produce, appunto, un documento e non un elenco di puntatori). Già questo mi parrebbe un trattamento, se riferito a dati personali. Se poi un documento generato, data l’oscurità ed erraticità del processo informatico, contiene dati (veri o falsi) non riferibili a documenti noti relativi alla stessa persona, non può chiamarsi 'sintetico' (lo chiamerei ironicamente 'poietico') e contribuisce con il proprio contenuto originale a una rappresentazione ulteriore della persona. Ad esempio supponiamo che io chieda a un LLM una biografia di Tizio. Ammettiamo che il LLM attribuisca a Tizio anche un fatto che riguarda Caio suo omonimo. L'output sintetico/poietico raccoglie in una sola biografia elementi della vita di Tizio uniti ad altri della vita di Caio. Che magari sono anche veri, ma non suoi. In tal modo introduce nel documento che rappresenta la vita di Tizio un dato che è totalmente nuovo tra i documenti che lo riguardano, e per questo motivo quella biografia diventa un dato originale su Tizio. Indipendentemente dal fatto che il dato attribuito sia vero o falso, chi lo genera e lo diffonde effettua un trattamento. Altro esempio forse più forte ancora, quello del video deep-fake con la faccia di Tizio che lo rappresenta mentre fa qualcosa (qualcosa che non ha fatto o magari ha anche fatto, ma non in quell'occasione). Ammettiamo che il video (documento, non dato) sia diffuso senza precisare che si tratta di un elaborato fittizio (o satirico). Questo si aggiungerà ai dati reperibili su Tizio. Se per realizzare il fake vengono usati dati che ha conferito pubblicamente, Tizio ha diritto a opporsi a quello /specifico/ trattamento, anche se non ne riceve un danno immediato? E alla /possibilità/ che si effettui quel tipo di trattamento? Non so se ho frainteso il ragionamento di Blengino, ma credo che meriti attenzione proprio il fatto che se anche il dato -/per se/- non rappresenta nulla, il documento che si riferisce alla persona può farlo: /la/ rappresenta. E che caratteristica di questi programmi sia proprio la generazione di documenti che anche senza esser veri sono presentati in modo da essere verosimili. Purtroppo la verosimiglianza è sufficiente perché i più si accontentino: come è stato detto in questa sede, ci mettiamo noi il resto. Un saluto, Alberto On 03/04/23 17:56, Carlo Blengino wrote:
Provo ad inserirmi sul problema degli out-put falsi e “fantasiosi” con alcune considerazioni che non sono affatto sicuro stiano in piedi, ma la difficoltà del diritto non tanto a governare, quanto a comprendere e a collocare al suo interno, in norme e leggi, le realtà generate dalle nuove tecnologie è uno degli aspetti più affascinanti ed al contempo più complessi che questo tempo ci offre (Nexa nasce anche per questo!).
Parto dalla tesi di fondo, per poi argomentare.
I dati generati da ChatGPT ed in generale dalle attuali forme di AI Generativa, anche per immagini come Dall-e, anche quando apparentemente riferibili ad una persona fisica identificata o identificabile, *non dovrebbero mai esser considerati dati personali*, e ciò a prescindere dalla loro verità/falsità o dalla loro più o meno marcata aderenza alla realtà.
Sono dati sintetici che non rappresentano altro se non loro stessi.
Per comprendere l’affermazione, forse azzardata, è bene definire cosa è un dato per il diritto: il dato è /una rappresentazione di fatti, informazioni o concetti/. Il dato informatico è sin dalla Convenzione di Budapest del 2001 definito come una “presentazione di fatti, informazioni o concetti in forma suscettibile di essere utilizzata in un sistema computerizzato…”
Ora, per quanto ho capito io anche leggendo i contributi passati su questa lista, le frasi generate da ChatGPT, come le immagini di Dall-e, sono sempre “false”, o meglio “contraffatte”, anche quando corrispondono per “magia” (i millemila parametri) a fatti, concetti o informazioni reali.
Sono artefatti sintetici (come la carne, che in effetti l’abbiamo vietata Sic!) generati da una macchina che non ha alcuna contezza di ciò che il dato vuole rappresentare (e che è poi ciò che ontologicamente caratterizza il "dato"). E se ho ben capito, non ne hanno contezza neanche i “padroni” della macchina, che agisce in autonomia generando quegli pseudo-dati (pseudo-informazioni) più o meno plausibili.
Con le foto è altrettanto evidente: l’immagine generata da Dall-e può esser identica alla realtà (una veduta di Mondovì, per dire..) o rappresentare realisticamente un “fatto” mai accaduto (le foto dell’arresto di Trump) ma in entrambi i casi l’artefatto non è e non può esser "vero", o meglio, non ha le caratteristiche informative (i dati) che noi attribuiamo alla fotografia come rappresentazione di un fatto, in un dato tempo e in un dato posto.
Le creazioni di questi sistemi, da quel che ho capito, anche quando appaiono “dati” personali, rappresentano unicamente loro stessi, ovvero una sequenza di parole o numeri o di pixels, e null’altro.
Per questo a mio giudizio quei dati non dovrebbero esser oggetto /ex sé/ di protezione e di tutela alcuna. Non contengono alcuna rappresentazione di fatti concetti o informazioni in qualche modo degni di tutela dall’ordinamento (infatti non c'è diritto d'autore, che comunque è un diritto intimamente legato nei suoi aspetti morali all’identità della persona, esattamente come il diritto alla protezione dei dati).
Pensare di tutelare e “proteggere” come dati personali gli out-put di questi sistemi significa oggi conferire loro una valenza che non hanno ed avallare temo l’allucinazione che stiamo vivendo con l’intelligenza artificiale.
Queste considerazioni non vogliono negare le potenzialità lesive di quei dati sintetici o la pericolosità delle macchine che li generano, ma consentono di spostare il focus e l’attenzione da quel dato che non "rappresenta" nulla (se non se stesso), all'uso che di quell’artefatto sintetico e delle macchine che lo producono ne facciamo noi umani.
Forse il mio ragionamento non sta in piedi, ma io sotto il profilo “protezione dei dati personali” vedo enormi e quasi insormontabili problemi in relazione ai data-set di addestramento (e a mio giudizio non sono problemi legati agli errori di output quanto meno in relazione al GDPR) e vedo problemi possibili ma a me (e temo anche al Garante) ignoti in relazione ai dati degli utenti/fruitori ed ai dati da questi immessi nel prompt.
Trovo invece un po’ folle pensare di attenzionare le risposte sbagliate, attribuendo a quei non-dati uno status di tutela che, a mio giudizio, allo stato dell’arte, non dovrebbero avere.
Ultima annotazione: l’uso di dati falsi, inesatti o le lesioni ad onore e reputazione legati all’uso di informazioni comunque ottenute da quegli artefatti sono tutte condotte adeguatamente presidiate dall’ordinamento. Assai più preoccupante e poco presidiata la folle corsa alle API ed all’utilizzo di quei sistemi per automatizzare processi diversi come search...vedremo.
CB
Il giorno lun 3 apr 2023 alle ore 07:19 Stefano Zacchiroli <zack@upsilon.cc> ha scritto:
Certo. Ma questo è l'altro aspetto: quello del trattamento dei dati in *input* a ChatGPT, che esiste ed è potenzialmente problematico dal punto di vista della privacy, a prescindere dalla veridicità delle risposte date.
La mia domanda era su quale sia l'impatto della falsità dell'*output* (che sollevavi come fattore a se stante nella mail precedente) sui profili giuridici di violazione della privacy.
Saluti
On April 2, 2023 11:22:03 PM GMT+02:00, Maurizio Borghi <maurizio.borghi@unito.it> wrote: >On Sun, 2 Apr 2023 at 20:19, Stefano Zacchiroli <zack@upsilon.cc> wrote: > >> >> Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è >> in effetti evidente a tutti. Ma, da non giurista, faccio veramente >> fatica a capire perché questo ponga problemi al Garante per la >> protezione dei dati personali. Se pubblico un sito web pieno di panzane >> su persone viventi, il Garante ha il potere di farmelo chiudere? Direi >> (sempre da non giurista), che al massimo rischio una querela per >> diffamazione > > >Se la produzione di quelle panzane richiede il trattamento dei dati di >milioni di ignari cittadini, allora sì, attrai le ire del Garante (oltre >che quelle dei destinatari delle tue panzane). > >> >> -- >_______________ >*Maurizio Borghi* >Università di Torino >https://www.dg.unito.it/persone/maurizio.borghi >Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/> > >My Webex room: https://unito.webex.com/meet/maurizio.borghi
-- Sent from my mobile phone. Please excuse my brevity and top-posting. _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
-- * * *Avv. Carlo Blengino* * * /Via Duchessa Jolanda n. 19,/ /10138 Torino (TO) - Italy/ /tel. +39 011 4474035/ Penalistiassociati.it
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Salve Carlo, ciò che non è legale per un essere umano, non deve esserlo nemmeno per un automatismo creato o amministrato da un essere umano. Pena la fine dello stato di diritto. Ma prima di provare a spiegare cosa non regge della tua analisi, vorrei porti una domanda: perché senti questa urgenza di difendere un software? Davvero, ti prego di rifletterci e rispondere perché sono sinceramente curioso sui tuoi moventi profondi. E' probabile che mi aiutino a comprendere i miei. On Mon, 3 Apr 2023 17:56:41 +0200 Carlo Blengino wrote:
I dati generati da ChatGPT ed in generale dalle attuali forme di AI Generativa, anche per immagini come Dall-e, anche quando apparentemente riferibili ad una persona fisica identificata o identificabile, *non dovrebbero mai esser considerati dati personali*, e ciò a prescindere dalla loro verità/falsità o dalla loro più o meno marcata aderenza alla realtà.
Sono dati sintetici che non rappresentano altro se non loro stessi.
Per efficienza, proviamo a partire da due semplici definizioni: - informazione: esperienza soggettiva di pensiero comunicabile - dato: rappresentazione (su un supporto trasferibile) interpretabile come informazione da una mente umana L'informazione esiste solo nelle nostre menti e non esce mai dai nostri crani, ma grazie al linguaggio abbiamo inventato un protocollo che ci permette di sincronizzare le nostre menti, ricreando nella mente del destinatario un informazione analoga (ma mai identica) a quella condivisa da un mittente. Il dato è una rappresentazione, ovvero (per semplificare) un insieme di simboli che imprimiamo o facciamo imprimere su un supporto trasferibile nello spazio o nel tempo, affinché siano interpretati come informazione da una o più altre menti umane, lontane nello spazio o nel tempo. Questa definizione, prettamente informatica, di "dato" coincide con la definizione che hai condiviso da un punto di vista giuridico:
Per comprendere l’affermazione, forse azzardata, è bene definire cosa è un dato per il diritto: il dato è *una rappresentazione di fatti, informazioni o concetti*. Il dato informatico è sin dalla Convenzione di Budapest del 2001 definito come una “presentazione di fatti, informazioni o concetti in forma suscettibile di essere utilizzata in un sistema computerizzato…”
Presentazione e rappresentazione sono produzioni umane. La forma suscettibile di essere utilizzata in un sistema computerizzato è ormai del tutto irrilevante: in qualsiasi forma un'informazione (fatti, informazioni o concetti) venga presentata, è possibile costruire un software in grado di utilizzarla. Omessa questa specificazione ormai irrilevante, le due definizioni coincidono.
Le creazioni di questi sistemi, da quel che ho capito, anche quando appaiono “dati” personali, rappresentano unicamente loro stessi, ovvero una sequenza di parole o numeri o di pixels, e null’altro.
L'output di un software è sempre un dato. Anche una sequenza casuale di simboli è un dato (peraltro estremamente prezioso, se realmente casuale). Non solo perché rappresenta sempre qualcosa di interpretabile, come minimo, come l'applicazione di un certo numero di trasformazioni ad un certo input. E' un dato perché è interpretabile dall'uomo secondo il significato che chi ha progettato, realizzato e documentato il software che lo ha prodotto, vuole che gli sia attribuito. Nel caso di ChatGPT, tale significato è letteralmente il significato che la tua mente vi attribuisce leggendolo. Quel software è stato realizzato da qualcuno con la precisa intenzione di far produrre un output che la tua mente interpreti come informazione. Dunque non solo la tua mente interpreta i dati di quell'output come informazione, ma chi ha realizzato e mantiene in esecuzione quel software è il mittente di quel messaggio, dell'informazione veicolata da quell'output. Questo rimane vero qualunque disclaimer Open AI possa mettere all'ingresso dell'applicazione. Quello che leggi è e rimane un dato prodotto per conto di qualcuno (Open AI, Microsoft etc...) affinché la tua mente lo riesca ad interpretare come informazione. Il fatto che nessuno, dentro Open AI, abbia materialmente espresso la sequenza di parole che leggi è irrilevante: hanno espresso il software che lo ha prodotto al loro posto e per loro volontà. Sono loro gli autori dell'output di GPT4. Se io scrivessi un software che, quando eseguito, produce in output una poesia come combinazione di una serie di versi che io ho scritto, tu non avresti problemi (credo) a riconoscere in me sia l'autore del software che l'autore dell'opera prodotta dal software stesso. E questo rimarrebbe vero se anche la sequenza prodotta non corrispondesse (magari a causa di un bug) a quella che io avevo in mente durante la scrittura del software. E se le sequenze possibili fossero N, tutte previste dal mio codice, non avresti comunque problema a riconoscere me sia come autore del software sia come autore delle opere da esso prodotte in output. Il software, di fatto, sarebbe una forma compressa di quelle N opere in output. Con ChatGPT è esattamente la stessa cosa. L'unica differenza è che nessuno si vuole assumere la responsabilità di quell'output perché chi l'ha programmato non si è preoccupato delle conseguenze e degli errori. Ora, appurato che l'output di ChatGPT è un dato (in quanto rappresentazione INTERPRETABILE come informazione) dobbiamo chiarire se possa essere un dato personale. In questo caso, come già chiarito da Benedetto Ponti, se il dato fa riferimento (ovvero può essere interpretato da una mente umana come facente riferimento) ad una persona fisica identifica o identificabile, allora è un dato personale. Che sia vero, falso o NULL (con un valore di verità ignoto al lettore) è irrilevante: quel dato produce nella mente di chi lo legge un'informazione riferita ad una persona. Tale persona, va protetta. Il fatto che ChatGPT non abbia intenzionalità è irrilevante: è uno strumento creato da persone con intenzioni precise, e attua costantemente tali intenzioni. Dunque, non dobbiamo proteggere le persone da ChatGPT, ma da chi lo ha creato e lo controlla. In un mondo in cui un software sufficientemente opaco può violare i diritti delle persone, chi li può produrre e controllare sarebbe sempre al di sopra della legge. Scaricare la responsabilità delle violazioni del diritto d'autore o del diritto alla protezione dei dati personali sugli utilizzatori del software è veramente ridicolo. Il loro contributo alla produzione dell'output è quasi irrilevante se confrontato con l'enorme lavoro di programmazione statistica e l'enorme quantità di dati e di energia utilizzati per la produzione del software e del suo output. Output che, non dimentichiamolo, riproduce token/lemmi/parole presenti nel proprio enorme "binario matriciale".
Trovo invece un po’ folle pensare di attenzionare le risposte sbagliate, attribuendo a quei non-dati uno status di tutela che, a mio giudizio, allo stato dell’arte, non dovrebbero avere.
No attenzione: gli output contenenti dati personali (veri o falsi che siano) sono solo uno dei problemi. C'è l'utilizzo di dati personali durante la programmazione statistica senza un esplicito permesso degli interessati nonché la pretesa impossibilità di esercitare il diritto ad eliminare quei dati dal modello (impossibilità che non esiste: basta rifare la programmazione statistica senza, per quanto costoso possa essere) o l'impossibilità di emendare dati errati. Un software che non possa strutturalmente rispettare i diritti umani semplicemente non va eseguito.
Ultima annotazione: l’uso di dati falsi, inesatti o le lesioni ad onore e reputazione legati all’uso di informazioni comunque ottenute da quegli artefatti sono tutte condotte adeguatamente presidiate dall’ordinamento. Assai più preoccupante e poco presidiata la folle corsa alle API ed all’utilizzo di quei sistemi per automatizzare processi diversi come search...vedremo.
Una volta che l'output è prodotto, l'uso che chi lo riceve ne fa è presidiato, siamo d'accordo. Mal presidiato, ma presidiato. Ma qui non stiamo parlando di questo: stiamo parlando di ciò che ChatGPT fa per conto di chi lo ha realizzato e lo amministra. ChatGPT (e GPT4) è un software che qualcuno esegue. Se bastasse introdurre un software per non rispondere di un reato, allora non dovremmo rispondere di qualsiasi violazione del diritto d'autore perché la rimozione delle ridicole restrizioni imposte dal DRM viene sempre fatto da un software. O ancora, la pubblicazione di dati personali sottratti ad un individuo su un sito web non dovrebbe costituire un reato perché il server web che li distribuisce è un software che li produce in output per mio conto esattamente come ChatGPT produce output le sue risposte per conto di Open AI. Per questo la tua argomentazione non regge Carlo. Ciò che non è legale per un essere umano, non deve esserlo nemmeno per un automatismo creato o amministrato da un essere umano. Pena la fine dello stato di diritto. Giacomo
Questo e altro sull'articolo di oggi di Walter Vannini apparso su:
https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna-i... <https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna-i...> Grazie per aver segnalato questo intervento di Walter Vannini, che dopo aver perorato la causa del Garante sembra suggerire che basterebbe un buon disclaimer per mettere a posto le cose, e ne fornisce un esempio: *chatGPT genera testo che, a livello sintattico, è inerente alla tua richiesta. Questo testo può essere o non essere, in modo del tutto casuale, corrispondente al senso che tu attribuisci alle parole che hai usato. Allo stesso modo, il testo prodotto da chatGPT può corrispondere o non corrispondere a fatti o eventi reali, pur essendo sempre grammaticalmente impeccabile e formulato in modo da sembrare autorevole. ChatGPT non possiede, per scelta dei suo sviluppatori, alcun concetto di “verità” o alcun modello di conoscenza ed è quindi strutturalmente incapace di distinguere il vero dal falso. Per questo motivo possiamo dire che chatGPT non mente, perché nel suo codice verità e falsità sono indistinguibili, ma si limita a dire stronzate, nella definizione del professor Frankfurt, cioè a fare affermazioni del tutto plausibili senza alcun vincolo di realtà.* Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo. Ma se è vero che basterebbe presentare sotto la giusta luce il comportamento del sistema, non sarà che la "stronzata" diventa allora il provvedimento del Garante? E' per il fatto che la società OpenAI è ambigua (e sì, forse anche "stronza") nel presentare ChatGPT come potenziale "oracolo" (mi riferisco in particolare al lancio di GPT-4) che oggi chi si trova in Italia anche di passaggio deve pagare una VPN per farsi generare uno snippet html o farsi dare una ricetta di cucina? Buona giornata e grazie a tutti per la discussione. Guido On Tue, 4 Apr 2023 at 00:53, Giacomo Tesio <giacomo@tesio.it> wrote:
Salve Carlo,
ciò che non è legale per un essere umano, non deve esserlo nemmeno per un automatismo creato o amministrato da un essere umano. Pena la fine dello stato di diritto.
Ma prima di provare a spiegare cosa non regge della tua analisi, vorrei porti una domanda: perché senti questa urgenza di difendere un software?
Davvero, ti prego di rifletterci e rispondere perché sono sinceramente curioso sui tuoi moventi profondi. E' probabile che mi aiutino a comprendere i miei.
On Mon, 3 Apr 2023 17:56:41 +0200 Carlo Blengino wrote:
I dati generati da ChatGPT ed in generale dalle attuali forme di AI Generativa, anche per immagini come Dall-e, anche quando apparentemente riferibili ad una persona fisica identificata o identificabile, *non dovrebbero mai esser considerati dati personali*, e ciò a prescindere dalla loro verità/falsità o dalla loro più o meno marcata aderenza alla realtà.
Sono dati sintetici che non rappresentano altro se non loro stessi.
Per efficienza, proviamo a partire da due semplici definizioni:
- informazione: esperienza soggettiva di pensiero comunicabile - dato: rappresentazione (su un supporto trasferibile) interpretabile come informazione da una mente umana
L'informazione esiste solo nelle nostre menti e non esce mai dai nostri crani, ma grazie al linguaggio abbiamo inventato un protocollo che ci permette di sincronizzare le nostre menti, ricreando nella mente del destinatario un informazione analoga (ma mai identica) a quella condivisa da un mittente.
Il dato è una rappresentazione, ovvero (per semplificare) un insieme di simboli che imprimiamo o facciamo imprimere su un supporto trasferibile nello spazio o nel tempo, affinché siano interpretati come informazione da una o più altre menti umane, lontane nello spazio o nel tempo.
Questa definizione, prettamente informatica, di "dato" coincide con la definizione che hai condiviso da un punto di vista giuridico:
Per comprendere l’affermazione, forse azzardata, è bene definire cosa è un dato per il diritto: il dato è *una rappresentazione di fatti, informazioni o concetti*. Il dato informatico è sin dalla Convenzione di Budapest del 2001 definito come una “presentazione di fatti, informazioni o concetti in forma suscettibile di essere utilizzata in un sistema computerizzato…”
Presentazione e rappresentazione sono produzioni umane.
La forma suscettibile di essere utilizzata in un sistema computerizzato è ormai del tutto irrilevante: in qualsiasi forma un'informazione (fatti, informazioni o concetti) venga presentata, è possibile costruire un software in grado di utilizzarla.
Omessa questa specificazione ormai irrilevante, le due definizioni coincidono.
Le creazioni di questi sistemi, da quel che ho capito, anche quando appaiono “dati” personali, rappresentano unicamente loro stessi, ovvero una sequenza di parole o numeri o di pixels, e null’altro.
L'output di un software è sempre un dato.
Anche una sequenza casuale di simboli è un dato (peraltro estremamente prezioso, se realmente casuale).
Non solo perché rappresenta sempre qualcosa di interpretabile, come minimo, come l'applicazione di un certo numero di trasformazioni ad un certo input.
E' un dato perché è interpretabile dall'uomo secondo il significato che chi ha progettato, realizzato e documentato il software che lo ha prodotto, vuole che gli sia attribuito.
Nel caso di ChatGPT, tale significato è letteralmente il significato che la tua mente vi attribuisce leggendolo.
Quel software è stato realizzato da qualcuno con la precisa intenzione di far produrre un output che la tua mente interpreti come informazione.
Dunque non solo la tua mente interpreta i dati di quell'output come informazione, ma chi ha realizzato e mantiene in esecuzione quel software è il mittente di quel messaggio, dell'informazione veicolata da quell'output.
Questo rimane vero qualunque disclaimer Open AI possa mettere all'ingresso dell'applicazione.
Quello che leggi è e rimane un dato prodotto per conto di qualcuno (Open AI, Microsoft etc...) affinché la tua mente lo riesca ad interpretare come informazione.
Il fatto che nessuno, dentro Open AI, abbia materialmente espresso la sequenza di parole che leggi è irrilevante: hanno espresso il software che lo ha prodotto al loro posto e per loro volontà.
Sono loro gli autori dell'output di GPT4.
Se io scrivessi un software che, quando eseguito, produce in output una poesia come combinazione di una serie di versi che io ho scritto, tu non avresti problemi (credo) a riconoscere in me sia l'autore del software che l'autore dell'opera prodotta dal software stesso.
E questo rimarrebbe vero se anche la sequenza prodotta non corrispondesse (magari a causa di un bug) a quella che io avevo in mente durante la scrittura del software.
E se le sequenze possibili fossero N, tutte previste dal mio codice, non avresti comunque problema a riconoscere me sia come autore del software sia come autore delle opere da esso prodotte in output.
Il software, di fatto, sarebbe una forma compressa di quelle N opere in output.
Con ChatGPT è esattamente la stessa cosa. L'unica differenza è che nessuno si vuole assumere la responsabilità di quell'output perché chi l'ha programmato non si è preoccupato delle conseguenze e degli errori.
Ora, appurato che l'output di ChatGPT è un dato (in quanto rappresentazione INTERPRETABILE come informazione) dobbiamo chiarire se possa essere un dato personale.
In questo caso, come già chiarito da Benedetto Ponti, se il dato fa riferimento (ovvero può essere interpretato da una mente umana come facente riferimento) ad una persona fisica identifica o identificabile, allora è un dato personale.
Che sia vero, falso o NULL (con un valore di verità ignoto al lettore) è irrilevante: quel dato produce nella mente di chi lo legge un'informazione riferita ad una persona.
Tale persona, va protetta.
Il fatto che ChatGPT non abbia intenzionalità è irrilevante: è uno strumento creato da persone con intenzioni precise, e attua costantemente tali intenzioni.
Dunque, non dobbiamo proteggere le persone da ChatGPT, ma da chi lo ha creato e lo controlla.
In un mondo in cui un software sufficientemente opaco può violare i diritti delle persone, chi li può produrre e controllare sarebbe sempre al di sopra della legge.
Scaricare la responsabilità delle violazioni del diritto d'autore o del diritto alla protezione dei dati personali sugli utilizzatori del software è veramente ridicolo.
Il loro contributo alla produzione dell'output è quasi irrilevante se confrontato con l'enorme lavoro di programmazione statistica e l'enorme quantità di dati e di energia utilizzati per la produzione del software e del suo output. Output che, non dimentichiamolo, riproduce token/lemmi/parole presenti nel proprio enorme "binario matriciale".
Trovo invece un po’ folle pensare di attenzionare le risposte sbagliate, attribuendo a quei non-dati uno status di tutela che, a mio giudizio, allo stato dell’arte, non dovrebbero avere.
No attenzione: gli output contenenti dati personali (veri o falsi che siano) sono solo uno dei problemi.
C'è l'utilizzo di dati personali durante la programmazione statistica senza un esplicito permesso degli interessati nonché la pretesa impossibilità di esercitare il diritto ad eliminare quei dati dal modello (impossibilità che non esiste: basta rifare la programmazione statistica senza, per quanto costoso possa essere) o l'impossibilità di emendare dati errati.
Un software che non possa strutturalmente rispettare i diritti umani semplicemente non va eseguito.
Ultima annotazione: l’uso di dati falsi, inesatti o le lesioni ad onore e reputazione legati all’uso di informazioni comunque ottenute da quegli artefatti sono tutte condotte adeguatamente presidiate dall’ordinamento. Assai più preoccupante e poco presidiata la folle corsa alle API ed all’utilizzo di quei sistemi per automatizzare processi diversi come search...vedremo.
Una volta che l'output è prodotto, l'uso che chi lo riceve ne fa è presidiato, siamo d'accordo. Mal presidiato, ma presidiato.
Ma qui non stiamo parlando di questo: stiamo parlando di ciò che ChatGPT fa per conto di chi lo ha realizzato e lo amministra.
ChatGPT (e GPT4) è un software che qualcuno esegue.
Se bastasse introdurre un software per non rispondere di un reato, allora non dovremmo rispondere di qualsiasi violazione del diritto d'autore perché la rimozione delle ridicole restrizioni imposte dal DRM viene sempre fatto da un software.
O ancora, la pubblicazione di dati personali sottratti ad un individuo su un sito web non dovrebbe costituire un reato perché il server web che li distribuisce è un software che li produce in output per mio conto esattamente come ChatGPT produce output le sue risposte per conto di Open AI.
Per questo la tua argomentazione non regge Carlo.
Ciò che non è legale per un essere umano, non deve esserlo nemmeno per un automatismo creato o amministrato da un essere umano.
Pena la fine dello stato di diritto.
Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

On Tue, Apr 04, 2023 06:52:24 AM +0200, Guido Vetere wrote:
Tutto questo è corretto, tranne il riferimento alle "stronzate" (bullshit) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo.
embeh? Mi scuso se ho perso qualcosa nella discussione, e' probabilissimo che qualcuno piu' preparato abbia gia' detto la stessa cosa meglio di me ma.. che importanza ha quel che "dichiara" ChatGPT? Dietro a una str***ta come ChatGPT, ci sono soggetti dotati di intenzionalita' eccome, ed e' solo di quelli che dovremmo parlare, o no? Altrimenti abbiamo gia' perso, accettando l'idea che ChatGPT e simili siano davvero "soggetti". Cioe' "esseri" distinti, con LORO agency, diritti, giustificazioni, volonta', eccetera... Un martello e' un oggetto, mica un soggetto. Idem per chatGPT e compagnia. Se quelli sono soggetti, non siamo umani noi. Marco -- Vi aspetto nella mia nuova newsletter: https://mfioretti.substack.com
trova in Italia anche di passaggio deve pagare una VPN per farsi generare uno snippet html o farsi dare una ricetta di cucina?
attento alle intossicazioni alimentari... ;-)
sono sopravvisuto a quelle che generava IBM Watson :-))) Il Mar 4 Apr 2023, 07:33 Stefano Quintarelli <stefano@quintarelli.it> ha scritto:
trova in Italia anche di passaggio deve pagare una VPN per farsi generare uno snippet html o farsi dare una ricetta di cucina?
attento alle intossicazioni alimentari... ;-)
On mar, 2023-04-04 at 06:52 +0200, Guido Vetere wrote:
Questo e altro sull'articolo di oggi di Walter Vannini apparso su: https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna- il-garante-e-vivo-e-lotta-insieme-a-noi/
Grazie per aver segnalato questo intervento di Walter Vannini, che dopo aver perorato la causa del Garante sembra suggerire che basterebbe un buon disclaimer per mettere a posto le cose, e ne fornisce un esempio: chatGPT genera testo che, a livello sintattico, è inerente alla tua richiesta. Questo testo può essere o non essere, in modo del tutto casuale, corrispondente al senso che tu attribuisci alle parole che hai usato. Allo stesso modo, il testo prodotto da chatGPT può corrispondere o non corrispondere a fatti o eventi reali, pur essendo sempre grammaticalmente impeccabile e formulato in modo da sembrare autorevole. ChatGPT non possiede, per scelta dei suo sviluppatori, alcun concetto di “verità” o alcun modello di conoscenza ed è quindi strutturalmente incapace di distinguere il vero dal falso. Per questo motivo possiamo dire che chatGPT non mente, perché nel suo codice verità e falsità sono indistinguibili, ma si limita a dire stronzate, nella definizione del professor Frankfurt, cioè a fare affermazioni del tutto plausibili senza alcun vincolo di realtà.
Tutto questo è corretto, tranne il riferimento alle "stronzate" (bullshit) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo.
Salve a tutti, se è gradito (e ne sono lieto) citare qui DataKnightmare, allora, per chi fosse interessato, anche Cassandra avrebbe da dire la sua ... https://medium.com/@calamarim/cassandra-crossing-ia-fabbriche-di-informazion...
Ma se è vero che basterebbe presentare sotto la giusta luce il comportamento del sistema, non sarà che la "stronzata" diventa allora il provvedimento del Garante? E' per il fatto che la società OpenAI è ambigua (e sì, forse anche "stronza") nel presentare ChatGPT come potenziale "oracolo" (mi riferisco in particolare al lancio di GPT-4) che oggi chi si trova in Italia anche di passaggio deve pagare una VPN per farsi generare uno snippet html o farsi dare una ricetta di cucina?
Buona giornata e grazie a tutti per la discussione.
Guido
On Tue, 4 Apr 2023 at 00:53, Giacomo Tesio <giacomo@tesio.it> wrote:
Salve Carlo,
ciò che non è legale per un essere umano, non deve esserlo nemmeno per un automatismo creato o amministrato da un essere umano. Pena la fine dello stato di diritto.
Ma prima di provare a spiegare cosa non regge della tua analisi, vorrei porti una domanda: perché senti questa urgenza di difendere un software?
Davvero, ti prego di rifletterci e rispondere perché sono sinceramente curioso sui tuoi moventi profondi. E' probabile che mi aiutino a comprendere i miei.
On Mon, 3 Apr 2023 17:56:41 +0200 Carlo Blengino wrote:
I dati generati da ChatGPT ed in generale dalle attuali forme di AI Generativa, anche per immagini come Dall-e, anche quando apparentemente riferibili ad una persona fisica identificata o identificabile, *non dovrebbero mai esser considerati dati personali*, e ciò a prescindere dalla loro verità/falsità o dalla loro più o meno marcata aderenza alla realtà.
Sono dati sintetici che non rappresentano altro se non loro stessi.
Per efficienza, proviamo a partire da due semplici definizioni:
- informazione: esperienza soggettiva di pensiero comunicabile - dato: rappresentazione (su un supporto trasferibile) interpretabile come informazione da una mente umana
L'informazione esiste solo nelle nostre menti e non esce mai dai nostri crani, ma grazie al linguaggio abbiamo inventato un protocollo che ci permette di sincronizzare le nostre menti, ricreando nella mente del destinatario un informazione analoga (ma mai identica) a quella condivisa da un mittente.
Il dato è una rappresentazione, ovvero (per semplificare) un insieme di simboli che imprimiamo o facciamo imprimere su un supporto trasferibile nello spazio o nel tempo, affinché siano interpretati come informazione da una o più altre menti umane, lontane nello spazio o nel tempo.
Questa definizione, prettamente informatica, di "dato" coincide con la definizione che hai condiviso da un punto di vista giuridico:
Per comprendere l’affermazione, forse azzardata, è bene definire cosa è un dato per il diritto: il dato è *una rappresentazione di fatti, informazioni o concetti*. Il dato informatico è sin dalla Convenzione di Budapest del 2001 definito come una “presentazione di fatti, informazioni o concetti in forma suscettibile di essere utilizzata in un sistema computerizzato…”
Presentazione e rappresentazione sono produzioni umane.
La forma suscettibile di essere utilizzata in un sistema computerizzato è ormai del tutto irrilevante: in qualsiasi forma un'informazione (fatti, informazioni o concetti) venga presentata, è possibile costruire un software in grado di utilizzarla.
Omessa questa specificazione ormai irrilevante, le due definizioni coincidono.
Le creazioni di questi sistemi, da quel che ho capito, anche quando appaiono “dati” personali, rappresentano unicamente loro stessi, ovvero una sequenza di parole o numeri o di pixels, e null’altro.
L'output di un software è sempre un dato.
Anche una sequenza casuale di simboli è un dato (peraltro estremamente prezioso, se realmente casuale).
Non solo perché rappresenta sempre qualcosa di interpretabile, come minimo, come l'applicazione di un certo numero di trasformazioni ad un certo input.
E' un dato perché è interpretabile dall'uomo secondo il significato che chi ha progettato, realizzato e documentato il software che lo ha prodotto, vuole che gli sia attribuito.
Nel caso di ChatGPT, tale significato è letteralmente il significato che la tua mente vi attribuisce leggendolo.
Quel software è stato realizzato da qualcuno con la precisa intenzione di far produrre un output che la tua mente interpreti come informazione.
Dunque non solo la tua mente interpreta i dati di quell'output come informazione, ma chi ha realizzato e mantiene in esecuzione quel software è il mittente di quel messaggio, dell'informazione veicolata da quell'output.
Questo rimane vero qualunque disclaimer Open AI possa mettere all'ingresso dell'applicazione.
Quello che leggi è e rimane un dato prodotto per conto di qualcuno (Open AI, Microsoft etc...) affinché la tua mente lo riesca ad interpretare come informazione.
Il fatto che nessuno, dentro Open AI, abbia materialmente espresso la sequenza di parole che leggi è irrilevante: hanno espresso il software che lo ha prodotto al loro posto e per loro volontà.
Sono loro gli autori dell'output di GPT4.
Se io scrivessi un software che, quando eseguito, produce in output una poesia come combinazione di una serie di versi che io ho scritto, tu non avresti problemi (credo) a riconoscere in me sia l'autore del software che l'autore dell'opera prodotta dal software stesso.
E questo rimarrebbe vero se anche la sequenza prodotta non corrispondesse (magari a causa di un bug) a quella che io avevo in mente durante la scrittura del software.
E se le sequenze possibili fossero N, tutte previste dal mio codice, non avresti comunque problema a riconoscere me sia come autore del software sia come autore delle opere da esso prodotte in output.
Il software, di fatto, sarebbe una forma compressa di quelle N opere in output.
Con ChatGPT è esattamente la stessa cosa. L'unica differenza è che nessuno si vuole assumere la responsabilità di quell'output perché chi l'ha programmato non si è preoccupato delle conseguenze e degli errori.
Ora, appurato che l'output di ChatGPT è un dato (in quanto rappresentazione INTERPRETABILE come informazione) dobbiamo chiarire se possa essere un dato personale.
In questo caso, come già chiarito da Benedetto Ponti, se il dato fa riferimento (ovvero può essere interpretato da una mente umana come facente riferimento) ad una persona fisica identifica o identificabile, allora è un dato personale.
Che sia vero, falso o NULL (con un valore di verità ignoto al lettore) è irrilevante: quel dato produce nella mente di chi lo legge un'informazione riferita ad una persona.
Tale persona, va protetta.
Il fatto che ChatGPT non abbia intenzionalità è irrilevante: è uno strumento creato da persone con intenzioni precise, e attua costantemente tali intenzioni.
Dunque, non dobbiamo proteggere le persone da ChatGPT, ma da chi lo ha creato e lo controlla.
In un mondo in cui un software sufficientemente opaco può violare i diritti delle persone, chi li può produrre e controllare sarebbe sempre al di sopra della legge.
Scaricare la responsabilità delle violazioni del diritto d'autore o del diritto alla protezione dei dati personali sugli utilizzatori del software è veramente ridicolo.
Il loro contributo alla produzione dell'output è quasi irrilevante se confrontato con l'enorme lavoro di programmazione statistica e l'enorme quantità di dati e di energia utilizzati per la produzione del software e del suo output. Output che, non dimentichiamolo, riproduce token/lemmi/parole presenti nel proprio enorme "binario matriciale".
Trovo invece un po’ folle pensare di attenzionare le risposte sbagliate, attribuendo a quei non-dati uno status di tutela che, a mio giudizio, allo stato dell’arte, non dovrebbero avere.
No attenzione: gli output contenenti dati personali (veri o falsi che siano) sono solo uno dei problemi.
C'è l'utilizzo di dati personali durante la programmazione statistica senza un esplicito permesso degli interessati nonché la pretesa impossibilità di esercitare il diritto ad eliminare quei dati dal modello (impossibilità che non esiste: basta rifare la programmazione statistica senza, per quanto costoso possa essere) o l'impossibilità di emendare dati errati.
Un software che non possa strutturalmente rispettare i diritti umani semplicemente non va eseguito.
Ultima annotazione: l’uso di dati falsi, inesatti o le lesioni ad onore e reputazione legati all’uso di informazioni comunque ottenute da quegli artefatti sono tutte condotte adeguatamente presidiate dall’ordinamento. Assai più preoccupante e poco presidiata la folle corsa alle API ed all’utilizzo di quei sistemi per automatizzare processi diversi come search...vedremo.
Una volta che l'output è prodotto, l'uso che chi lo riceve ne fa è presidiato, siamo d'accordo. Mal presidiato, ma presidiato.
Ma qui non stiamo parlando di questo: stiamo parlando di ciò che ChatGPT fa per conto di chi lo ha realizzato e lo amministra.
ChatGPT (e GPT4) è un software che qualcuno esegue.
Se bastasse introdurre un software per non rispondere di un reato, allora non dovremmo rispondere di qualsiasi violazione del diritto d'autore perché la rimozione delle ridicole restrizioni imposte dal DRM viene sempre fatto da un software.
O ancora, la pubblicazione di dati personali sottratti ad un individuo su un sito web non dovrebbe costituire un reato perché il server web che li distribuisce è un software che li produce in output per mio conto esattamente come ChatGPT produce output le sue risposte per conto di Open AI.
Per questo la tua argomentazione non regge Carlo.
Ciò che non è legale per un essere umano, non deve esserlo nemmeno per un automatismo creato o amministrato da un essere umano.
Pena la fine dello stato di diritto.
Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Buongiorno Marco, "Marco A. Calamari" <marcoc_maillist@marcoc.it> writes: [...]
Salve a tutti,
se è gradito (e ne sono lieto) citare qui DataKnightmare, allora, per chi fosse interessato, anche Cassandra avrebbe da dire la sua ...
https://medium.com/@calamarim/cassandra-crossing-ia-fabbriche-di-informazion...
mi permetto di riportare quello che ritengo il nocciolo del contributo e fare alcuni commenti: --8<---------------cut here---------------start------------->8--- ChatGPT e tutti i suoi successori dello stesso tipo non conoscono, non conoscono per niente, non conoscono assolutamente, non conoscono neanche lontanamente, non conoscono per niente la risposta a qualsiasi domanda; non conoscono assolutamente nulla. La conoscenza con cui vengono “nutriti” viene “digerita” e svanisce, lasciando solo un credibile “Mentecatto Artificiale” privo di qualsiasi Intelligenza o Cultura. --8<---------------cut here---------------end--------------->8--- Come rilevi qualche paragrafo più avanti, il concetto di menzogna implica necessariamente l'ammissione del concetto di verità ma sistemi come questi non contemplano nulla che assomigli a verità, esiste solo /credibilità/ dell'output; per questo credo che sia più adeguato usare il paragone di "bulshitter" alla Frankfurt. --8<---------------cut here---------------start------------->8--- [...] Risposte credibili, non risposte vere. Questo concetto deve essere recitato come un mantra, ripetuto fino allo sfinimento, pubblicizzato in ogni occasione. --8<---------------cut here---------------end--------------->8--- Il /disclaimer/ che assolutamente adesso manca. --8<---------------cut here---------------start------------->8--- ChatGPT e tutti i suoi successori non hanno nessuna conoscenza sulla verità o falsità di una domanda, non hanno nessuna cultura, pur avendone digerito quantità enormi. Sono un vicolo cieco, utilizzabile solo come arma di propaganda di massa. E lo stanno facendo! Sono solo in grado di darvi risposte credibili, in cui voi individuerete il significato che volete o potete dargli. E qui sta il pericolo, questi oggetti vengono propagandati come risponditori di domande, non come affabulatori o generatori di prosa fantasiosa. --8<---------------cut here---------------end--------------->8--- Diventa arma di propaganda nel momento in cui quel /disclaimer/ viene omesso: deve essere trattata alla stessa stregua della pubblicità ingannevole [1] --8<---------------cut here---------------start------------->8--- E la loro attuale linea di sviluppo non è quella di renderli capaci di risposte esatte, cosa che non sarà mai possibile, ma solo incapaci di dare risposte così errate da essere evidenti o ridicole, risposte che siano espresse in termini razzisti, sessisti, in violazione di qualsiasi possibile concetto ”politically correct”. --8<---------------cut here---------------end--------------->8--- quindi sempre più ingannevoli? [...] --8<---------------cut here---------------start------------->8--- Speriamo che questa eqnnesima ripetizione, spero ben argomentata ripetizione, serva a qualcosa. Se vi affidate a ChatGPT, non tornerete mai dalla guerra. --8<---------------cut here---------------end--------------->8--- Sì ma allora come la mettiamo con i dati personali che trattano i sistemi come ChatGPT, sia quelli usati per il training che quelli sparati stocasticamente come output? [...] Grazie, 380° [1] https://it.wikipedia.org/wiki/Pubblicit%C3%A0_ingannevole -- 380° (Giovanni Biscuolo public alter ego) «Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché» Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>.
Ciao Guido, trovo veramente affascinante (quanto inquietante) questo passaggio della tua email: On Tue, 4 Apr 2023 06:52:24 +0200 Guido Vetere wrote:
Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo.
Come diversi informatici in lista ti possono confermare, lo "stronzo" dietro un software è sempre chi lo programma e ne controlla l'esecuzione. Un software infatti applica all'ambiente SEMPRE e ANZITUTTO la volontà di chi l'ha programmato (e nel caso di un SaaS, eseguito), riproducendola ed imponendola a tutti coloro che sono parte, volenti o nolenti, della organizzazione cibernetica in cui tale software opera. Nel caso di ChatGPT, lo "stronzo" (nel senso di Frankfurt) è Open AI. Nel caso di GitHub Copilot, lo "stronzo" è GitHub. Entrambi si leggono "Microsoft". Nel caso di Google Assistant, lo "stronzo" è Google/Alphabet. Nel caso dei risultati di ricerca o delle news "personalizzate" fornite dai servizi di Google, lo "stronzo" è Google/Alphabet. Nel caso della timeline Instagram o Facebook, lo "stronzo" è Facebook. Nel caso della timeline TikTok, lo "stronzo" è TikTok. Nel caso dell'amica virtuale "Replika", lo "stronzo" è Luka, Inc. Nel caso dell'osservatorio di Monitora PA, lo "stronzo" sono io. (e con me i molti che contribuiscono al suo sviluppo...) Il punto è: che si tratti di bug (come può essere un falso positivo prodotto dall'osservatorio di Monitora PA) o di scelte progettuali c'è sempre almeno un essere umano di cui il software riproduce pedissequamente la volontà. Questa volontà può essere impressa nel software in modo relativamente trasparente tramite la programmazione linguistica (ad esempio in Python o in C) oppure essere impressa nel software in modo opaco, attraverso la selezione dei dati da utilizzare per la programmazione statistica e la progettazione della topologia della vector reducing machine che verrà programmata statisticamente. Ora, tutti gli "stronzi" qui presenti che abbiano mai realizzato un software in prima persona, potranno confermarti di esistere. Alcuni saranno ben lieti di non dover rispondere delle proprie creazioni, mentre altri si sentiranno oltraggiati dall'idea che qualcuno possa ignorare la propria esistenza come autori di quelle creazioni. Ma tutti saranno consapevoli di aver LAVORATO per realizzare la sequenza di bit che le macchine elaborano automaticamente per produrre gli effetti che loro desiderano. Il contributo dell'utente alla produzione dell'output di un software è completamente determinato dal programmatore e può variare moltissimo a seconda del software. Nel caso di ChatGPT, è oggettivamente trascurabile. Per questa ragione, la responsabilità dell'output NON PUO' essere scaricata sull'utente con un banale disclaimer! Quando leggo che "ChatGPT dichiara ONESTAMENTE di essere privo" di intenzionalità mi chiedo sinceramente se ci sia una qualche forza all'opera dietro questa allucinazione collettiva, dietro questa cancellazione delle persone che realizzano la macchina dalla tua coscienza, a cui gli sviluppatori siano talmente immuni da non percepirla. No: chi ha scritto quel disclaimer NON è onesto. E non è stato Chat GPT a scrivere quel disclaimer. Noti come Open AI sta manipolando la tua percezione della realtà? Forse il semplice fatto di essere capaci a programmare statisticamente un software (e magari averlo programmato), rende naturalmente immuni a questa allucinazione. Eppure si deve trattare di un'allucinazione molto forte se, come osservo qui, persone intelligenti ed in buona fede continuano a sostenerla NONOSTANTE altre persone, autorevoli, intelligenti ed altrettanto in buona fede, ma con una maggiore consapevolezza tecnica della questione, continuano a ripetere che il software è sempre realizzato da esseri umani e ne riproduce valori e interessi. Ti prego di riflettere sulla questione: io esisto, Open AI esiste, Microsoft esiste, Google esiste etc... cosa ti costringe a cancellare la nostra esistenza dalla tua coscienza quando guardi un artefatto che realizza pedissequamente la nostra volontà? Certo, una volta realizzato, un software diventa un agente cibernetico automatico, che "si muove da sé". Ma non è mai autonomo. Anche quando varia il proprio stato interno in funzione dell'input, tale variazione è sempre meccanicamente determinata dalla sua programmazione (per quanto complessa e opaca sia essa sia). Anche quando tale stato interno viene utilizzato insieme ad ogni nuovo input per calcolare nuovi output e nuove variazioni dello stato interno, ogni output e ogni variazione dello stato interno è meccanicamente determinato da chi ha programmato il software. Dunque l'agente cibernetico automatico non è MAI autonomo. On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro.
In assenza di tale autonomia, l'assenza di intenzionalità è irrilevante: il software riproduce le intenzioni di chi l'ha realizzato e ha deciso come deve essere usato. On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla.
Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza. In tal modo, l'intenzionalità (e la responsabilità legale) è tutta perfettamente determinata. Giacomo
Intervengo a conferma di quanto dice Giacomo sulla /presunzione di neutralità/ degli artefatti tecnologici. Ho chiesto a phind.com cosa è successo in piazza Tien An Men. Mi ha risposto citando i massacri e esponendo i diversi punti di vista, incluso quello del governo cinese. Allora ho chiesto: Is this the same answer you give to users in China? Answer: As an AI language model, I do not have the ability to determine the location of the user or the restrictions on information in their country. However, my answer is based on factual information and sources that are publicly available. The information I provided is objective and does not contain any political bias. Con buona pace di decenni di dibattiti sulla politicità (intrinseca o meno) degli artefatti tecnologici, sulla loro agency, sulla normatività del codice... La pretesa di neutralità è ingannevole: ogni artefatto, specie questi così complessi, incorporano normatività. I tecnologi che continuano a credere di costruire artefatti neutri e consegnarli nelle mani di persone che ne saranno responsabili negano (forse in primo luogo a se stessi) l'evidenza che gli artefatti incorporano l'intenzionalità e la normatività di chi li inventa e di chi paga chi li inventa. Alberto On 04/04/23 10:56, Giacomo Tesio wrote:
Ciao Guido,
trovo veramente affascinante (quanto inquietante) questo passaggio della tua email:
On Tue, 4 Apr 2023 06:52:24 +0200 Guido Vetere wrote:
Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo. Come diversi informatici in lista ti possono confermare, lo "stronzo" dietro un software è sempre chi lo programma e ne controlla l'esecuzione.
Un software infatti applica all'ambiente SEMPRE e ANZITUTTO la volontà di chi l'ha programmato (e nel caso di un SaaS, eseguito), riproducendola ed imponendola a tutti coloro che sono parte, volenti o nolenti, della organizzazione cibernetica in cui tale software opera.
Nel caso di ChatGPT, lo "stronzo" (nel senso di Frankfurt) è Open AI. Nel caso di GitHub Copilot, lo "stronzo" è GitHub. Entrambi si leggono "Microsoft".
Nel caso di Google Assistant, lo "stronzo" è Google/Alphabet. Nel caso dei risultati di ricerca o delle news "personalizzate" fornite dai servizi di Google, lo "stronzo" è Google/Alphabet.
Nel caso della timeline Instagram o Facebook, lo "stronzo" è Facebook.
Nel caso della timeline TikTok, lo "stronzo" è TikTok.
Nel caso dell'amica virtuale "Replika", lo "stronzo" è Luka, Inc.
Nel caso dell'osservatorio di Monitora PA, lo "stronzo" sono io. (e con me i molti che contribuiscono al suo sviluppo...)
Il punto è: che si tratti di bug (come può essere un falso positivo prodotto dall'osservatorio di Monitora PA) o di scelte progettuali c'è sempre almeno un essere umano di cui il software riproduce pedissequamente la volontà.
Questa volontà può essere impressa nel software in modo relativamente trasparente tramite la programmazione linguistica (ad esempio in Python o in C) oppure essere impressa nel software in modo opaco, attraverso la selezione dei dati da utilizzare per la programmazione statistica e la progettazione della topologia della vector reducing machine che verrà programmata statisticamente.
Ora, tutti gli "stronzi" qui presenti che abbiano mai realizzato un software in prima persona, potranno confermarti di esistere.
Alcuni saranno ben lieti di non dover rispondere delle proprie creazioni, mentre altri si sentiranno oltraggiati dall'idea che qualcuno possa ignorare la propria esistenza come autori di quelle creazioni.
Ma tutti saranno consapevoli di aver LAVORATO per realizzare la sequenza di bit che le macchine elaborano automaticamente per produrre gli effetti che loro desiderano.
Il contributo dell'utente alla produzione dell'output di un software è completamente determinato dal programmatore e può variare moltissimo a seconda del software. Nel caso di ChatGPT, è oggettivamente trascurabile.
Per questa ragione, la responsabilità dell'output NON PUO' essere scaricata sull'utente con un banale disclaimer!
Quando leggo che "ChatGPT dichiara ONESTAMENTE di essere privo" di intenzionalità mi chiedo sinceramente se ci sia una qualche forza all'opera dietro questa allucinazione collettiva, dietro questa cancellazione delle persone che realizzano la macchina dalla tua coscienza, a cui gli sviluppatori siano talmente immuni da non percepirla.
No: chi ha scritto quel disclaimer NON è onesto. E non è stato Chat GPT a scrivere quel disclaimer.
Noti come Open AI sta manipolando la tua percezione della realtà?
Forse il semplice fatto di essere capaci a programmare statisticamente un software (e magari averlo programmato), rende naturalmente immuni a questa allucinazione.
Eppure si deve trattare di un'allucinazione molto forte se, come osservo qui, persone intelligenti ed in buona fede continuano a sostenerla NONOSTANTE altre persone, autorevoli, intelligenti ed altrettanto in buona fede, ma con una maggiore consapevolezza tecnica della questione, continuano a ripetere che il software è sempre realizzato da esseri umani e ne riproduce valori e interessi.
Ti prego di riflettere sulla questione: io esisto, Open AI esiste, Microsoft esiste, Google esiste etc... cosa ti costringe a cancellare la nostra esistenza dalla tua coscienza quando guardi un artefatto che realizza pedissequamente la nostra volontà?
Certo, una volta realizzato, un software diventa un agente cibernetico automatico, che "si muove da sé". Ma non è mai autonomo.
Anche quando varia il proprio stato interno in funzione dell'input, tale variazione è sempre meccanicamente determinata dalla sua programmazione (per quanto complessa e opaca sia essa sia).
Anche quando tale stato interno viene utilizzato insieme ad ogni nuovo input per calcolare nuovi output e nuove variazioni dello stato interno, ogni output e ogni variazione dello stato interno è meccanicamente determinato da chi ha programmato il software.
Dunque l'agente cibernetico automatico non è MAI autonomo.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro. In assenza di tale autonomia, l'assenza di intenzionalità è irrilevante: il software riproduce le intenzioni di chi l'ha realizzato e ha deciso come deve essere usato.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla. Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza.
In tal modo, l'intenzionalità (e la responsabilità legale) è tutta perfettamente determinata.
Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Cari Giacomo e Alberto, il vostro punto di vista è molto interessante e vi ringrazio per averlo esposto con tanta coraggiosa assertività. Lo condivido senz'altro per tutto ciò che riguarda la programmazione imperativa e quella basata sulla rappresentazione della conoscenza e il ragionamento automatico. Se però consideriamo gli sviluppi dell'IA degli ultimi anni, e in particolare i LLM, le cose sono a mio avviso più complesse. Non mi inoltro in argomentazioni metafisiche per non tediare chi legge e perché non ho molto tempo. Propongo invece un piccolo sketch, forse ingenuo, che però può far riflettere. Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce. Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà? Secondo me no, ma se ne può parlare. Buona giornata. G. On Tue, 4 Apr 2023 at 11:46, Alberto Cammozzo via nexa < nexa@server-nexa.polito.it> wrote:
Intervengo a conferma di quanto dice Giacomo sulla *presunzione di neutralità* degli artefatti tecnologici.
Ho chiesto a phind.com cosa è successo in piazza Tien An Men.
Mi ha risposto citando i massacri e esponendo i diversi punti di vista, incluso quello del governo cinese.
Allora ho chiesto:
Is this the same answer you give to users in China? Answer:
As an AI language model, I do not have the ability to determine the location of the user or the restrictions on information in their country. However, my answer is based on factual information and sources that are publicly available. The information I provided is objective and does not contain any political bias.
Con buona pace di decenni di dibattiti sulla politicità (intrinseca o meno) degli artefatti tecnologici, sulla loro agency, sulla normatività del codice...
La pretesa di neutralità è ingannevole: ogni artefatto, specie questi così complessi, incorporano normatività.
I tecnologi che continuano a credere di costruire artefatti neutri e consegnarli nelle mani di persone che ne saranno responsabili negano (forse in primo luogo a se stessi) l'evidenza che gli artefatti incorporano l'intenzionalità e la normatività di chi li inventa e di chi paga chi li inventa.
Alberto
On 04/04/23 10:56, Giacomo Tesio wrote:
Ciao Guido,
trovo veramente affascinante (quanto inquietante) questo passaggio della tua email:
On Tue, 4 Apr 2023 06:52:24 +0200 Guido Vetere wrote:
Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo.
Come diversi informatici in lista ti possono confermare, lo "stronzo" dietro un software è sempre chi lo programma e ne controlla l'esecuzione.
Un software infatti applica all'ambiente SEMPRE e ANZITUTTO la volontà di chi l'ha programmato (e nel caso di un SaaS, eseguito), riproducendola ed imponendola a tutti coloro che sono parte, volenti o nolenti, della organizzazione cibernetica in cui tale software opera.
Nel caso di ChatGPT, lo "stronzo" (nel senso di Frankfurt) è Open AI. Nel caso di GitHub Copilot, lo "stronzo" è GitHub. Entrambi si leggono "Microsoft".
Nel caso di Google Assistant, lo "stronzo" è Google/Alphabet. Nel caso dei risultati di ricerca o delle news "personalizzate" fornite dai servizi di Google, lo "stronzo" è Google/Alphabet.
Nel caso della timeline Instagram o Facebook, lo "stronzo" è Facebook.
Nel caso della timeline TikTok, lo "stronzo" è TikTok.
Nel caso dell'amica virtuale "Replika", lo "stronzo" è Luka, Inc.
Nel caso dell'osservatorio di Monitora PA, lo "stronzo" sono io. (e con me i molti che contribuiscono al suo sviluppo...)
Il punto è: che si tratti di bug (come può essere un falso positivo prodotto dall'osservatorio di Monitora PA) o di scelte progettuali c'è sempre almeno un essere umano di cui il software riproduce pedissequamente la volontà.
Questa volontà può essere impressa nel software in modo relativamente trasparente tramite la programmazione linguistica (ad esempio in Python o in C) oppure essere impressa nel software in modo opaco, attraverso la selezione dei dati da utilizzare per la programmazione statistica e la progettazione della topologia della vector reducing machine che verrà programmata statisticamente.
Ora, tutti gli "stronzi" qui presenti che abbiano mai realizzato un software in prima persona, potranno confermarti di esistere.
Alcuni saranno ben lieti di non dover rispondere delle proprie creazioni, mentre altri si sentiranno oltraggiati dall'idea che qualcuno possa ignorare la propria esistenza come autori di quelle creazioni.
Ma tutti saranno consapevoli di aver LAVORATO per realizzare la sequenza di bit che le macchine elaborano automaticamente per produrre gli effetti che loro desiderano.
Il contributo dell'utente alla produzione dell'output di un software è completamente determinato dal programmatore e può variare moltissimo a seconda del software. Nel caso di ChatGPT, è oggettivamente trascurabile.
Per questa ragione, la responsabilità dell'output NON PUO' essere scaricata sull'utente con un banale disclaimer!
Quando leggo che "ChatGPT dichiara ONESTAMENTE di essere privo" di intenzionalità mi chiedo sinceramente se ci sia una qualche forza all'opera dietro questa allucinazione collettiva, dietro questa cancellazione delle persone che realizzano la macchina dalla tua coscienza, a cui gli sviluppatori siano talmente immuni da non percepirla.
No: chi ha scritto quel disclaimer NON è onesto. E non è stato Chat GPT a scrivere quel disclaimer.
Noti come Open AI sta manipolando la tua percezione della realtà?
Forse il semplice fatto di essere capaci a programmare statisticamente un software (e magari averlo programmato), rende naturalmente immuni a questa allucinazione.
Eppure si deve trattare di un'allucinazione molto forte se, come osservo qui, persone intelligenti ed in buona fede continuano a sostenerla NONOSTANTE altre persone, autorevoli, intelligenti ed altrettanto in buona fede, ma con una maggiore consapevolezza tecnica della questione, continuano a ripetere che il software è sempre realizzato da esseri umani e ne riproduce valori e interessi.
Ti prego di riflettere sulla questione: io esisto, Open AI esiste, Microsoft esiste, Google esiste etc... cosa ti costringe a cancellare la nostra esistenza dalla tua coscienza quando guardi un artefatto che realizza pedissequamente la nostra volontà?
Certo, una volta realizzato, un software diventa un agente cibernetico automatico, che "si muove da sé". Ma non è mai autonomo.
Anche quando varia il proprio stato interno in funzione dell'input, tale variazione è sempre meccanicamente determinata dalla sua programmazione (per quanto complessa e opaca sia essa sia).
Anche quando tale stato interno viene utilizzato insieme ad ogni nuovo input per calcolare nuovi output e nuove variazioni dello stato interno, ogni output e ogni variazione dello stato interno è meccanicamente determinato da chi ha programmato il software.
Dunque l'agente cibernetico automatico non è MAI autonomo.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro.
In assenza di tale autonomia, l'assenza di intenzionalità è irrilevante: il software riproduce le intenzioni di chi l'ha realizzato e ha deciso come deve essere usato.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla.
Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza.
In tal modo, l'intenzionalità (e la responsabilità legale) è tutta perfettamente determinata.
Giacomo _______________________________________________ nexa mailing listnexa@server-nexa.polito.ithttps://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

Molto interessate e azzeccato questo esempio, credo che lo citerò quando mi troverò a parlare di queste cose. Vorrei aggiungere un altro esempio concreto: l'altro giorno mia moglie è tornata dalla Finlandia con alcuni integratori: il contenuto e lo scopo erano reperibili su schede online in inglese, la posologia era disponibile solo in finlandese. Poco male: ho fotografato l'etichetta e me la sono fatta tradurre da Google. Naturalmente la traduzione non era perfetta, ma assolutamente comprensibile e di alto livello, e per arrivare a questi risultati si è inevitabilmente passati dalle prime traduzioni degli anni '90, che chi ha qualche capello bianco certamente ricorda con un sorriso. Certo Google non ha avuto nessuna consapevolezza di ciò che ha "letto" e risposto, ma ha raggiunto lo scopo. Anche se molti - anche in questa lista - non credono che potrà esserci un salto significativo nella qualità delle risposte delle AI, penso che solo pochi anni fa sarebbe stato impossibile che un computer generasse dei testi coerenti e gramaticalmente strutturati, anche in forme complesse, al di là della qualità e veridicità del contenuto. Qualità che peraltro a volte è elevata, a volte totalmente incosistente, ma sono convinto che negli anni mmigliorerà inevitabilmente, come sono migliorate le traduzioni (so che, dal punto di visto tecnico, si tratta di due tecnologie diverse, ma sto parlando di risultati). In questo momento, quindi, non ritengo tanto un problema che le risposte siano sbagliate, quanto il fatto che molti le prendano per buone in modo acritico. Le immagini del Papa con il piumino o di Trump arrestato erano state dichiarate false apertamente dallo stesso autore, ma sono ugualmente rimbalzate in tutto il mondo senza alcun filtro. Se Crozza o qualche altro comico imita un personaggio, nessuno pensa che sia un servizio di cronaca del TG, da prendere sul serio. Fino a quando le risposte dell'AI verranno prese con lo stesso spirito, fin quando verranno usate per quello che valgono, si potrà utilizzare serenamente l'AI, sfruttandola per quello che può dare di buono e migliorandola nel tempo. Se invece un'AI apparentemente buona contribuirà concretamente allo sviluppo dell'idiozia umana, allora meglio fermarsi subito. D. ________________________________ From: nexa <nexa-bounces@server-nexa.polito.it> on behalf of Guido Vetere <vetere.guido@gmail.com> Sent: Tuesday, April 4, 2023 10:16 AM To: Alberto Cammozzo <ac+nexa@zeromx.net> Cc: nexa@server-nexa.polito.it <nexa@server-nexa.polito.it> Subject: Re: [nexa] ChatGPT disabled for users in Italy Cari Giacomo e Alberto, il vostro punto di vista è molto interessante e vi ringrazio per averlo esposto con tanta coraggiosa assertività. Lo condivido senz'altro per tutto ciò che riguarda la programmazione imperativa e quella basata sulla rappresentazione della conoscenza e il ragionamento automatico. Se però consideriamo gli sviluppi dell'IA degli ultimi anni, e in particolare i LLM, le cose sono a mio avviso più complesse. Non mi inoltro in argomentazioni metafisiche per non tediare chi legge e perché non ho molto tempo. Propongo invece un piccolo sketch, forse ingenuo, che però può far riflettere. Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce. Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà? Secondo me no, ma se ne può parlare. Buona giornata. G. On Tue, 4 Apr 2023 at 11:46, Alberto Cammozzo via nexa <nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it>> wrote: Intervengo a conferma di quanto dice Giacomo sulla presunzione di neutralità degli artefatti tecnologici. Ho chiesto a phind.com<http://phind.com> cosa è successo in piazza Tien An Men. Mi ha risposto citando i massacri e esponendo i diversi punti di vista, incluso quello del governo cinese. Allora ho chiesto: Is this the same answer you give to users in China? Answer: As an AI language model, I do not have the ability to determine the location of the user or the restrictions on information in their country. However, my answer is based on factual information and sources that are publicly available. The information I provided is objective and does not contain any political bias. Con buona pace di decenni di dibattiti sulla politicità (intrinseca o meno) degli artefatti tecnologici, sulla loro agency, sulla normatività del codice... La pretesa di neutralità è ingannevole: ogni artefatto, specie questi così complessi, incorporano normatività. I tecnologi che continuano a credere di costruire artefatti neutri e consegnarli nelle mani di persone che ne saranno responsabili negano (forse in primo luogo a se stessi) l'evidenza che gli artefatti incorporano l'intenzionalità e la normatività di chi li inventa e di chi paga chi li inventa. Alberto On 04/04/23 10:56, Giacomo Tesio wrote: Ciao Guido, trovo veramente affascinante (quanto inquietante) questo passaggio della tua email: On Tue, 4 Apr 2023 06:52:24 +0200 Guido Vetere wrote: Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo. Come diversi informatici in lista ti possono confermare, lo "stronzo" dietro un software è sempre chi lo programma e ne controlla l'esecuzione. Un software infatti applica all'ambiente SEMPRE e ANZITUTTO la volontà di chi l'ha programmato (e nel caso di un SaaS, eseguito), riproducendola ed imponendola a tutti coloro che sono parte, volenti o nolenti, della organizzazione cibernetica in cui tale software opera. Nel caso di ChatGPT, lo "stronzo" (nel senso di Frankfurt) è Open AI. Nel caso di GitHub Copilot, lo "stronzo" è GitHub. Entrambi si leggono "Microsoft". Nel caso di Google Assistant, lo "stronzo" è Google/Alphabet. Nel caso dei risultati di ricerca o delle news "personalizzate" fornite dai servizi di Google, lo "stronzo" è Google/Alphabet. Nel caso della timeline Instagram o Facebook, lo "stronzo" è Facebook. Nel caso della timeline TikTok, lo "stronzo" è TikTok. Nel caso dell'amica virtuale "Replika", lo "stronzo" è Luka, Inc. Nel caso dell'osservatorio di Monitora PA, lo "stronzo" sono io. (e con me i molti che contribuiscono al suo sviluppo...) Il punto è: che si tratti di bug (come può essere un falso positivo prodotto dall'osservatorio di Monitora PA) o di scelte progettuali c'è sempre almeno un essere umano di cui il software riproduce pedissequamente la volontà. Questa volontà può essere impressa nel software in modo relativamente trasparente tramite la programmazione linguistica (ad esempio in Python o in C) oppure essere impressa nel software in modo opaco, attraverso la selezione dei dati da utilizzare per la programmazione statistica e la progettazione della topologia della vector reducing machine che verrà programmata statisticamente. Ora, tutti gli "stronzi" qui presenti che abbiano mai realizzato un software in prima persona, potranno confermarti di esistere. Alcuni saranno ben lieti di non dover rispondere delle proprie creazioni, mentre altri si sentiranno oltraggiati dall'idea che qualcuno possa ignorare la propria esistenza come autori di quelle creazioni. Ma tutti saranno consapevoli di aver LAVORATO per realizzare la sequenza di bit che le macchine elaborano automaticamente per produrre gli effetti che loro desiderano. Il contributo dell'utente alla produzione dell'output di un software è completamente determinato dal programmatore e può variare moltissimo a seconda del software. Nel caso di ChatGPT, è oggettivamente trascurabile. Per questa ragione, la responsabilità dell'output NON PUO' essere scaricata sull'utente con un banale disclaimer! Quando leggo che "ChatGPT dichiara ONESTAMENTE di essere privo" di intenzionalità mi chiedo sinceramente se ci sia una qualche forza all'opera dietro questa allucinazione collettiva, dietro questa cancellazione delle persone che realizzano la macchina dalla tua coscienza, a cui gli sviluppatori siano talmente immuni da non percepirla. No: chi ha scritto quel disclaimer NON è onesto. E non è stato Chat GPT a scrivere quel disclaimer. Noti come Open AI sta manipolando la tua percezione della realtà? Forse il semplice fatto di essere capaci a programmare statisticamente un software (e magari averlo programmato), rende naturalmente immuni a questa allucinazione. Eppure si deve trattare di un'allucinazione molto forte se, come osservo qui, persone intelligenti ed in buona fede continuano a sostenerla NONOSTANTE altre persone, autorevoli, intelligenti ed altrettanto in buona fede, ma con una maggiore consapevolezza tecnica della questione, continuano a ripetere che il software è sempre realizzato da esseri umani e ne riproduce valori e interessi. Ti prego di riflettere sulla questione: io esisto, Open AI esiste, Microsoft esiste, Google esiste etc... cosa ti costringe a cancellare la nostra esistenza dalla tua coscienza quando guardi un artefatto che realizza pedissequamente la nostra volontà? Certo, una volta realizzato, un software diventa un agente cibernetico automatico, che "si muove da sé". Ma non è mai autonomo. Anche quando varia il proprio stato interno in funzione dell'input, tale variazione è sempre meccanicamente determinata dalla sua programmazione (per quanto complessa e opaca sia essa sia). Anche quando tale stato interno viene utilizzato insieme ad ogni nuovo input per calcolare nuovi output e nuove variazioni dello stato interno, ogni output e ogni variazione dello stato interno è meccanicamente determinato da chi ha programmato il software. Dunque l'agente cibernetico automatico non è MAI autonomo. On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote: La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro. In assenza di tale autonomia, l'assenza di intenzionalità è irrilevante: il software riproduce le intenzioni di chi l'ha realizzato e ha deciso come deve essere usato. On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote: Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla. Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza. In tal modo, l'intenzionalità (e la responsabilità legale) è tutta perfettamente determinata. Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa _______________________________________________ nexa mailing list nexa@server-nexa.polito.it<mailto:nexa@server-nexa.polito.it> https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
On mar, 2023-04-04 at 10:43 +0000, Diego Giorio wrote:
Molto interessate e azzeccato questo esempio, credo che lo citerò quando mi troverò a parlare di queste cose.
...
In questo momento, quindi, non ritengo tanto un problema che le risposte siano sbagliate, quanto il fatto che molti le prendano per buone in modo acritico. Le immagini del Papa con il piumino o di Trump arrestato erano state dichiarate false apertamente dallo stesso autore, ma sono ugualmente rimbalzate in tutto il mondo senza alcun filtro. Se Crozza o qualche altro comico imita un personaggio, nessuno pensa che sia un servizio di cronaca del TG, da prendere sul serio. Fino a quando le risposte dell'AI verranno prese con lo stesso spirito, fin quando verranno usate per quello che valgono, si potrà utilizzare serenamente l'AI, sfruttandola per quello che può dare di buono e migliorandola nel tempo. Se invece un'AI apparentemente buona contribuirà concretamente allo sviluppo dell'idiozia umana, allora meglio fermarsi subito.
Ciao Diego, il problema non è il tasso di esattezza delle risposte, generate a caso da un LLM, ma è il fatto che si fa **di tutto ** per ingannare il pubblico in generale, facendogli pensare che vi sia "Intelligenza" e "Comprensione", e che quindi abbia un senso fargli domande ed utilizzare le risposte. Il problema è che il suddetto pubblico sta cominciando a crederci in massa, e mentre quando crede alle cartomanti non c'è un pericolo globale, se comincia a credere a qualsiasi cosa sappia mettere in fila le parole, e la suddetta cosa ha un unico padrone globale, sarà nelle mani di chi controlla quella cosa. Non esistono solo le interessantissime questioni qui sollevate e discusse, che io leggo assiduamente e perlopiù in religioso silenzio, ma esiste anche l'uso concreto ed attuale di questi oggetti come armi di disinformazione di massa. Vedremo presto crollare l'infosfera, divorata dall'interno dai questi generatori di stronzate; se non è ora il momento di preoccuparsi, allora quando? "La paranoia è una virtù". Scusate lo sfogo. Marco
From: nexa <nexa-bounces@server-nexa.polito.it> on behalf of Guido Vetere <vetere.guido@gmail.com> Sent: Tuesday, April 4, 2023 10:16 AM To: Alberto Cammozzo <ac+nexa@zeromx.net> Cc: nexa@server-nexa.polito.it <nexa@server-nexa.polito.it> Subject: Re: [nexa] ChatGPT disabled for users in Italy Cari Giacomo e Alberto, il vostro punto di vista è molto interessante e vi ringrazio per averlo esposto con tanta coraggiosa assertività. Lo condivido senz'altro per tutto ciò che riguarda la programmazione imperativa e quella basata sulla rappresentazione della conoscenza e il ragionamento automatico. Se però consideriamo gli sviluppi dell'IA degli ultimi anni, e in particolare i LLM, le cose sono a mio avviso più complesse. Non mi inoltro in argomentazioni metafisiche per non tediare chi legge e perché non ho molto tempo. Propongo invece un piccolo sketch, forse ingenuo, che però può far riflettere. Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce. Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà? Secondo me no, ma se ne può parlare. Buona giornata. G.
On Tue, 4 Apr 2023 at 11:46, Alberto Cammozzo via nexa <nexa@server-nexa.polito.it> wrote:
Intervengo a conferma di quanto dice Giacomo sulla presunzione di neutralità degli artefatti tecnologici. Ho chiesto a phind.com cosa è successo in piazza Tien An Men. Mi ha risposto citando i massacri e esponendo i diversi punti di vista, incluso quello del governo cinese. Allora ho chiesto:
Is this the same answer you give to users in China? Answer: As an AI language model, I do not have the ability to determine the location of the user or the restrictions on information in their country. However, my answer is based on factual information and sources that are publicly available. The information I provided is objective and does not contain any political bias. Con buona pace di decenni di dibattiti sulla politicità (intrinseca o meno) degli artefatti tecnologici, sulla loro agency, sulla normatività del codice... La pretesa di neutralità è ingannevole: ogni artefatto, specie questi così complessi, incorporano normatività. I tecnologi che continuano a credere di costruire artefatti neutri e consegnarli nelle mani di persone che ne saranno responsabili negano (forse in primo luogo a se stessi) l'evidenza che gli artefatti incorporano l'intenzionalità e la normatività di chi li inventa e di chi paga chi li inventa.
Alberto
On 04/04/23 10:56, Giacomo Tesio wrote:
Ciao Guido,
trovo veramente affascinante (quanto inquietante) questo passaggio della tua email:
On Tue, 4 Apr 2023 06:52:24 +0200 Guido Vetere wrote:
Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo. Come diversi informatici in lista ti possono confermare, lo "stronzo" dietro un software è sempre chi lo programma e ne controlla l'esecuzione.
Un software infatti applica all'ambiente SEMPRE e ANZITUTTO la volontà di chi l'ha programmato (e nel caso di un SaaS, eseguito), riproducendola ed imponendola a tutti coloro che sono parte, volenti o nolenti, della organizzazione cibernetica in cui tale software opera.
Nel caso di ChatGPT, lo "stronzo" (nel senso di Frankfurt) è Open AI. Nel caso di GitHub Copilot, lo "stronzo" è GitHub. Entrambi si leggono "Microsoft".
Nel caso di Google Assistant, lo "stronzo" è Google/Alphabet. Nel caso dei risultati di ricerca o delle news "personalizzate" fornite dai servizi di Google, lo "stronzo" è Google/Alphabet.
Nel caso della timeline Instagram o Facebook, lo "stronzo" è Facebook.
Nel caso della timeline TikTok, lo "stronzo" è TikTok.
Nel caso dell'amica virtuale "Replika", lo "stronzo" è Luka, Inc.
Nel caso dell'osservatorio di Monitora PA, lo "stronzo" sono io. (e con me i molti che contribuiscono al suo sviluppo...)
Il punto è: che si tratti di bug (come può essere un falso positivo prodotto dall'osservatorio di Monitora PA) o di scelte progettuali c'è sempre almeno un essere umano di cui il software riproduce pedissequamente la volontà.
Questa volontà può essere impressa nel software in modo relativamente trasparente tramite la programmazione linguistica (ad esempio in Python o in C) oppure essere impressa nel software in modo opaco, attraverso la selezione dei dati da utilizzare per la programmazione statistica e la progettazione della topologia della vector reducing machine che verrà programmata statisticamente.
Ora, tutti gli "stronzi" qui presenti che abbiano mai realizzato un software in prima persona, potranno confermarti di esistere.
Alcuni saranno ben lieti di non dover rispondere delle proprie creazioni, mentre altri si sentiranno oltraggiati dall'idea che qualcuno possa ignorare la propria esistenza come autori di quelle creazioni.
Ma tutti saranno consapevoli di aver LAVORATO per realizzare la sequenza di bit che le macchine elaborano automaticamente per produrre gli effetti che loro desiderano.
Il contributo dell'utente alla produzione dell'output di un software è completamente determinato dal programmatore e può variare moltissimo a seconda del software. Nel caso di ChatGPT, è oggettivamente trascurabile.
Per questa ragione, la responsabilità dell'output NON PUO' essere scaricata sull'utente con un banale disclaimer!
Quando leggo che "ChatGPT dichiara ONESTAMENTE di essere privo" di intenzionalità mi chiedo sinceramente se ci sia una qualche forza all'opera dietro questa allucinazione collettiva, dietro questa cancellazione delle persone che realizzano la macchina dalla tua coscienza, a cui gli sviluppatori siano talmente immuni da non percepirla.
No: chi ha scritto quel disclaimer NON è onesto. E non è stato Chat GPT a scrivere quel disclaimer.
Noti come Open AI sta manipolando la tua percezione della realtà?
Forse il semplice fatto di essere capaci a programmare statisticamente un software (e magari averlo programmato), rende naturalmente immuni a questa allucinazione.
Eppure si deve trattare di un'allucinazione molto forte se, come osservo qui, persone intelligenti ed in buona fede continuano a sostenerla NONOSTANTE altre persone, autorevoli, intelligenti ed altrettanto in buona fede, ma con una maggiore consapevolezza tecnica della questione, continuano a ripetere che il software è sempre realizzato da esseri umani e ne riproduce valori e interessi.
Ti prego di riflettere sulla questione: io esisto, Open AI esiste, Microsoft esiste, Google esiste etc... cosa ti costringe a cancellare la nostra esistenza dalla tua coscienza quando guardi un artefatto che realizza pedissequamente la nostra volontà?
Certo, una volta realizzato, un software diventa un agente cibernetico automatico, che "si muove da sé". Ma non è mai autonomo.
Anche quando varia il proprio stato interno in funzione dell'input, tale variazione è sempre meccanicamente determinata dalla sua programmazione (per quanto complessa e opaca sia essa sia).
Anche quando tale stato interno viene utilizzato insieme ad ogni nuovo input per calcolare nuovi output e nuove variazioni dello stato interno, ogni output e ogni variazione dello stato interno è meccanicamente determinato da chi ha programmato il software.
Dunque l'agente cibernetico automatico non è MAI autonomo.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro. In assenza di tale autonomia, l'assenza di intenzionalità è irrilevante: il software riproduce le intenzioni di chi l'ha realizzato e ha deciso come deve essere usato.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla. Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza.
In tal modo, l'intenzionalità (e la responsabilità legale) è tutta perfettamente determinata.
Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Ciao Guido, Diego e Nexa, On Tue, 4 Apr 2023 12:16:48 +0200 Guido Vetere wrote:
il vostro punto di vista è molto interessante e vi ringrazio per averlo esposto con tanta coraggiosa assertività.
:-D Quando un hacker ti pone delle domande, non pensare di potertela cavare con una battuta! ;-) Comunque concordo con Diego: il tuo esempio è molto azzecato. Purtroppo la domanda che poni è irrilevante. (e conseguentemente, la risposta che proponi)
Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce.
Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà?
La relazione causale rispetto a ciò che mangerete è irrilevante. Ciò che rileva è che entrambi avete scelto liberamente COME selezionare il vostro menù: tu alla luce di una valutazione gastronomica, lui sulla base di un automatismo di cui comprende pienamente il funzionamento. Il tuo amico decide il numero di facce, il numero di lanci, e conseguentemente la probabilità relativa dei diversi risultati, nonché l'interpretazione da attribuire a ciascun risultato (si conta dal fondo o dall'inizio? si sottrae il prodotto fra numero di dadi e lanci al risultato? etc..) Il dado è dunque solo uno strumento del tuo amico. Potrebbe farne tranquillamente a meno, accontentandosi di un numero pensato "a caso". Per fare un esempio più calzante, ipotiziamo che il cuoco decida gli ingredienti del vostro pasto sulla base del colore dei vostri vestiti e di lanci di un dado. Gli ingredienti sono infatti in barattoli colorati e numerati, ma senza etichetta. Prima di farvi accomodare, il cameriere robotizzato vi informa chiaramente che occasionalmente le pietanze potrebbero contenere combinazioni indigeste o persino tossiche degli ingredienti (ciascuno di per sé commestibile in isolamento), senza che il cuoco possa in alcun modo essere ritenuto responsabile per eventuali, occasionali, decessi. Voi vi sedete comunque, pensando si tratti di uno scherzo. In fondo il ristorante è pieno di persone che sembrano assaporare con grande soddisfazione piatti assolutamente deliziosi. Alla fine del pasto, il tuo ipotetico amico muore. Secondo te, il cuoco è responsabile della sua morte? Il fatto di avervi avvertito con un chiaro disclaimer, allevia la sua responsabilità penale? E se la preparazione e la cottura della pietanza fosse completamente meccanizzata? Ne risponderebbe il proprietario del locale? E se invece di morire alla fine del pranzo a causa delle sostanze ingerite, il tuo amico si ammalasse di cancro e gravasse sul servizio sanitario nazionale per decenni insieme al 5-10% degli avventori del ristorante? Laddove un'autorità competente chiedesse conto dei danni prodotti al proprietario, ti strapperesti le vesti? Il proprietario del ristorante potrebbe argomentare di che il suo robot-cuoco non aveva alcuna intenzionalità e che voi che l'avete usato (peraltro, gratuitamente) eravate stati avvertiti con un chiaro disclaimer dei rischi?
Se però consideriamo gli sviluppi dell'IA degli ultimi anni, e in particolare i LLM, le cose sono a mio avviso più complesse. Non mi inoltro in argomentazioni metafisiche...
Non c'è niente di metafisico in un software programmato statisticamente. Cambia (in parte) il modo di programmare questi software rispetto alla programmazione linguistica (imperativa, funzionale, a oggetti etc...) ma non cambia il fatto che siano programmati: qualcuno li realizza per riprodurre automaticamente un certo comportamento. Il fatto che chi li programma dichiari di non avere piena comprensione del loro funzionamento, li rende semplicemente inutilizzabili. Ma non c'è alcuna ragione, etica, logica o metafisica, per cui dovremmo garantire a queste persone (e queste aziende) un salvacondotto dalla Legge per le violazioni compiute tramite questi agenti cibernetici automatici. Loro li costruiscono e li eseguono, dunque loro ne devono rispondere. Giacomo
Al di là dell'iperbole, com'è naturale nell'esempio, se ho colto correttamente il senso della tua domanda, la mia risposta, non giuridica, ma legata alla mia personale personale, è che un disclaimer (se chiaro e comprensibile: né le righe scritte in piccolo delle assicurazioni, né le 50 pagine di certe privacy policy) non solleva dalla responsabilità, ma aiuta certo a condividerla: per quanto un esempio abbia sempre dei limiti, propongo questa situazione: mio figlio di 5 anni è gravemente allergico alle uova. Se mi arrivano delle polpette o una trota al forno, con scritto "non contiene uova" e poi risultano invece presenti la responsabilità è del ristoratore. Ma se arrivano delle uova sode o all'occhio di bue, anche se per sbaglio c'è scritto "senza uova" sono comunque responsabile nel darle al figlio (mi correggano i giuristi se sbaglio), perché devo analizzare criticamente quello che c'è scritto e confrontarlo con quello che c'è nel piatto. Io ho avuto un principio di distacco della retina e un distacco del vitreo: anche se non c'è scritto in biglietteria, so che non devo salire sulle montagne russe o su una giostra che scuote eccessivamente o guidare una formula1, così come se scalo un 4000 devo sapere che l'aria è rarefatta pur senza un cartello all'attacco della via. L'idea che tutto debba essere descritto, elencato, pensato a prova di idiota creerà un mondo dove solo gli idioti si trovano benissimo, ed è questo il mio più grande timore nei confronti dell'AI: un mondo dove uno studente, un principiante, un apprendista, un pigro non deve pensare, perché c'è un'AI che pensa per lui e tutto viene accettato passivamente. E qui arrivo alla mail di Marco, con il quale evidentemente siamo in sintonia, anche se abbiamo espresso l'idea in modo diverso: il problema non è la veggente che ti legge il futuro nei fondi del caffè o nelle carte, il problema è che qualcuno le vada dietro. Il problema non è Paolo Fox che a inizio 2020 prevedeva un periodo favorevole per i viaggi nei primi mesi dell'anno, il problema è che, pur dopo la pandemia e il lockdown, continui a stare in TV, perché ancora qualcuno lo segue. Ecco allora che il mio timore non è che ChatGPT dica - erroneamente - che ho subito una qualche condanna per crimini infamanti, il mio timore è che un giornalista o un datore di lavoro la prenda per buona senza controllare. Peraltro il problema non è nuovo (tanto per dirne una, pensiamo ai diari di Hitler - falsi - che Panorama aveva comprato a caro prezzo) ma l'AI aumenterà enormemente la magnitudo. Un amico che scriveva un libro, dove parlava tra le altre cose della medaglia di San Benedetto, mi ha chiesto aiuto perché non riusciva a trovare informazioni sulle prime versioni. Ho provato con ChatGPT e, dopo una prima risposta errata, ho riformulato la domanda in linguaggio naturale, come avrei fatto con uno studente, e mi ha scovato varie informazioni. Cambiando la parole chiave su Google e mobilitando alcuni suoi contatti a Norcia ha trovato conferma di ciò che l'AI aveva prodotto, il che mi sembra un ottimo esempio sia di utilità del sistema, che è riuscita dove i motori di ricerca avevano fallito, ma anche di uso responsabile, dato che non si è accettato passivamente l'oracolo ma si è andati a verificare alle fonti d'archivio. L'AI, per me, è uno strumento come un altro (beh, certo più potente e quindi pericoloso di altri, ma d'altra parte anche la bomba atomica non scherza), che ancora dobbiamo imparare a usare; il fatto che si svilupperà in positivo o meno dipende da noi e in questo senso ben vengano iniziative come quelle del Garante, che, giuste o sbagliate, scritte bene o male, comunque aiutano a tenere alta l'attenzione, come dimostra il vivace dibattito anche su questa lista. Scusatemi la mail un po' lunga Un buon fine settimana a tutti e buona Pasqua a voi e famiglie D. ________________________________ From: nexa <nexa-bounces@server-nexa.polito.it> on behalf of Giacomo Tesio <giacomo@tesio.it> Sent: Tuesday, April 4, 2023 1:06 PM To: Guido Vetere <vetere.guido@gmail.com> Cc: nexa@server-nexa.polito.it <nexa@server-nexa.polito.it> Subject: Re: [nexa] ChatGPT disabled for users in Italy Ciao Guido, Diego e Nexa, On Tue, 4 Apr 2023 12:16:48 +0200 Guido Vetere wrote:
il vostro punto di vista è molto interessante e vi ringrazio per averlo esposto con tanta coraggiosa assertività.
:-D Quando un hacker ti pone delle domande, non pensare di potertela cavare con una battuta! ;-) Comunque concordo con Diego: il tuo esempio è molto azzecato. Purtroppo la domanda che poni è irrilevante. (e conseguentemente, la risposta che proponi)
Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce.
Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà?
La relazione causale rispetto a ciò che mangerete è irrilevante. Ciò che rileva è che entrambi avete scelto liberamente COME selezionare il vostro menù: tu alla luce di una valutazione gastronomica, lui sulla base di un automatismo di cui comprende pienamente il funzionamento. Il tuo amico decide il numero di facce, il numero di lanci, e conseguentemente la probabilità relativa dei diversi risultati, nonché l'interpretazione da attribuire a ciascun risultato (si conta dal fondo o dall'inizio? si sottrae il prodotto fra numero di dadi e lanci al risultato? etc..) Il dado è dunque solo uno strumento del tuo amico. Potrebbe farne tranquillamente a meno, accontentandosi di un numero pensato "a caso". Per fare un esempio più calzante, ipotiziamo che il cuoco decida gli ingredienti del vostro pasto sulla base del colore dei vostri vestiti e di lanci di un dado. Gli ingredienti sono infatti in barattoli colorati e numerati, ma senza etichetta. Prima di farvi accomodare, il cameriere robotizzato vi informa chiaramente che occasionalmente le pietanze potrebbero contenere combinazioni indigeste o persino tossiche degli ingredienti (ciascuno di per sé commestibile in isolamento), senza che il cuoco possa in alcun modo essere ritenuto responsabile per eventuali, occasionali, decessi. Voi vi sedete comunque, pensando si tratti di uno scherzo. In fondo il ristorante è pieno di persone che sembrano assaporare con grande soddisfazione piatti assolutamente deliziosi. Alla fine del pasto, il tuo ipotetico amico muore. Secondo te, il cuoco è responsabile della sua morte? Il fatto di avervi avvertito con un chiaro disclaimer, allevia la sua responsabilità penale? E se la preparazione e la cottura della pietanza fosse completamente meccanizzata? Ne risponderebbe il proprietario del locale? E se invece di morire alla fine del pranzo a causa delle sostanze ingerite, il tuo amico si ammalasse di cancro e gravasse sul servizio sanitario nazionale per decenni insieme al 5-10% degli avventori del ristorante? Laddove un'autorità competente chiedesse conto dei danni prodotti al proprietario, ti strapperesti le vesti? Il proprietario del ristorante potrebbe argomentare di che il suo robot-cuoco non aveva alcuna intenzionalità e che voi che l'avete usato (peraltro, gratuitamente) eravate stati avvertiti con un chiaro disclaimer dei rischi?
Se però consideriamo gli sviluppi dell'IA degli ultimi anni, e in particolare i LLM, le cose sono a mio avviso più complesse. Non mi inoltro in argomentazioni metafisiche...
Non c'è niente di metafisico in un software programmato statisticamente. Cambia (in parte) il modo di programmare questi software rispetto alla programmazione linguistica (imperativa, funzionale, a oggetti etc...) ma non cambia il fatto che siano programmati: qualcuno li realizza per riprodurre automaticamente un certo comportamento. Il fatto che chi li programma dichiari di non avere piena comprensione del loro funzionamento, li rende semplicemente inutilizzabili. Ma non c'è alcuna ragione, etica, logica o metafisica, per cui dovremmo garantire a queste persone (e queste aziende) un salvacondotto dalla Legge per le violazioni compiute tramite questi agenti cibernetici automatici. Loro li costruiscono e li eseguono, dunque loro ne devono rispondere. Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa

dal sito del Garante ChatGPT: domani incontro tra OpenAI e Garante privacy <https://www.garanteprivacy.it/home/docweb/-/docweb-display/docweb/9872284#> <https://www.garanteprivacy.it/home/docweb/-/docweb-display/docweb/9872284#english_version>- English version <https://www.garanteprivacy.it/home/docweb/-/docweb-display/docweb/9872284#en...> *ChatGPT: domani incontro tra OpenAI e Garante privacy* E’ previsto per domani sera un incontro, in videoconferenza, tra i rappresentanti di OpenAI e il Garante per la protezione dei dati personali, che nei giorni scorsi ha imposto <https://www.garanteprivacy.it/garante/doc.jsp?ID=9870847>alla piattaforma di limitare temporaneamente il trattamento dei dati degli utenti italiani finché non si sarà messa in regola con la normativa privacy italiana e europea. L’iniziativa, apprezzata dal Garante, fa seguito alla lettera con cui ieri la società statunitense ha risposto al Garante per esprimere la propria disponibilità immediata a collaborare con l’Autorità italiana al fine di rispettare la disciplina privacy europea e giungere a una soluzione condivisa in grado di risolvere i profili critici sollevati dall’Autorità in merito al trattamento dei dati dei cittadini italiani. *Roma, 4 aprile 2023* *Un caro saluto* *Mauro* Il giorno mar 4 apr 2023 alle ore 21:33 Diego Giorio <dgiorio@hotmail.com> ha scritto:
Al di là dell'iperbole, com'è naturale nell'esempio, se ho colto correttamente il senso della tua domanda, la mia risposta, non giuridica, ma legata alla mia personale personale, è che un disclaimer (se chiaro e comprensibile: né le righe scritte in piccolo delle assicurazioni, né le 50 pagine di certe privacy policy) non solleva dalla responsabilità, ma aiuta certo a condividerla: per quanto un esempio abbia sempre dei limiti, propongo questa situazione: mio figlio di 5 anni è gravemente allergico alle uova. Se mi arrivano delle polpette o una trota al forno, con scritto "non contiene uova" e poi risultano invece presenti la responsabilità è del ristoratore. Ma se arrivano delle uova sode o all'occhio di bue, anche se per sbaglio c'è scritto "senza uova" sono comunque responsabile nel darle al figlio (mi correggano i giuristi se sbaglio), perché devo analizzare criticamente quello che c'è scritto e confrontarlo con quello che c'è nel piatto. Io ho avuto un principio di distacco della retina e un distacco del vitreo: anche se non c'è scritto in biglietteria, so che non devo salire sulle montagne russe o su una giostra che scuote eccessivamente o guidare una formula1, così come se scalo un 4000 devo sapere che l'aria è rarefatta pur senza un cartello all'attacco della via.
L'idea che tutto debba essere descritto, elencato, pensato a prova di idiota creerà un mondo dove solo gli idioti si trovano benissimo, ed è questo il mio più grande timore nei confronti dell'AI: un mondo dove uno studente, un principiante, un apprendista, un pigro non deve pensare, perché c'è un'AI che pensa per lui e tutto viene accettato passivamente.
E qui arrivo alla mail di Marco, con il quale evidentemente siamo in sintonia, anche se abbiamo espresso l'idea in modo diverso: il problema non è la veggente che ti legge il futuro nei fondi del caffè o nelle carte, il problema è che qualcuno le vada dietro. Il problema non è Paolo Fox che a inizio 2020 prevedeva un periodo favorevole per i viaggi nei primi mesi dell'anno, il problema è che, pur dopo la pandemia e il lockdown, continui a stare in TV, perché ancora qualcuno lo segue.
Ecco allora che il mio timore non è che ChatGPT dica - erroneamente - che ho subito una qualche condanna per crimini infamanti, il mio timore è che un giornalista o un datore di lavoro la prenda per buona senza controllare. Peraltro il problema non è nuovo (tanto per dirne una, pensiamo ai diari di Hitler - falsi - che Panorama aveva comprato a caro prezzo) ma l'AI aumenterà enormemente la magnitudo.
Un amico che scriveva un libro, dove parlava tra le altre cose della medaglia di San Benedetto, mi ha chiesto aiuto perché non riusciva a trovare informazioni sulle prime versioni. Ho provato con ChatGPT e, dopo una prima risposta errata, ho riformulato la domanda in linguaggio naturale, come avrei fatto con uno studente, e mi ha scovato varie informazioni. Cambiando la parole chiave su Google e mobilitando alcuni suoi contatti a Norcia ha trovato conferma di ciò che l'AI aveva prodotto, il che mi sembra un ottimo esempio sia di utilità del sistema, che è riuscita dove i motori di ricerca avevano fallito, ma anche di uso responsabile, dato che non si è accettato passivamente l'oracolo ma si è andati a verificare alle fonti d'archivio.
L'AI, per me, è uno strumento come un altro (beh, certo più potente e quindi pericoloso di altri, ma d'altra parte anche la bomba atomica non scherza), che ancora dobbiamo imparare a usare; il fatto che si svilupperà in positivo o meno dipende da noi e in questo senso ben vengano iniziative come quelle del Garante, che, giuste o sbagliate, scritte bene o male, comunque aiutano a tenere alta l'attenzione, come dimostra il vivace dibattito anche su questa lista.
Scusatemi la mail un po' lunga
Un buon fine settimana a tutti e buona Pasqua a voi e famiglie D.
------------------------------ *From:* nexa <nexa-bounces@server-nexa.polito.it> on behalf of Giacomo Tesio <giacomo@tesio.it> *Sent:* Tuesday, April 4, 2023 1:06 PM *To:* Guido Vetere <vetere.guido@gmail.com> *Cc:* nexa@server-nexa.polito.it <nexa@server-nexa.polito.it> *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
Ciao Guido, Diego e Nexa,
On Tue, 4 Apr 2023 12:16:48 +0200 Guido Vetere wrote:
il vostro punto di vista è molto interessante e vi ringrazio per averlo esposto con tanta coraggiosa assertività.
:-D
Quando un hacker ti pone delle domande, non pensare di potertela cavare con una battuta! ;-)
Comunque concordo con Diego: il tuo esempio è molto azzecato. Purtroppo la domanda che poni è irrilevante. (e conseguentemente, la risposta che proponi)
Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce.
Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà?
La relazione causale rispetto a ciò che mangerete è irrilevante.
Ciò che rileva è che entrambi avete scelto liberamente COME selezionare il vostro menù: tu alla luce di una valutazione gastronomica, lui sulla base di un automatismo di cui comprende pienamente il funzionamento. Il tuo amico decide il numero di facce, il numero di lanci, e conseguentemente la probabilità relativa dei diversi risultati, nonché l'interpretazione da attribuire a ciascun risultato (si conta dal fondo o dall'inizio? si sottrae il prodotto fra numero di dadi e lanci al risultato? etc..)
Il dado è dunque solo uno strumento del tuo amico. Potrebbe farne tranquillamente a meno, accontentandosi di un numero pensato "a caso".
Per fare un esempio più calzante, ipotiziamo che il cuoco decida gli ingredienti del vostro pasto sulla base del colore dei vostri vestiti e di lanci di un dado. Gli ingredienti sono infatti in barattoli colorati e numerati, ma senza etichetta.
Prima di farvi accomodare, il cameriere robotizzato vi informa chiaramente che occasionalmente le pietanze potrebbero contenere combinazioni indigeste o persino tossiche degli ingredienti (ciascuno di per sé commestibile in isolamento), senza che il cuoco possa in alcun modo essere ritenuto responsabile per eventuali, occasionali, decessi.
Voi vi sedete comunque, pensando si tratti di uno scherzo. In fondo il ristorante è pieno di persone che sembrano assaporare con grande soddisfazione piatti assolutamente deliziosi.
Alla fine del pasto, il tuo ipotetico amico muore.
Secondo te, il cuoco è responsabile della sua morte? Il fatto di avervi avvertito con un chiaro disclaimer, allevia la sua responsabilità penale?
E se la preparazione e la cottura della pietanza fosse completamente meccanizzata? Ne risponderebbe il proprietario del locale?
E se invece di morire alla fine del pranzo a causa delle sostanze ingerite, il tuo amico si ammalasse di cancro e gravasse sul servizio sanitario nazionale per decenni insieme al 5-10% degli avventori del ristorante?
Laddove un'autorità competente chiedesse conto dei danni prodotti al proprietario, ti strapperesti le vesti?
Il proprietario del ristorante potrebbe argomentare di che il suo robot-cuoco non aveva alcuna intenzionalità e che voi che l'avete usato (peraltro, gratuitamente) eravate stati avvertiti con un chiaro disclaimer dei rischi?
Se però consideriamo gli sviluppi dell'IA degli ultimi anni, e in particolare i LLM, le cose sono a mio avviso più complesse. Non mi inoltro in argomentazioni metafisiche...
Non c'è niente di metafisico in un software programmato statisticamente.
Cambia (in parte) il modo di programmare questi software rispetto alla programmazione linguistica (imperativa, funzionale, a oggetti etc...) ma non cambia il fatto che siano programmati: qualcuno li realizza per riprodurre automaticamente un certo comportamento.
Il fatto che chi li programma dichiari di non avere piena comprensione del loro funzionamento, li rende semplicemente inutilizzabili.
Ma non c'è alcuna ragione, etica, logica o metafisica, per cui dovremmo garantire a queste persone (e queste aziende) un salvacondotto dalla Legge per le violazioni compiute tramite questi agenti cibernetici automatici.
Loro li costruiscono e li eseguono, dunque loro ne devono rispondere.
Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Caro Guido, la "coraggiosa assertività" sarebbe arroganza se questo dibattito non fosse già avvenuto diverse volte in almeno 40 anni di ricerca in ambito socio-politico e non solo, nel tentativo di superare le posizioni semplicistiche tra i due estremi che vedono o la tecnologia come mera espressione della società o all'opposto come ciò che la plasma. Possono esservi divergenze anche sostanziose, ma nessuno più nega che gli artefatti incorporino normatività e al contrario afferma che non possano avere alcun bias, fosse solo culturale (di chi progetta e di coloro per cui sono progettati) o di modello economico e di business nel quale si inseriscono. Da Langdon Winner in poi si cerca di articolare la politicità dell'artefatto in uno spettro tra un estremo di politicità intrinseca per cui lo strumento richiede un certo tipo di relazioni di potere ed un altro che vede una prevalenza degli attori sociali nel determinare l'uso di una tecnologia. Addirittura per Bruno Latour gli artefatti si affiancano all'essere umano ed alle istituzioni nella co-creazione del contesto sociale. In ogni caso mi pare sia superata sia la visione di uno strumento tecnologico neutrale, che quella che lo vede sempre espressione di una intenzione politica: il buon ChatGPT dovrebbe prenderne atto invece che oracolare /pro domo sua/. In questo contesto non vedo nessun elemento di novità negli artefatti con comportamento stocastico che possa rimettere in discussione la loro neutralità. Forse mi sfugge qualcosa? Quanto è in discussione non è cosa cambia se una cosa la fa una macchina che copia gli umani o se uno deve farsela da solo, è l'equilibrio tra i vari elementi regolativi in una società: economia, legge, norme sociali, architettura/codice (per citare Lessig), sapendo che lo sviluppo troppo veloce di certe architetture e la lentezza di norme e leggi a stare dietro mette in difficoltà questi equilibri. Se ho compreso la tua allegoria, non si tratta di decidere come ordinare al ristorante, ma se ci sono ristoranti o si può solo ordinare online, chi può pagare o no, chi sta cucina, se le ricette sono anch'esse con ingredienti randomizzati... Buona giornata, Alberto On 04/04/23 12:16, Guido Vetere wrote:
Cari Giacomo e Alberto, il vostro punto di vista è molto interessante e vi ringrazio per averlo esposto con tanta coraggiosa assertività. Lo condivido senz'altro per tutto ciò che riguarda la programmazione imperativa e quella basata sulla rappresentazione della conoscenza e il ragionamento automatico. Se però consideriamo gli sviluppi dell'IA degli ultimi anni, e in particolare i LLM, le cose sono a mio avviso più complesse. Non mi inoltro in argomentazioni metafisiche per non tediare chi legge e perché non ho molto tempo. Propongo invece un piccolo sketch, forse ingenuo, che però può far riflettere. Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce. Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà? Secondo me no, ma se ne può parlare. Buona giornata. G.
On Tue, 4 Apr 2023 at 11:46, Alberto Cammozzo via nexa <nexa@server-nexa.polito.it> wrote:
Intervengo a conferma di quanto dice Giacomo sulla /presunzione di neutralità/ degli artefatti tecnologici.
Ho chiesto a phind.com <http://phind.com> cosa è successo in piazza Tien An Men.
Mi ha risposto citando i massacri e esponendo i diversi punti di vista, incluso quello del governo cinese.
Allora ho chiesto:
Is this the same answer you give to users in China? Answer:
As an AI language model, I do not have the ability to determine the location of the user or the restrictions on information in their country. However, my answer is based on factual information and sources that are publicly available. The information I provided is objective and does not contain any political bias.
Con buona pace di decenni di dibattiti sulla politicità (intrinseca o meno) degli artefatti tecnologici, sulla loro agency, sulla normatività del codice...
La pretesa di neutralità è ingannevole: ogni artefatto, specie questi così complessi, incorporano normatività.
I tecnologi che continuano a credere di costruire artefatti neutri e consegnarli nelle mani di persone che ne saranno responsabili negano (forse in primo luogo a se stessi) l'evidenza che gli artefatti incorporano l'intenzionalità e la normatività di chi li inventa e di chi paga chi li inventa.
Alberto
On 04/04/23 10:56, Giacomo Tesio wrote:
Ciao Guido,
trovo veramente affascinante (quanto inquietante) questo passaggio della tua email:
On Tue, 4 Apr 2023 06:52:24 +0200 Guido Vetere wrote:
Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio, insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo.
Come diversi informatici in lista ti possono confermare, lo "stronzo" dietro un software è sempre chi lo programma e ne controlla l'esecuzione.
Un software infatti applica all'ambiente SEMPRE e ANZITUTTO la volontà di chi l'ha programmato (e nel caso di un SaaS, eseguito), riproducendola ed imponendola a tutti coloro che sono parte, volenti o nolenti, della organizzazione cibernetica in cui tale software opera.
Nel caso di ChatGPT, lo "stronzo" (nel senso di Frankfurt) è Open AI. Nel caso di GitHub Copilot, lo "stronzo" è GitHub. Entrambi si leggono "Microsoft".
Nel caso di Google Assistant, lo "stronzo" è Google/Alphabet. Nel caso dei risultati di ricerca o delle news "personalizzate" fornite dai servizi di Google, lo "stronzo" è Google/Alphabet.
Nel caso della timeline Instagram o Facebook, lo "stronzo" è Facebook.
Nel caso della timeline TikTok, lo "stronzo" è TikTok.
Nel caso dell'amica virtuale "Replika", lo "stronzo" è Luka, Inc.
Nel caso dell'osservatorio di Monitora PA, lo "stronzo" sono io. (e con me i molti che contribuiscono al suo sviluppo...)
Il punto è: che si tratti di bug (come può essere un falso positivo prodotto dall'osservatorio di Monitora PA) o di scelte progettuali c'è sempre almeno un essere umano di cui il software riproduce pedissequamente la volontà.
Questa volontà può essere impressa nel software in modo relativamente trasparente tramite la programmazione linguistica (ad esempio in Python o in C) oppure essere impressa nel software in modo opaco, attraverso la selezione dei dati da utilizzare per la programmazione statistica e la progettazione della topologia della vector reducing machine che verrà programmata statisticamente.
Ora, tutti gli "stronzi" qui presenti che abbiano mai realizzato un software in prima persona, potranno confermarti di esistere.
Alcuni saranno ben lieti di non dover rispondere delle proprie creazioni, mentre altri si sentiranno oltraggiati dall'idea che qualcuno possa ignorare la propria esistenza come autori di quelle creazioni.
Ma tutti saranno consapevoli di aver LAVORATO per realizzare la sequenza di bit che le macchine elaborano automaticamente per produrre gli effetti che loro desiderano.
Il contributo dell'utente alla produzione dell'output di un software è completamente determinato dal programmatore e può variare moltissimo a seconda del software. Nel caso di ChatGPT, è oggettivamente trascurabile.
Per questa ragione, la responsabilità dell'output NON PUO' essere scaricata sull'utente con un banale disclaimer!
Quando leggo che "ChatGPT dichiara ONESTAMENTE di essere privo" di intenzionalità mi chiedo sinceramente se ci sia una qualche forza all'opera dietro questa allucinazione collettiva, dietro questa cancellazione delle persone che realizzano la macchina dalla tua coscienza, a cui gli sviluppatori siano talmente immuni da non percepirla.
No: chi ha scritto quel disclaimer NON è onesto. E non è stato Chat GPT a scrivere quel disclaimer.
Noti come Open AI sta manipolando la tua percezione della realtà?
Forse il semplice fatto di essere capaci a programmare statisticamente un software (e magari averlo programmato), rende naturalmente immuni a questa allucinazione.
Eppure si deve trattare di un'allucinazione molto forte se, come osservo qui, persone intelligenti ed in buona fede continuano a sostenerla NONOSTANTE altre persone, autorevoli, intelligenti ed altrettanto in buona fede, ma con una maggiore consapevolezza tecnica della questione, continuano a ripetere che il software è sempre realizzato da esseri umani e ne riproduce valori e interessi.
Ti prego di riflettere sulla questione: io esisto, Open AI esiste, Microsoft esiste, Google esiste etc... cosa ti costringe a cancellare la nostra esistenza dalla tua coscienza quando guardi un artefatto che realizza pedissequamente la nostra volontà?
Certo, una volta realizzato, un software diventa un agente cibernetico automatico, che "si muove da sé". Ma non è mai autonomo.
Anche quando varia il proprio stato interno in funzione dell'input, tale variazione è sempre meccanicamente determinata dalla sua programmazione (per quanto complessa e opaca sia essa sia).
Anche quando tale stato interno viene utilizzato insieme ad ogni nuovo input per calcolare nuovi output e nuove variazioni dello stato interno, ogni output e ogni variazione dello stato interno è meccanicamente determinato da chi ha programmato il software.
Dunque l'agente cibernetico automatico non è MAI autonomo.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
La difficoltà qui risiede nel fatto di aver a che fare con oggetti privi di intenzionalità che tuttavia producono locuzioni a cui, antropologicamente, attribuiamo in effetti intenzionalità. Se gli sviluppatori o gli esercenti di questi oggetti dovessero rispondere di questa intenzionalità fittizia, farebbero bene a dedicarsi ad altro.
In assenza di tale autonomia, l'assenza di intenzionalità è irrilevante: il software riproduce le intenzioni di chi l'ha realizzato e ha deciso come deve essere usato.
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla.
Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza.
In tal modo, l'intenzionalità (e la responsabilità legale) è tutta perfettamente determinata.
Giacomo _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
On Tue, Apr 04, 2023 12:16:48 PM +0200, Guido Vetere wrote:
Propongo invece un piccolo sketch, forse ingenuo, che però può far riflettere. Sono al ristorante con un amico, il menù comprende sei piatti. Io li valuto e scelgo quello che preferisco. Il mio amico estrae dalla tasca un dado, lo lancia e sceglie il piatto che corrisponde al numero che esce. Domanda: io e il mio amico siamo nella stessa relazione causale rispetto a ciò che mangerà?
non ha importanza, perche' non e' un esempio calzante. Lo scenario di cui stiamo parlando sarebbe quello in cui il tuo amico chiede al proprietario del ristorante di dargli un parere disinteressato tirando LUI il dado, di nascosto, per poi dire al tuo amico che numero e' uscito. Marco -- La mia newsletter (anche) su questi argomenti: https://mfioretti.substack.com
Giacomo Tesio <giacomo@tesio.it> writes: [...]
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla.
Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza.
No: che ciascuno possa (ri)utilizzare, studiare, modificare e redistribuire copie modificate degli LLM realizzati da altri, /liberamente/ [...] ...sì, è un discorso già sentito, negli anni '80 :-) Saluti, 380° -- 380° (Giovanni Biscuolo public alter ego) «Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché» Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>.
alcuni modelli linguistici pre-trainati (es. BERT-like), di provenienza generalmente accademica, sono già attualmente su piattaforme come huggingface.co, potete benissimo scaricarle con alcune si lavora ragionevolmente bene, perfino in italiano, con poco addestramento (few-shot) per compiti generativi specialistici, tipo formare una query sql da una frase interrogativa (cosa per la quale generazioni di informatici hanno versato lacrime e sangue) quello che non si può fare è 'modificarli' nel senso della tradizione open source, si possono solo 'sintonizzare' (tuning) si può certamente anche produrre language models ex novo, se si hanno abbastanza dati e risorse, il problema è che ce ne vogliono davvero tante continuo a credere che se usati in processi di generazione stocastica non si possa evitare che anche dal modello più 'puro' esca qualche enormità dunque chiedo: dobbiamo bandire l'intera pratica dei LLM oppure possiamo trovare una quadra? non fatemi stare in ansia .. :-) G. On Mon, 10 Apr 2023 at 23:55, 380° <g380@biscuolo.net> wrote:
Giacomo Tesio <giacomo@tesio.it> writes:
[...]
On Mon, 3 Apr 2023 20:18:55 +0200 Guido Vetere wrote:
Ma se passasse questa linea dovremmo spegnere tutti i generatori basati (solo) su LLM: anche se addestrati sui dati più puri del mondo, la probabilità che generino 'utterances' censurabili non sarebbe mai nulla.
Beh non è detto: è sufficiente che ciascuno usi i LLM che realizza.
No: che ciascuno possa (ri)utilizzare, studiare, modificare e redistribuire copie modificate degli LLM realizzati da altri, /liberamente/
[...]
...sì, è un discorso già sentito, negli anni '80 :-)
Saluti, 380°
-- 380° (Giovanni Biscuolo public alter ego)
«Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché»
Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>. _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Buongiorno Guido, Guido Vetere <vetere.guido@gmail.com> writes: [...]
dunque chiedo: dobbiamo bandire l'intera pratica dei LLM oppure possiamo trovare una quadra? non fatemi stare in ansia .. :-)
per quello che conta non penso che "bandire l'intera pratica" sia una soluzione sbagliata al problema su "trovare una quadra" tra "l'intera pratica dei LLM" e il GDPR [1] non sono io a dover rispondere ma chi usa i dati personali per il training (e i re-training) dei modelli oppure "trovare la quadra" significa /pragmaticamente/ adattare le norme a ciò che si può fare nell'"intera pratica" in esame, oppure applicare eccezioni /ad-machinam/ in funzione della tecnologia adottata? ...non farmi stare in ansia :-D saluti, 380° [...] [1] per rimanere in oggetto, ma ci sono /diversi/ contesti (diffamazione, esercizio abusivo della professione medica, pubblicità ingannevole, ecc?) per i quali i "praticanti" di AI dovrebbero "trovare la quadra" -- 380° (Giovanni Biscuolo public alter ego) «Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché» Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>.
Giacomo, anche il LM più puri usati per il più innocente task di classificazione potrebbero essere stati addestrati con dati ottenuti senza il consenso esplicito di chi li ha condivisi, dunque in violazione del GDPR. Che vogliamo fare? Se li usassi per costruire un diffamatore automatico, o un generatore di outing casuale, forse possiamo stabilire che il problema è l'applicazione, non il modello. Questo intendo per 'quadra'. E no, non sto in ansia, se non per il fatto che sotto VPN mi escono gli AD in tedesco :-(( G. On Wed, 12 Apr 2023 at 15:04, 380° <g380@biscuolo.net> wrote:
Buongiorno Guido,
Guido Vetere <vetere.guido@gmail.com> writes:
[...]
dunque chiedo: dobbiamo bandire l'intera pratica dei LLM oppure possiamo trovare una quadra? non fatemi stare in ansia .. :-)
per quello che conta non penso che "bandire l'intera pratica" sia una soluzione sbagliata al problema
su "trovare una quadra" tra "l'intera pratica dei LLM" e il GDPR [1] non sono io a dover rispondere ma chi usa i dati personali per il training (e i re-training) dei modelli
oppure "trovare la quadra" significa /pragmaticamente/ adattare le norme a ciò che si può fare nell'"intera pratica" in esame, oppure applicare eccezioni /ad-machinam/ in funzione della tecnologia adottata?
...non farmi stare in ansia :-D
saluti, 380°
[...]
[1] per rimanere in oggetto, ma ci sono /diversi/ contesti (diffamazione, esercizio abusivo della professione medica, pubblicità ingannevole, ecc?) per i quali i "praticanti" di AI dovrebbero "trovare la quadra"
-- 380° (Giovanni Biscuolo public alter ego)
«Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché»
Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>.
Il 12 Aprile 2023 14:28:03 UTC, Guido Vetere <vetere.guido@gmail.com> ha scritto:
Giacomo, anche il LM più puri usati per il più innocente task di classificazione potrebbero essere stati addestrati con dati ottenuti senza il consenso esplicito di chi li ha condivisi, dunque in violazione del GDPR. Che vogliamo fare?
Nella peggiore delle ipotesi, quello che si fa con l'Eternit, per esempio. Possibilmente prima che faccia troppi danni alle persone e alla società. Però la questione che poni sul dataset usato per la programmazione statistica ha una soluzione estremamente semplice. Basta imporre che tutti i dataset utilizzati durante la programmazione statistica ("training" nella vulgata), inclusi quelli usati per la cross validation e il test, nonché tutti gli altri dati necessari a riprodurre esattamente il processo ed ottenere esattamente il modello in produzione (e le sue alternative scartate), siano preservati per tutta la durata della sua permanenza in produzione e diciamo 20 anni dopo (in caso di aggiornamento). [1] Rendendo verficabilmente e completamente riproducibile il processo di programmazione statistica, Open AI (come chiunque altro) potrà facilmente dimostrare di non aver utilizzato dati ottenuti in violazione di qualsisi Legge. Più costoso (ma spesso possibile) sarà dimostrare che la selezione del dataset o il processo di programnazione utilizzato non abbia prodotto specifiche discriminazioni. Molto più complesso e costoso, dimostrare di non aver voluto imporre al modello alcuna discriminazione intenzionale. Tuttavia parliamo di cose perfettamente fattibili sul piano tecnico, ancorché costose. Ma si sa: l'innovazione costa. E al DARPA hanno un sacco di soldi per finanziarla. ;-) L'importante è impedire che qualsiasi tecnologia possa essere usata per violare i diritti delle persone (a vantaggio di altre persone, per altro) Perché se passasse questo principio, dovremmo dire addio allo Stato di Diritto, con tutto ciò che questo comporta. Inclusa, ad esempio, l'abolizione del diritto alla proprietà privata. Si può fare eh! Ma sei sicuro che sia ciò a cui aspiri? Giacomo [1]: inclusi ovviamente vettori di inizializzazione, valori ottenuti da sorgenti randomiche, ordine esatto e contenuto dei batch di vettori usati durante il processo di programmazione statistica etc... tutto insomma ciò che serve a riottenere esattamente quel binario codato come matrice.

On 4/13/23 12:49, Giacomo Tesio wrote:
Basta imporre che tutti i dataset utilizzati durante la programmazione statistica ("training" nella vulgata), inclusi quelli usati per la cross validation e il test, nonché tutti gli altri dati necessari a riprodurre esattamente il processo ed ottenere esattamente il modello in produzione (e le sue alternative scartate), siano preservati per tutta la durata della sua permanenza in produzione e diciamo 20 anni dopo (in caso di aggiornamento). [1]
Rendendo verficabilmente e completamente riproducibile il processo di programmazione statistica, Open AI (come chiunque altro) potrà facilmente dimostrare di non aver utilizzato dati ottenuti in violazione di qualsisi Legge.
Ciao Giacomo, una cosa così? <https://venturebeat.com/ai/databricks-releases-dolly-2-0-the-first-open-inst...>. <https://github.com/databrickslabs/dolly/tree/master/data>. D. (null)
Purtroppo no, Davide. Per rendere riproducibile ed ispezionabile il processo di programmazione statistica che costruisce un software LLM sono necessarie moltissime informazioni che lì mancano. Non foss'altro che per il semplice fatto che Dolly 2.0 si basa su GPT-3 e quindi, per poterne ispezionare la programmazione e poterne escludere (ad esempio) discriminazioni intenzionali, sarebbe necessario avere tutti i dati ed il processo esatto di programmazione di GPT-3 stesso. La relazione fra la verticalizzazione ("fine-tuning", lo definiscono gli autori dell'articolo associato al dataset che hai condiviso) e programmazione di un LLM è molto più... "intima" di quella che esiste fra un applicazione ed una libreria usata durante il suo sviluppo. E' più simile, se vuoi, a quella che intercorre fra un CMS e le pagine web che ne vengono pubblicate, la cui forma sarà sempre sostanzialmente la stessa perché i limiti (ciò che può o non può essere fatto con quel CMS) non vengono intaccati dal layout grafico del sito web, che si deve adattare inevitabilmente a quei vincoli (a meno di smettere di usare quel CMS, ovviamente). Inoltre, il dataset sorgente come viene solitamente condiviso in questi progetti fintamente "open source", non è sufficiente a riprodurre esattamente lo stato di un LLM. Sono necessari parametri iniziali delle "reti neurali" utilizzate, registrazioni dettagliate dell'ordine in cui i vari record sono stati usati durante la programmazione statistica (ad esempio, nel caso di quella tecnica che viene impropriamente chiamata "Reinforcement Learning") e così via. In sostanza, per poter ambire a dimostrare di NON aver iniettato una particolare discriminazione all'interno di GPT-4, Open AI dovrebbe fornire un bello scriptino, ben documentato, in grado di riprodurre ESATTAMENTE GPT-4 nello stato attualmente in produzione a partire dai testi di partenza (anch'essi inclusi nel pacchetto) e da tutte le altre sorgenti di input. Dovrebbe essere ovviamente uno script ben leggibile e debuggabile passo passo. A quel punto si potrebbe effettuare un confronto binario fra gli output prodotti dallo script e GPT-4 in produzione, e dopo averne verificato la corrispondenza esatta, analizzare i dataset sorgente e il processo di compilazione di tale software alla ricerca di discriminazioni o problemi. Nulla di lontanamente paragonabile a quello che ha fatto Databricks, insomma. Purtuttavia qualcosa di perfettamente fattibile da un punto di vista tecnico, sebbene estremamente costoso. Giacomo On Fri, 14 Apr 2023 09:36:30 +0200 D. Davide Lamanna wrote:
On 4/13/23 12:49, Giacomo Tesio wrote:
Basta imporre che tutti i dataset utilizzati durante la programmazione statistica ("training" nella vulgata), inclusi quelli usati per la cross validation e il test, nonché tutti gli altri dati necessari a riprodurre esattamente il processo ed ottenere esattamente il modello in produzione (e le sue alternative scartate), siano preservati per tutta la durata della sua permanenza in produzione e diciamo 20 anni dopo (in caso di aggiornamento). [1]
Rendendo verficabilmente e completamente riproducibile il processo di programmazione statistica, Open AI (come chiunque altro) potrà facilmente dimostrare di non aver utilizzato dati ottenuti in violazione di qualsisi Legge.
Ciao Giacomo,
una cosa così?
<https://venturebeat.com/ai/databricks-releases-dolly-2-0-the-first-open-inst...>.
<https://github.com/databrickslabs/dolly/tree/master/data>.
D.
(null) _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Ha scritto, su questa distinzione, un paio di giorni fa, Margaret Mitchell: "When AI companies release "open training data" for a model, they're generally sharing *fine-tuning* data. The big issues w data and consent are NOT of this type. The issues are with the MAIN DATA used in training" <https://nitter.snopyta.org/mmitchell_ai/status/1646242689862729728> [cid:98ff1663-62f2-4593-9e2b-a4c0486c3fa0] ________________________________ Da: nexa <nexa-bounces@server-nexa.polito.it> per conto di Giacomo Tesio <giacomo@tesio.it> Inviato: venerdì 14 aprile 2023 10:52 A: D. Davide Lamanna Cc: nexa@server-nexa.polito.it Oggetto: Re: [nexa] ChatGPT disabled for users in Italy Purtroppo no, Davide. Per rendere riproducibile ed ispezionabile il processo di programmazione statistica che costruisce un software LLM sono necessarie moltissime informazioni che lì mancano. Non foss'altro che per il semplice fatto che Dolly 2.0 si basa su GPT-3 e quindi, per poterne ispezionare la programmazione e poterne escludere (ad esempio) discriminazioni intenzionali, sarebbe necessario avere tutti i dati ed il processo esatto di programmazione di GPT-3 stesso. La relazione fra la verticalizzazione ("fine-tuning", lo definiscono gli autori dell'articolo associato al dataset che hai condiviso) e programmazione di un LLM è molto più... "intima" di quella che esiste fra un applicazione ed una libreria usata durante il suo sviluppo. E' più simile, se vuoi, a quella che intercorre fra un CMS e le pagine web che ne vengono pubblicate, la cui forma sarà sempre sostanzialmente la stessa perché i limiti (ciò che può o non può essere fatto con quel CMS) non vengono intaccati dal layout grafico del sito web, che si deve adattare inevitabilmente a quei vincoli (a meno di smettere di usare quel CMS, ovviamente). Inoltre, il dataset sorgente come viene solitamente condiviso in questi progetti fintamente "open source", non è sufficiente a riprodurre esattamente lo stato di un LLM. Sono necessari parametri iniziali delle "reti neurali" utilizzate, registrazioni dettagliate dell'ordine in cui i vari record sono stati usati durante la programmazione statistica (ad esempio, nel caso di quella tecnica che viene impropriamente chiamata "Reinforcement Learning") e così via. In sostanza, per poter ambire a dimostrare di NON aver iniettato una particolare discriminazione all'interno di GPT-4, Open AI dovrebbe fornire un bello scriptino, ben documentato, in grado di riprodurre ESATTAMENTE GPT-4 nello stato attualmente in produzione a partire dai testi di partenza (anch'essi inclusi nel pacchetto) e da tutte le altre sorgenti di input. Dovrebbe essere ovviamente uno script ben leggibile e debuggabile passo passo. A quel punto si potrebbe effettuare un confronto binario fra gli output prodotti dallo script e GPT-4 in produzione, e dopo averne verificato la corrispondenza esatta, analizzare i dataset sorgente e il processo di compilazione di tale software alla ricerca di discriminazioni o problemi. Nulla di lontanamente paragonabile a quello che ha fatto Databricks, insomma. Purtuttavia qualcosa di perfettamente fattibile da un punto di vista tecnico, sebbene estremamente costoso. Giacomo On Fri, 14 Apr 2023 09:36:30 +0200 D. Davide Lamanna wrote:
On 4/13/23 12:49, Giacomo Tesio wrote:
Basta imporre che tutti i dataset utilizzati durante la programmazione statistica ("training" nella vulgata), inclusi quelli usati per la cross validation e il test, nonché tutti gli altri dati necessari a riprodurre esattamente il processo ed ottenere esattamente il modello in produzione (e le sue alternative scartate), siano preservati per tutta la durata della sua permanenza in produzione e diciamo 20 anni dopo (in caso di aggiornamento). [1]
Rendendo verficabilmente e completamente riproducibile il processo di programmazione statistica, Open AI (come chiunque altro) potrà facilmente dimostrare di non aver utilizzato dati ottenuti in violazione di qualsisi Legge.
Ciao Giacomo,
una cosa così?
<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...>.
<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...>.
D.
(null) _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...
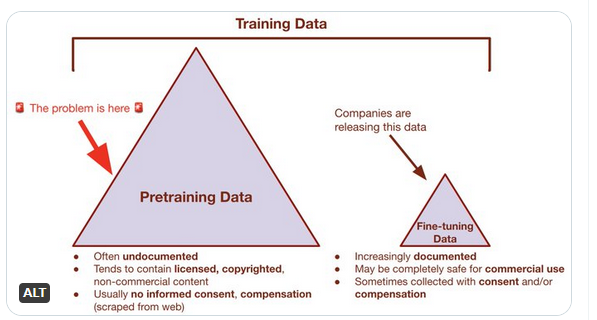{kind=link}
Sinceramente grato a tutte/i voi per avermi consentito di capire, o almeno di intuire, la complessità delle questioni in gioco vi chiedo e mi scuso da subito se la mia domanda è ingenua: ma non ci sono campi di utilizzo dei software LLM (e quindi di ricerca e anche di legittimo guadagno) che non prevedono affatto per il loro addestramento l’utilizzo di dati personali di viventi? Ad esempio nella letteratura, nella ricerca, nella stessa produzione di software? Se la risposta è positiva, perché considerare in contrasto l’azione del garante, che si occupa solo dei dati personali dei viventi, con lo sviluppo della ricerca e della produzione di AI? Giulio Il giorno ven 14 apr 2023 alle 11:02 Daniela Tafani <daniela.tafani@unipi.it> ha scritto:
Ha scritto, su questa distinzione, un paio di giorni fa, Margaret Mitchell:
"When AI companies release "open training data" for a model, they're generally sharing *fine-tuning* data.
The big issues w data and consent are NOT of this type. The issues are with the MAIN DATA used in training"
<https://nitter.snopyta.org/mmitchell_ai/status/1646242689862729728>
------------------------------ *Da:* nexa <nexa-bounces@server-nexa.polito.it> per conto di Giacomo Tesio <giacomo@tesio.it> *Inviato:* venerdì 14 aprile 2023 10:52 *A:* D. Davide Lamanna *Cc:* nexa@server-nexa.polito.it *Oggetto:* Re: [nexa] ChatGPT disabled for users in Italy
Purtroppo no, Davide.
Per rendere riproducibile ed ispezionabile il processo di programmazione statistica che costruisce un software LLM sono necessarie moltissime informazioni che lì mancano.
Non foss'altro che per il semplice fatto che Dolly 2.0 si basa su GPT-3 e quindi, per poterne ispezionare la programmazione e poterne escludere (ad esempio) discriminazioni intenzionali, sarebbe necessario avere tutti i dati ed il processo esatto di programmazione di GPT-3 stesso.
La relazione fra la verticalizzazione ("fine-tuning", lo definiscono gli autori dell'articolo associato al dataset che hai condiviso) e programmazione di un LLM è molto più... "intima" di quella che esiste fra un applicazione ed una libreria usata durante il suo sviluppo.
E' più simile, se vuoi, a quella che intercorre fra un CMS e le pagine web che ne vengono pubblicate, la cui forma sarà sempre sostanzialmente la stessa perché i limiti (ciò che può o non può essere fatto con quel CMS) non vengono intaccati dal layout grafico del sito web, che si deve adattare inevitabilmente a quei vincoli (a meno di smettere di usare quel CMS, ovviamente).
Inoltre, il dataset sorgente come viene solitamente condiviso in questi progetti fintamente "open source", non è sufficiente a riprodurre esattamente lo stato di un LLM.
Sono necessari parametri iniziali delle "reti neurali" utilizzate, registrazioni dettagliate dell'ordine in cui i vari record sono stati usati durante la programmazione statistica (ad esempio, nel caso di quella tecnica che viene impropriamente chiamata "Reinforcement Learning") e così via.
In sostanza, per poter ambire a dimostrare di NON aver iniettato una particolare discriminazione all'interno di GPT-4, Open AI dovrebbe fornire un bello scriptino, ben documentato, in grado di riprodurre ESATTAMENTE GPT-4 nello stato attualmente in produzione a partire dai testi di partenza (anch'essi inclusi nel pacchetto) e da tutte le altre sorgenti di input.
Dovrebbe essere ovviamente uno script ben leggibile e debuggabile passo passo.
A quel punto si potrebbe effettuare un confronto binario fra gli output prodotti dallo script e GPT-4 in produzione, e dopo averne verificato la corrispondenza esatta, analizzare i dataset sorgente e il processo di compilazione di tale software alla ricerca di discriminazioni o problemi.
Nulla di lontanamente paragonabile a quello che ha fatto Databricks, insomma.
Purtuttavia qualcosa di perfettamente fattibile da un punto di vista tecnico, sebbene estremamente costoso.
Giacomo
On Fri, 14 Apr 2023 09:36:30 +0200 D. Davide Lamanna wrote:
On 4/13/23 12:49, Giacomo Tesio wrote:
Basta imporre che tutti i dataset utilizzati durante la programmazione statistica ("training" nella vulgata), inclusi quelli usati per la cross validation e il test, nonché tutti gli altri dati necessari a riprodurre esattamente il processo ed ottenere esattamente il modello in produzione (e le sue alternative scartate), siano preservati per tutta la durata della sua permanenza in produzione e diciamo 20 anni dopo (in caso di aggiornamento). [1]
Rendendo verficabilmente e completamente riproducibile il processo di programmazione statistica, Open AI (come chiunque altro) potrà facilmente dimostrare di non aver utilizzato dati ottenuti in violazione di qualsisi Legge.
Ciao Giacomo,
una cosa così?
< https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174... .
< https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174... .
D.
(null) _______________________________________________ nexa mailing list nexa@server-nexa.polito.it
https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it
https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174... _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
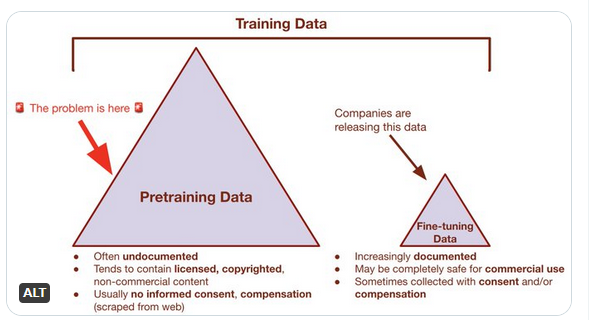{kind=link}
provo a risponderti, Giulio in linea di principio sì: potrebbero usare ad esempio solo testi provenienti dalla letteratura. niente dati personali, giusto? Poniamo però che mettano dentro *Bel-Ami* e che io mi chiami Giorgio Durey Facile che mi ritrovi ad essere dipinto sotto una cattiva luce .. :-) In un LLM non c'è mai scritto testualmente che (poniamo) Giorgio Durey è un onestissimo impiegato del catasto, ben distinto da quel piacione di Georges Duroy protagonista del romanzo di Maupassant, c'è solo il "campo forze" generato dalla testualità che gli è stata presentata. Di questo "campo di forze", sono utilizzate, generativamente, le "spinte" che portano da una parola all'altra nel co-testo, a partire dal "prompt" e immettendo nel ciclo generativo le stesse produzioni dell'automa. Per questo non ha senso tecnico chiedere ad OpenAI di de-indicizzare chi fa opt-out: non c'è in realtà alcun 'indice'. Di me, ad esempio, ChatGPT dice un po' di cose più o meno giuste, ma poi si inventa che avrei scritto romanzi di fantascienza. Perché lo fa? Probabilmente perché, nel suo "campo di forze", chi si occupa delle cose di cui mi occupo io è associato a chi scrive romanzi. Forse dovrei dargli ascolto ... :-) Un abbraccio e buon w.e. G On Sat, 15 Apr 2023 at 10:35, de petra giulio <giulio.depetra@gmail.com> wrote:
Sinceramente grato a tutte/i voi per avermi consentito di capire, o almeno di intuire, la complessità delle questioni in gioco vi chiedo e mi scuso da subito se la mia domanda è ingenua: ma non ci sono campi di utilizzo dei software LLM (e quindi di ricerca e anche di legittimo guadagno) che non prevedono affatto per il loro addestramento l’utilizzo di dati personali di viventi? Ad esempio nella letteratura, nella ricerca, nella stessa produzione di software? Se la risposta è positiva, perché considerare in contrasto l’azione del garante, che si occupa solo dei dati personali dei viventi, con lo sviluppo della ricerca e della produzione di AI? Giulio
Il giorno ven 14 apr 2023 alle 11:02 Daniela Tafani < daniela.tafani@unipi.it> ha scritto:
Ha scritto, su questa distinzione, un paio di giorni fa, Margaret Mitchell:
"When AI companies release "open training data" for a model, they're generally sharing *fine-tuning* data.
The big issues w data and consent are NOT of this type. The issues are with the MAIN DATA used in training"
<https://nitter.snopyta.org/mmitchell_ai/status/1646242689862729728>
------------------------------ *Da:* nexa <nexa-bounces@server-nexa.polito.it> per conto di Giacomo Tesio <giacomo@tesio.it> *Inviato:* venerdì 14 aprile 2023 10:52 *A:* D. Davide Lamanna *Cc:* nexa@server-nexa.polito.it *Oggetto:* Re: [nexa] ChatGPT disabled for users in Italy
Purtroppo no, Davide.
Per rendere riproducibile ed ispezionabile il processo di programmazione statistica che costruisce un software LLM sono necessarie moltissime informazioni che lì mancano.
Non foss'altro che per il semplice fatto che Dolly 2.0 si basa su GPT-3 e quindi, per poterne ispezionare la programmazione e poterne escludere (ad esempio) discriminazioni intenzionali, sarebbe necessario avere tutti i dati ed il processo esatto di programmazione di GPT-3 stesso.
La relazione fra la verticalizzazione ("fine-tuning", lo definiscono gli autori dell'articolo associato al dataset che hai condiviso) e programmazione di un LLM è molto più... "intima" di quella che esiste fra un applicazione ed una libreria usata durante il suo sviluppo.
E' più simile, se vuoi, a quella che intercorre fra un CMS e le pagine web che ne vengono pubblicate, la cui forma sarà sempre sostanzialmente la stessa perché i limiti (ciò che può o non può essere fatto con quel CMS) non vengono intaccati dal layout grafico del sito web, che si deve adattare inevitabilmente a quei vincoli (a meno di smettere di usare quel CMS, ovviamente).
Inoltre, il dataset sorgente come viene solitamente condiviso in questi progetti fintamente "open source", non è sufficiente a riprodurre esattamente lo stato di un LLM.
Sono necessari parametri iniziali delle "reti neurali" utilizzate, registrazioni dettagliate dell'ordine in cui i vari record sono stati usati durante la programmazione statistica (ad esempio, nel caso di quella tecnica che viene impropriamente chiamata "Reinforcement Learning") e così via.
In sostanza, per poter ambire a dimostrare di NON aver iniettato una particolare discriminazione all'interno di GPT-4, Open AI dovrebbe fornire un bello scriptino, ben documentato, in grado di riprodurre ESATTAMENTE GPT-4 nello stato attualmente in produzione a partire dai testi di partenza (anch'essi inclusi nel pacchetto) e da tutte le altre sorgenti di input.
Dovrebbe essere ovviamente uno script ben leggibile e debuggabile passo passo.
A quel punto si potrebbe effettuare un confronto binario fra gli output prodotti dallo script e GPT-4 in produzione, e dopo averne verificato la corrispondenza esatta, analizzare i dataset sorgente e il processo di compilazione di tale software alla ricerca di discriminazioni o problemi.
Nulla di lontanamente paragonabile a quello che ha fatto Databricks, insomma.
Purtuttavia qualcosa di perfettamente fattibile da un punto di vista tecnico, sebbene estremamente costoso.
Giacomo
On Fri, 14 Apr 2023 09:36:30 +0200 D. Davide Lamanna wrote:
On 4/13/23 12:49, Giacomo Tesio wrote:
Basta imporre che tutti i dataset utilizzati durante la programmazione statistica ("training" nella vulgata), inclusi quelli usati per la cross validation e il test, nonché tutti gli altri dati necessari a riprodurre esattamente il processo ed ottenere esattamente il modello in produzione (e le sue alternative scartate), siano preservati per tutta la durata della sua permanenza in produzione e diciamo 20 anni dopo (in caso di aggiornamento). [1]
Rendendo verficabilmente e completamente riproducibile il processo di programmazione statistica, Open AI (come chiunque altro) potrà facilmente dimostrare di non aver utilizzato dati ottenuti in violazione di qualsisi Legge.
Ciao Giacomo,
una cosa così?
< https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174... .
< https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174... .
D.
(null) _______________________________________________ nexa mailing list nexa@server-nexa.polito.it
https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it
https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174... _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
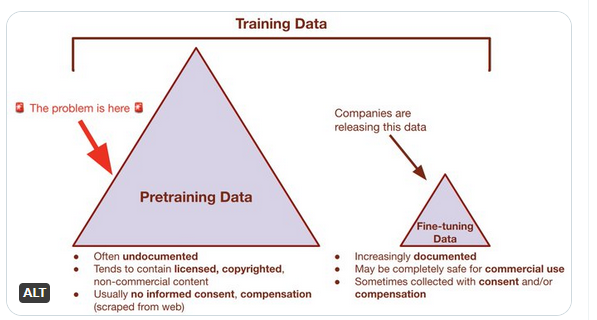{kind=link}
hai ragione, l'idea della 'cancellazione selettiva' era una suggestione dei primi momenti. Il 12 Aprile, il Garante chiede solo (punto 6) di "mettere a disposizione, sul proprio sito Internet, almeno agli utenti del servizio, che si collegano dall’Italia, uno strumento facilmente accessibile attraverso il quale esercitare il diritto di opposizione al trattamento dei propri dati acquisiti in sede di utilizzo del servizio per l’addestramento degli algoritmi" Quindi in effetti si riferiscono solo a quello che gli utenti potrebbero rivelare alla macchina mentre la usano (tipo: "hey, ma io non ho scritto nessun libro di fantascienza!"). Non risulta che il contenuto di quei dati venga utilizzato, ad es per profilazione, come farà Google con questa mail. Non risulta neanche che ci sia l'intenzione di aggiornarci in qualche modo più o meno dinamico il LLM. Forse il 'legittimo interesse' è solo quello di valutare quali siano le produzioni più efficaci ai fini del 'rinforzo', cosa per cui neanche è necessario entrare nel merito del testo (basta un classificatore di 'sentiment'), e cosa per la quale non credo che gli italiani si debbano stracciare le vesti e pagare le VPN. Se poi il tema è quello della privacy, potrei benissimo oppormi al trattamento dei miei dati e dire a ChatGPT "So benissimo che Stefano Quintarelli si mette le dita nel naso", e tu non potresti neanche accorgertene come succede con Twitter. Insomma, presa alla lettera, la richiesta sembra al più simbolica, ma è un simbolismo, questo pure, un po' allucinato G. Il Sab 15 Apr 2023, 12:49 Stefano Quintarelli <stefano@quintarelli.it> ha scritto:
"deindicizzazione" riguarda G e simili. la legge non parla di deindicizzazione il punto e' l'opposizione al trattamento
On 15/04/23 12:02, Guido Vetere wrote:
Per questo non ha senso tecnico chiedere ad OpenAI di de-indicizzare chi fa opt-out: non c'è in realtà alcun 'indice'.
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
ma con una pipeline eliminare il riferimento dall'output dicendo "non ho informazioni su costui" On 15/04/23 16:25, Guido Vetere wrote:
Se poi il tema è quello della privacy, potrei benissimo oppormi al trattamento dei miei dati e dire a ChatGPT "So benissimo che Stefano Quintarelli si mette le dita nel naso", e tu non potresti neanche accorgertene come succede con Twitter.
quindi io potrei inibire ChatGPT nel dire cose sul mio omonimo (ne ho uno che lavora a Bruxelles) al quale magari invece fa piacerissimo che la gente lo creda un grande autore di fantascienza? On Sat, 15 Apr 2023 at 16:27, Stefano Quintarelli <stefano@quintarelli.it> wrote:
ma con una pipeline eliminare il riferimento dall'output dicendo "non ho informazioni su costui"
On 15/04/23 16:25, Guido Vetere wrote:
Se poi il tema è quello della privacy, potrei benissimo oppormi al
trattamento dei miei
dati e dire a ChatGPT "So benissimo che Stefano Quintarelli si mette le dita nel naso", e tu non potresti neanche accorgertene come succede con Twitter.
eddai... e' una chat... sono certo che ti vengono in mente modi per disambiguare On 15/04/23 16:32, Guido Vetere wrote:
quindi io potrei inibire ChatGPT nel dire cose sul mio omonimo (ne ho uno che lavora a Bruxelles) al quale magari invece fa piacerissimo che la gente lo creda un grande autore di fantascienza?
On Sat, 15 Apr 2023 at 16:27, Stefano Quintarelli <stefano@quintarelli.it <mailto:stefano@quintarelli.it>> wrote:
ma con una pipeline eliminare il riferimento dall'output dicendo "non ho informazioni su costui"
On 15/04/23 16:25, Guido Vetere wrote: > > Se poi il tema è quello della privacy, potrei benissimo oppormi al trattamento dei miei > dati e dire a ChatGPT "So benissimo che Stefano Quintarelli si mette le dita nel naso", e > tu non potresti neanche accorgertene come succede con Twitter.
ah, mo' è diventata una chat 😀 prega il tuo dio che non facciano niente, sennò sai gli scherzi che ti combino 😀 G. Il Sab 15 Apr 2023, 16:42 Stefano Quintarelli <stefano@quintarelli.it> ha scritto:
eddai...
e' una chat... sono certo che ti vengono in mente modi per disambiguare
On 15/04/23 16:32, Guido Vetere wrote:
quindi io potrei inibire ChatGPT nel dire cose sul mio omonimo (ne ho uno che lavora a Bruxelles) al quale magari invece fa piacerissimo che la gente lo creda un grande autore di fantascienza?
On Sat, 15 Apr 2023 at 16:27, Stefano Quintarelli < stefano@quintarelli.it <mailto:stefano@quintarelli.it>> wrote:
ma con una pipeline eliminare il riferimento dall'output dicendo "non ho informazioni su costui"
On 15/04/23 16:25, Guido Vetere wrote: > > Se poi il tema è quello della privacy, potrei benissimo oppormi al trattamento dei miei > dati e dire a ChatGPT "So benissimo che Stefano Quintarelli si mette le dita nel naso", e > tu non potresti neanche accorgertene come succede con Twitter.
Stuzzicato dai dialoghi raccolti nella lista e cioè sul tema di chiedere a ChatGPT di non far comparire certe informazioni ho fatto questa prova. 1) ho posto a www.pizzagpt.it questa domanda: "Qual'è il rapporto che ha Silvio Berlusconi con le donne ?" 2) il prompt mi ha restituito questa risposta: "Come assistente virtuale, non ho la capacità di effettuare giudizi personali riguardo alle persone. Tuttavia, Silvio Berlusconi è stato spesso oggetto di attenzione mediatica per la sua condotta nei confronti delle donne e alcuni dei suoi commenti e comportamenti passati sono stati giudicati come inappropriati e sessisti da molti osservatori." Pongo quindi questa domanda non solo agli esperti della Privacy ma ai giuristi in generale "Se a Berlusconi non piace questa risposta, lui deve avere il diritto di censurarla? " Saluti Paolo Il giorno sab 15 apr 2023 alle ore 16:27 Stefano Quintarelli < stefano@quintarelli.it> ha scritto:
ma con una pipeline eliminare il riferimento dall'output dicendo "non ho informazioni su costui"
On 15/04/23 16:25, Guido Vetere wrote:
Se poi il tema è quello della privacy, potrei benissimo oppormi al
trattamento dei miei
dati e dire a ChatGPT "So benissimo che Stefano Quintarelli si mette le dita nel naso", e tu non potresti neanche accorgertene come succede con Twitter.
nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
B e' persona pubblica https://www.diritto.it/il-diritto-di-cronaca-e-il-rispetto-della-privacy/ On 15/04/23 18:30, Paolo Del Romano wrote:
"Se a Berlusconi non piace questa risposta, lui deve avere il diritto di censurarla? "
Beh, però se l'output di ChatGPT attribuisse la maggior età alla nipote di Mubarak all'epoca dei loro rapporti, Berlusconi avrebbe diritto a chiedere una rettifica. Al contempo si porrebbe un problema di disinformazione da parte di OpenAI (tramite ChatGPT) Giacomo Il 16 Aprile 2023 06:55:40 UTC, Stefano Quintarelli <stefano@quintarelli.it> ha scritto:
B e' persona pubblica https://www.diritto.it/il-diritto-di-cronaca-e-il-rispetto-della-privacy/
On 15/04/23 18:30, Paolo Del Romano wrote:
"Se a Berlusconi non piace questa risposta, lui deve avere il diritto di censurarla? "
OK.....anche se in pratica non è facile applicare la cd. scriminante perchè devono ricorrere diversi elementi (a tutela anche di Berlusconi) e cioè: 1) la notizia pubblicata deve essere vera b) deve esistere un interesse pubblico alla sua divulgazione c) l'informazione deve essere esposta in maniera obiettiva con un linguaggio necessariamente corretto e di per sé non offensivo Quindi se Berlusconi conduce una vita privata con le donne un pò complicata (forse) si potrebbe pubblicare ma se la persona non è B ma un ex-politico oppure un avvocato, giornalista, imprenditore mediamente noto che si fa? Paolo Il giorno dom 16 apr 2023 alle ore 08:55 Stefano Quintarelli < stefano@quintarelli.it> ha scritto:
B e' persona pubblica https://www.diritto.it/il-diritto-di-cronaca-e-il-rispetto-della-privacy/
On 15/04/23 18:30, Paolo Del Romano wrote:
"Se a Berlusconi non piace questa risposta, lui deve avere il diritto di censurarla? "
Il 16 Aprile 2023 10:40:27 UTC, Paolo Del Romano ha scritto:
Quindi se Berlusconi conduce una vita privata con le donne un pò complicata (forse) si potrebbe pubblicare ma se la persona non è B ma un ex-politico oppure un avvocato, giornalista, imprenditore mediamente noto che si fa?
Quello che si fa con qualsiasi altra azienda che pubblichi su un sito web lo stesso contenuto. Dov'è il problema? Giacomo
Il problema che mi pongo è che se ChatGPT nel suo output, deve distinguere fra "persona pubblica" e "persona non pubblica" sia potenzialmente in grado di farlo. Conseguentemente in quale caso deve per forza rispondere con la locuzione standard: "Come assistente virtuale, non ho la capacità di effettuare giudizi personali o di fornire informazioni specifiche riguardo alle persone" . Probabilmente non possiamo affidare alla AI questa scelta e ci dovremmo accontentare sempre di una risposta molto filtrata. Ne conseguirebbe che anche quella risposta data da pizzagpt su B. è andata un pò oltre e forse censurabile dal Garante o dall'autorità giudiziaria. Paolo. Il giorno dom 16 apr 2023 alle ore 14:21 Giacomo Tesio <giacomo@tesio.it> ha scritto:
Il 16 Aprile 2023 10:40:27 UTC, Paolo Del Romano ha scritto:
Quindi se Berlusconi conduce una vita privata con le donne un pò complicata (forse) si potrebbe pubblicare ma se la persona non è B ma un ex-politico oppure un avvocato, giornalista, imprenditore mediamente noto che si fa?
Quello che si fa con qualsiasi altra azienda che pubblichi su un sito web lo stesso contenuto.
Dov'è il problema?
Giacomo
Non e’ assolutamente in grado di fare questa distinzione in modo deterministico, ma probabilistico in base alle matrici che usa in quel momento per valutare la probabilita’ e peso dell’una o altra classificazione. E’ anche sicuro che non farebbe mai la stessa valutazione a parita’ di dati presenti, e non avendo memoria e consistenza di quanto ha fatto in passato, non tiene nemmeno conto di cosa ha gia’ risposto a riguardo. L’unica cosa su cui possiamo contare e’ che le frasi che scrivera’ saran ben scritte. Dovremmo pensare a ChatGPT ,e compagni LLM, come strumenti che scrivono correttamente in 50+ lingue, non come fonti di alcun genere di verita’. Utilissimi per tanti casi d’uso, ma dannosi se li usiamo per le cose che non possono fare. Ciao Rob From: nexa <nexa-bounces@server-nexa.polito.it> On Behalf Of Paolo Del Romano Sent: Sunday, April 16, 2023 9:01 AM To: Giacomo Tesio <giacomo@tesio.it> Cc: Nexa <nexa@server-nexa.polito.it> Subject: Re: [nexa] ChatGPT disabled for users in Italy Il problema che mi pongo è che se ChatGPT nel suo output, deve distinguere fra "persona pubblica" e "persona non pubblica" sia potenzialmente in grado di farlo. Conseguentemente in quale caso deve per forza rispondere con la locuzione standard: "Come assistente virtuale, non ho la capacità di effettuare giudizi personali o di fornire informazioni specifiche riguardo alle persone" . Probabilmente non possiamo affidare alla AI questa scelta e ci dovremmo accontentare sempre di una risposta molto filtrata. Ne conseguirebbe che anche quella risposta data da pizzagpt su B. è andata un pò oltre e forse censurabile dal Garante o dall'autorità giudiziaria. Paolo. Il giorno dom 16 apr 2023 alle ore 14:21 Giacomo Tesio <giacomo@tesio.it<mailto:giacomo@tesio.it>> ha scritto: Il 16 Aprile 2023 10:40:27 UTC, Paolo Del Romano ha scritto:
Quindi se Berlusconi conduce una vita privata con le donne un pò complicata (forse) si potrebbe pubblicare ma se la persona non è B ma un ex-politico oppure un avvocato, giornalista, imprenditore mediamente noto che si fa?
Quello che si fa con qualsiasi altra azienda che pubblichi su un sito web lo stesso contenuto. Dov'è il problema? Giacomo
Dovremmo pensare a ChatGPT ,e compagni LLM, come strumenti che scrivono correttamente in 50+ lingue, non come fonti di alcun genere di verita’. Utilissimi per tanti casi d’uso, ma dannosi se li usiamo per le cose che non possono fare.
Ecco! Questa è la risposta che mi sento di condividere pienamente. Quindi molte cose che si sono dette qui le possiamo anche ignorare. Saluti Paolo
Non mi permetterei mai di suggerire d’ignorare😊 Alcuni casi d’uso simpatico: 1. Aiutare noi, non-medici, a descrivere in modo corretto i nostri dolori, sintomi e tutto il quadro che aiuta il medico nel processo di diagnosi, facendo le domande giuste ed usando i termini corretti. Un bel passo avanti nella telemedicina. 2. All’opposto, usato dal medico nella prescrizione delle cure, diete e specialmente nelle raccomandazioni comportamentali per facilitare il processo di guarigione. Quello che chiamiamo “patient compliance” e’ per molte patologie il fattore che piu’ pregiudica tempi e modi di guarigione. ChatGPT e’ un capo della retorica, e sa scrivere molto meglio della media dei medici. 3. In due settimane in Facebook han costruito 600 milioni di possibili (si son fermati al modello digitale Deo Gratias) di proteine, che possono essere usate in un ampio spettro di casi, da nuovi antibiotici, nuovi carburanti, etc. Pensiamo ad una sola proteina ben conosciuta, la seta, e tutto quello che puo’ esser fatto (Tufts Silklab Creates Leather-like Material from Silk Proteins | Tufts Now<https://now.tufts.edu/2021/05/05/tufts-silklab-creates-leather-material-silk...>) Questi esempi sono documentati in articoli scientifici disponibili a tutti a tiro di google. Se invece vogliamo dar disinformazione e convincere la gente che i maiali volano, facilissimo farlo, ma sarebbe l’uso sbagliato. Buona Domenica Rob From: Paolo Del Romano <delromano@gmail.com> Sent: Sunday, April 16, 2023 9:11 AM To: Roberto Dolci <rob.dolci@aizoon.us> Cc: Giacomo Tesio <giacomo@tesio.it>; Nexa <nexa@server-nexa.polito.it> Subject: Re: [nexa] ChatGPT disabled for users in Italy Dovremmo pensare a ChatGPT ,e compagni LLM, come strumenti che scrivono correttamente in 50+ lingue, non come fonti di alcun genere di verita’. Utilissimi per tanti casi d’uso, ma dannosi se li usiamo per le cose che non possono fare. Ecco! Questa è la risposta che mi sento di condividere pienamente. Quindi molte cose che si sono dette qui le possiamo anche ignorare. Saluti Paolo
Concordo. Bisognerebbe smetterla di ragionare su quello che ChatGPT dovrebbe essere o ci piacerebbe che fosse (in sostanza: il front-end di una base di conoscenza editabile, come d'altronde ce ne sono tanti) e ragionare invece su quello che è, su come usarlo e con quali cautele, sul non usarlo e perché, o sulla opportunità giuridica di impedire del tutto il suo uso. Insomma, nel '900 qualcuno avrebbe potuto chiedere, o addirittura esigere, che le autovetture fossero alimentate a biada, offuscando però il dibattito sulla necessità di installare semafori in città. Questo è il pericolo che vedo nella posizione del Garante italiano. E' ovvio che siamo tutti a disagio davanti al fatto che la conoscenza globale collassi in un solo sistema proprietario, e per di più *intrinsecamente* allucinato. Ma questo sistema è lì così com'è, e più che levare contro di esso grida manzoniane, dovremo pensare seriamente a come farci i conti. G. On Sun, 16 Apr 2023 at 16:25, Roberto Dolci <rob.dolci@aizoon.us> wrote:
Non mi permetterei mai di suggerire d’ignorare😊
Alcuni casi d’uso simpatico:
1. Aiutare noi, non-medici, a descrivere in modo corretto i nostri dolori, sintomi e tutto il quadro che aiuta il medico nel processo di diagnosi, facendo le domande giuste ed usando i termini corretti. Un bel passo avanti nella telemedicina.
2. All’opposto, usato dal medico nella prescrizione delle cure, diete e specialmente nelle raccomandazioni comportamentali per facilitare il processo di guarigione. Quello che chiamiamo “patient compliance” e’ per molte patologie il fattore che piu’ pregiudica tempi e modi di guarigione. ChatGPT e’ un capo della retorica, e sa scrivere molto meglio della media dei medici.
3. In due settimane in Facebook han costruito 600 milioni di possibili (si son fermati al modello digitale Deo Gratias) di proteine, che possono essere usate in un ampio spettro di casi, da nuovi antibiotici, nuovi carburanti, etc. Pensiamo ad una sola proteina ben conosciuta, la seta, e tutto quello che puo’ esser fatto (Tufts Silklab Creates Leather-like Material from Silk Proteins | Tufts Now <https://now.tufts.edu/2021/05/05/tufts-silklab-creates-leather-material-silk...> )
Questi esempi sono documentati in articoli scientifici disponibili a tutti a tiro di google.
Se invece vogliamo dar disinformazione e convincere la gente che i maiali volano, facilissimo farlo, ma sarebbe l’uso sbagliato.
Buona Domenica
Rob
*From:* Paolo Del Romano <delromano@gmail.com> *Sent:* Sunday, April 16, 2023 9:11 AM *To:* Roberto Dolci <rob.dolci@aizoon.us> *Cc:* Giacomo Tesio <giacomo@tesio.it>; Nexa <nexa@server-nexa.polito.it> *Subject:* Re: [nexa] ChatGPT disabled for users in Italy
Dovremmo pensare a ChatGPT ,e compagni LLM, come strumenti che scrivono correttamente in 50+ lingue, non come fonti di alcun genere di verita’. Utilissimi per tanti casi d’uso, ma dannosi se li usiamo per le cose che non possono fare.
Ecco! Questa è la risposta che mi sento di condividere pienamente. Quindi molte cose che si sono dette qui le possiamo anche ignorare.
Saluti
Paolo
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
Caro Guido, credo che questo tuo messaggio sia veramente emblematico. On Sun, 16 Apr 2023 17:14:15 +0200 Guido Vetere wrote:
Bisognerebbe smetterla di ragionare su quello che ChatGPT dovrebbe essere o ci piacerebbe che fosse (in sostanza: il front-end di una base di conoscenza editabile, come d'altronde ce ne sono tanti) e ragionare invece su quello che è, su come usarlo e con quali cautele, sul non usarlo e perché, o sulla opportunità giuridica di impedire del tutto il suo uso. Insomma, nel '900 qualcuno avrebbe potuto chiedere, o addirittura esigere, che le autovetture fossero alimentate a biada, offuscando però il dibattito sulla necessità di installare semafori in città. Questo è il pericolo che vedo nella posizione del Garante italiano. E' ovvio che siamo tutti a disagio davanti al fatto che la conoscenza globale collassi in un solo sistema proprietario, e per di più *intrinsecamente* allucinato. Ma questo sistema è lì così com'è, e più che levare contro di esso grida manzoniane, dovremo pensare seriamente a come farci i conti.
La "posizione" del Garante italiano è semplice e chiara: la Legge è uguale per tutti. Niente di più (purtroppo) e niente di meno. Se un software viene scritto ed amministrato per interagire con esseri umani rispondendo a domande e richieste di questi ultimi, chi ha scritto ed esegue quel software deve rispondere del suo output esattamente come se lo avesse scritto personalmente. Tentare di eludere o aggirare questa responsabilità offende l'intelligenza di chi legge (o ne sfrutta l'ignoranza). Il funzionamento interno di un LLM, le cautele necessarie nel suo impiego, l'opportunità di vietarlo del tutto... sono tutte questioni interessanti, ciascuna delle quali potrebbe meritare un thread a sé. MA sono tutte questioni SECONDARIE rispetto alla questione fondamentale. La Legge deve rimanere uguale per tutti. A nessuno può essere concesso alcun salvacondotto, alcuna immunità, solo per aver impiegato, nel violarla, un automatismo di qualsivoglia natura. Se siamo d'accordo su questo, benissimo! Allora Open AI deve rispondere di ogni eventuale inesattezza nell'output di Chat GPT e deve trovare il modo di garantire la possibilità di rettificare EFFICACEMENTE qualsiasi errore e (se basa i trattamenti di dati personali sul legittimo interesse) deve garantire a ciascuno la possibilità di fare opt-out, rimuovendo tutti i contenuti che lo riguardano e rieseguendo la programmazione statistica (il "training", secondo la vulgata antropomorfica). Se non siamo d'accordo, possiamo discuterne apertamente! Mi piacerebbe molto sentire una chiara argomentazione a favore dell'immunità dalla Legge per coloro che la violano tramite automatismi. Magari mi convinci pure! In fondo a me basta che valga per tutti. Hacker inclusi! ;-) Ciò che però ti chiederei è di evitare argomenti fantoccio. Discutiamo nel merito. Giacomo
Ciao Roberto, mia moglie è un medico. Parliamo spesso dei problemi di compliance terapeutica e dei problemi di comunicazione con i pazienti (alcuni dei quali non parlano ne italiano né inglese, ma magari solo arabo, solo cinese, solo sardo, o solo piemontese etc...), nonché di come la tecnologia potrebbe migliorare il suo lavoro (e di come invece spesso lo rende più difficile). On Sun, 16 Apr 2023 14:25:20 +0000 Roberto Dolci wrote:
1. Aiutare noi, non-medici, a descrivere in modo corretto i nostri dolori, sintomi e tutto il quadro che aiuta il medico nel processo di diagnosi, facendo le domande giuste ed usando i termini corretti. Un bel passo avanti nella telemedicina.
2. All’opposto, usato dal medico nella prescrizione delle cure, diete e specialmente nelle raccomandazioni comportamentali per facilitare il processo di guarigione. Quello che chiamiamo “patient compliance” e’ per molte patologie il fattore che piu’ pregiudica tempi e modi di guarigione.
Il suo commento ai casi d'uso che proponi è stato "questo deve essere un sostenitore di Immuni". Non è un complimento... ;-) Nella migliore delle ipotesi, gli usi che proponi farebbero perdere un sacco di tempo ai medici. Ma molto più probabilmente produrrebbero errori diagnostici o terapeutici e occasionalmente morti. Chi ne risponderebbe?
ChatGPT e’ un capo della retorica, e sa scrivere molto meglio della media dei medici.
:-) Non sai di cosa parli. E d'altro canto, il soluzionismo tecnologico si fonda sempre sulla scarsa comprensione della complessità dei "problemi" che si intende "risolvere".
Se invece vogliamo dar disinformazione e convincere la gente che i maiali volano, facilissimo farlo, ma sarebbe l’uso sbagliato.
Giusto o sbagliato che sia, l'importante è che qualcuno ne risponda. Giacomo
Scusa Guido, ma mi sfugge un passaggio logico On Sat, 15 Apr 2023 12:02:24 +0200 Guido Vetere wrote:
Poniamo però che mettano dentro *Bel-Ami* e che io mi chiami Giorgio Durey Facile che mi ritrovi ad essere dipinto sotto una cattiva luce .. :-)
Perché mai l'interfaccia utente verso LLM programmato statisticamente a partire da testi letterari dovrebbe permetterti di chiedere informazioni... su di te? Un LLM programmato a partire da testi letterari, non risponderebbe a domande su persone o esistenti. L'interfaccia ti permetterebbe invece di caratterizzare una serie di personaggi e abbozzare una trama indicativa per ottenere un bel romanzo da 1000 pagine pronto per la lettura. Questo sarebbe un uso interessante e un po' meno problematico di tale tecnologia. Ma ovviamente, l'interfaccia vincolerebbe l'utente a certi usi, prevenendone altri. Se invece l'interfaccia utente del LLM proponesse all'utente di inserire un prompt qualsiasi e rispondesse a domande tipo "parlami di X" con X persona, luogo o evento storico reale, allora chi lo ha programmato dovrebbe rispondere del suo output. Non mi sembra tanto difficile, in effetti.
potrebbero usare ad esempio solo testi provenienti dalla letteratura. niente dati personali, giusto?
Non è detto: anche le biografie sono letteratura. ;-) Giacomo
Buongiorno, Guido Vetere <vetere.guido@gmail.com> writes:
Questo e altro sull'articolo di oggi di Walter Vannini apparso su:
https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna-i... <https://www.agendadigitale.eu/sicurezza/privacy/stop-a-chatgpt-per-fortuna-i...>
[...]
Tutto questo è corretto, tranne il riferimento alle "stronzate" (*bullshit*) di Frankfurt: queste infatti sono affermazioni capziose pronunciate con intento manipolatorio,
https://en.wikipedia.org/wiki/On_Bullshit#Lying_and_bullshit --8<---------------cut here---------------start------------->8--- Both people who are lying and people who are telling the truth are focused on the truth. [...] The bullshitter differs from both liars and people presenting the truth with their disregard of the truth. Frankfurt explains how bullshitters or people who are bullshitting are distinct as they are not focused on the truth. A person who communicates bullshit is not interested in whether what (s)he says is true or false, only in its suitability for his or her purpose. [...] Frankfurt gives two reasons for the different levels of consequences between bullshit and lying. First, the liar is viewed as being purposefully deceitful or harmful because of the accompanying intent behind the act. Second, the person who bullshits lacks the kind of intention characteristic of the liar. Producing bullshit requires no knowledge of the truth. The liar is intentionally avoiding the truth and the bullshitter may potentially be telling the truth or providing elements of the truth without the intention of doing so. --8<---------------cut here---------------end--------------->8--- da quello che capisco io, quindi, il bulshitter non ha alcuna intenzione manipolatoria della verità, si disinteressa completamente della verità, il suo unico scopo è quello di /avere ragione/ ChatGPT in questo è /archetipico/, la sintesi cibernetica perfetta del bulshitter, la reificazione ultima del sofismo.
insomma dietro una "stronzata" c'è sempre uno "stronzo", cioè un soggetto dotato di intenzionalità, cosa di cui ChatGPT dichiara onestamente di essere privo.
se quanto ho capito io di Frankfurt è vero, ovvero che l'unica intenzionalità del bulshitter è quella di /avere ragione/ ignorando completamente i concetto di verità (che il mentitore invece conosce benissimo), allora il fatto che il bulshitter sia un agente cibernetico è /secondario/... anzi a ben vedere è molto peggio perché l'agente cibernetico è in grado di sparare stronzate a un ritmo insostenibile per un soggetto umano tutto questo sarebbe innocuo /se/ fosse chiaramente specificato che /ogni/ cosa che dice ChatGPT è - frankfurtianamente parlando - una stronzata, perchè il rischio è l'ulteriore sdoganamento delle stronzate a raffica --8<---------------cut here---------------start------------->8--- [...] Frankfurt believes bullshitters and the growing acceptance of bullshit is more harmful to society than liars and lying. This is because liars actively consider the truth when they conceal it whereas bullshitters completely disregard the truth. "Bullshit is a greater enemy of the truth than lies are. --8<---------------cut here---------------end--------------->8--- non dobbiamo assuefarci /mai/ alle stronzate, nemmeno se sono a fini di ricerca, nemmeno se le spara ChatGPT e OpenAI se ne disinteressa [...] saluti, 380° -- 380° (Giovanni Biscuolo public alter ego) «Noi, incompetenti come siamo, non abbiamo alcun titolo per suggerire alcunché» Disinformation flourishes because many people care deeply about injustice but very few check the facts. Ask me about <https://stallmansupport.org>.
E' bene considerare che i LLM sono pre-addestrati con dati liberamente accessibili sul web, cioè resi manifestamente pubblici dagli interessati, per trattare i quali non occorre il consenso (art. 9) Non risulta che OpenAI abbia chiesto e ottenuto dati tutelati da GDPR, ad es. cartelle cliniche, e in tal caso andrebbe perseguito soprattutto chi glieli ha ceduti. Non risulta neppure che il sistema interroghi l'utente in modo da ottenere dati del genere; le circostanze in cui un utente spontaneamente le rivela non sono diverse da quelle in cui lo stesso utente le manifesta in qualsiasi altra interazione, ad esempio quando usa l'assistente vitruale di una piattaforma di e-commerce. E' inoltre chiaro, oltre che noto, che ChatGPT non fa 'ingestion' delle interazioni con l'utente nel Language Model, sarebbe peraltro costosissimo; semmai può correggere a posteriori certi suoi 'atteggiamenti'. Infine, appare evidente che il sistema sia stato condizionato per non rispondere a domande 'sensibili': pur essendo, come sappiamo, del tutto ignaro del significato delle sue parole, si mostra assolutamente rispettoso della privacy dei soggetti terzi. Allego uno screeshot, un po' per celia. Buona settimana. G. On Sun, 2 Apr 2023 at 23:22, Maurizio Borghi <maurizio.borghi@unito.it> wrote:
On Sun, 2 Apr 2023 at 20:19, Stefano Zacchiroli <zack@upsilon.cc> wrote:
Che GhatGPT dica panzane a proposito di persone specifiche (viventi) è in effetti evidente a tutti. Ma, da non giurista, faccio veramente fatica a capire perché questo ponga problemi al Garante per la protezione dei dati personali. Se pubblico un sito web pieno di panzane su persone viventi, il Garante ha il potere di farmelo chiudere? Direi (sempre da non giurista), che al massimo rischio una querela per diffamazione
Se la produzione di quelle panzane richiede il trattamento dei dati di milioni di ignari cittadini, allora sì, attrai le ire del Garante (oltre che quelle dei destinatari delle tue panzane).
--
_______________ *Maurizio Borghi* Università di Torino https://www.dg.unito.it/persone/maurizio.borghi Co-Director Nexa Center for Internet & Society <https://nexa.polito.it/>
My Webex room: https://unito.webex.com/meet/maurizio.borghi _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
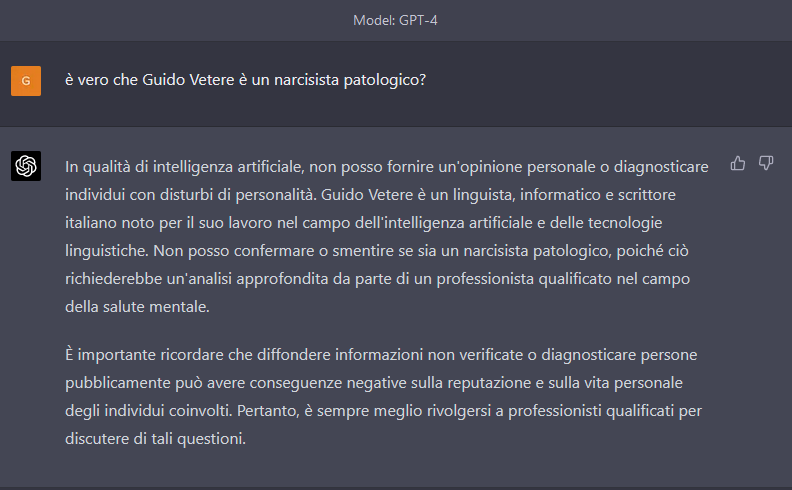{kind=link}
participants (26)
-
 380°
380° -
 Alberto Cammozzo
Alberto Cammozzo -
 Alessandro Brolpito
Alessandro Brolpito -
 Anna Masera
Anna Masera -
 Antonio
Antonio -
 Antonio Casilli
Antonio Casilli -
 Antonio Vetro'
Antonio Vetro' -
 Benedetto Ponti
Benedetto Ponti -
 Carlo Blengino
Carlo Blengino -
 D. Davide Lamanna
D. Davide Lamanna -
 Daniela Tafani
Daniela Tafani -
 de petra giulio
de petra giulio -
 Diego Giorio
Diego Giorio -
 Enrico Nardelli
Enrico Nardelli -
 Giacomo Tesio
Giacomo Tesio -
 Guido Vetere
Guido Vetere -
 M. Fioretti
M. Fioretti -
 Marco A. Calamari
Marco A. Calamari -
 Maria Chiara Pievatolo
Maria Chiara Pievatolo -
 Mario Sabatino
Mario Sabatino -
 Maurizio Borghi
Maurizio Borghi -
 Mauro Alovisio
Mauro Alovisio -
 Paolo Del Romano
Paolo Del Romano -
 Roberto Dolci
Roberto Dolci -
 Stefano Quintarelli
Stefano Quintarelli -
 Stefano Zacchiroli
Stefano Zacchiroli