Learning to reason with LLMs

{kind=link}

[cid:85c7e643-7da8-43d9-8980-8fa0888d4652] <https://nitter.poast.org/MelMitchell1/status/1834424918580076843> ________________________________________ Da: nexa <nexa-bounces@server-nexa.polito.it> per conto di Giuseppe Attardi <attardi@di.unipi.it> Inviato: venerdì 13 settembre 2024 00:36 A: nexa Oggetto: [nexa] Learning to reason with LLMs <https://openai.com/index/learning-to-reason-with-llms/> [o1-research.png] Learning to Reason with LLMs<https://openai.com/index/learning-to-reason-with-llms/> openai.com<https://openai.com/index/learning-to-reason-with-llms/>
{kind=link}

Thought for a couple of seconds
Non c'è che dire, in OpenAI sono (o si credono) dei geni :) Prima c'era la scelta casuale per simulare il "pensiero creativo", ora c'è il ritardo per simulare il "pensiero ragionato". Nel frattempo il termine "allucinazioni" trasborda dall'AI all'algoritmo. Titolo di oggi: "Le allucinazioni dell’algoritmo che assegna le cattedre dei supplenti" ( https://www.editorialedomani.it/tecnologia/scuola-algoritmo-cattedre-insegna... ). Forse sarebbe meglio abbandonare definitivamente OpenAI al suo destino e (ri)concentrarci sull'informatica "classica". A.

Ciao Antonio, On Sat, 14 Sep 2024 16:43:07 +0200 Antonio wrote:
Prima c'era la scelta casuale per simulare il "pensiero creativo", ora c'è il ritardo per simulare il "pensiero ragionato".
Il dizionario AI <-> Informatica si arricchisce di un nuovi elementi: Informatica | AI -----------------------|------------------------- Software | Modello | Compilazione | Training | Programmatore | Data Scientist | Bug | Hallucination | Bugfix | ¯\_(ツ)_/¯ | (see Boeing 747 Max) | /dev/random | Creativity | Data Augmentation | Chain of Thought | "Loading..." | "I'm thinking..." |
Forse sarebbe meglio abbandonare definitivamente OpenAI al suo destino e (ri)concentrarci sull'informatica "classica".
Tipo da Dijkstra? ;-) https://www.cs.utexas.edu/~EWD/transcriptions/EWD08xx/EWD898.html Più in generale bisognerebbe deridere chiunque antropomorfizzi cose. E allontanarlo da qualsiasi ruolo decisionale. E' urgente trovare un modo più serio e scientifico di definire, insegnare e discutere queste tecniche di programmazione statistica, ma di per sé le tecniche non sono completamente da buttare. Possono avere una loro applicabilità nei video giochi, ad esempio, la cui programmazione potrebbe avvicinare molti ragazzini. La matematica necessaria a comprendere il processo di programmazione statistica di una Vector Reducing Machine è quella che si fa al quarto / quinto anno delle superiori. E scrivere una Vector Reducing Machine in Python richiede un centinaio di righe di codice scarse. [1] Giacomo [1] ad esempio https://github.com/Shamar/ANN-decompiler/blob/master/vmm.py

*Talmente deprimente che persino il CEO di HuggingFace [4] ha reagito* *alla pagliacciata* *```* HuggingFace ospita attualmente più di 130.000 "open model" che fanno text-to-text generation, per lo più fine-tune dei modelli "tascabili" come quelli di Meta e DeepMind, specializzati per lingua e per task da università, imprese, ricercatori indipendenti. Questa reazione mostra come la tensione tra i fautori dell'AGI, cioè chi ha i mezzi per (dire di) realizzarla, e il resto del mondo della ricerca stia crescendo e diventando visibile. È su questo conflitto andrebbe fatta una riflessione. G. Il Sab 14 Set 2024, 22:16 Giacomo Tesio <giacomo@tesio.it> ha scritto:
Ciao Antonio,
On Sat, 14 Sep 2024 16:43:07 +0200 Antonio wrote:
Prima c'era la scelta casuale per simulare il "pensiero creativo", ora c'è il ritardo per simulare il "pensiero ragionato".
Il dizionario AI <-> Informatica si arricchisce di un nuovi elementi:
Informatica | AI -----------------------|------------------------- Software | Modello | Compilazione | Training | Programmatore | Data Scientist | Bug | Hallucination | Bugfix | ¯\_(ツ)_/¯ | (see Boeing 747 Max) | /dev/random | Creativity | Data Augmentation | Chain of Thought | "Loading..." | "I'm thinking..." |
Forse sarebbe meglio abbandonare definitivamente OpenAI al suo destino e (ri)concentrarci sull'informatica "classica".
Tipo da Dijkstra? ;-) https://www.cs.utexas.edu/~EWD/transcriptions/EWD08xx/EWD898.html
Più in generale bisognerebbe deridere chiunque antropomorfizzi cose. E allontanarlo da qualsiasi ruolo decisionale.
E' urgente trovare un modo più serio e scientifico di definire, insegnare e discutere queste tecniche di programmazione statistica, ma di per sé le tecniche non sono completamente da buttare.
Possono avere una loro applicabilità nei video giochi, ad esempio, la cui programmazione potrebbe avvicinare molti ragazzini.
La matematica necessaria a comprendere il processo di programmazione statistica di una Vector Reducing Machine è quella che si fa al quarto / quinto anno delle superiori.
E scrivere una Vector Reducing Machine in Python richiede un centinaio di righe di codice scarse. [1]
Giacomo
[1] ad esempio https://github.com/Shamar/ANN-decompiler/blob/master/vmm.py
Ma vedi Daniela, On Fri, 13 Sep 2024 18:59:01 +0000 Daniela Tafani wrote:
On Fri, 13 Sep 2024 00:36:09 +0200 Giuseppe Attardi wrote: Learning to Reason with LLMs openai.com https://openai.com/index/learning-to-reason-with-llms/
<https://nitter.poast.org/MelMitchell1/status/1834424918580076843>
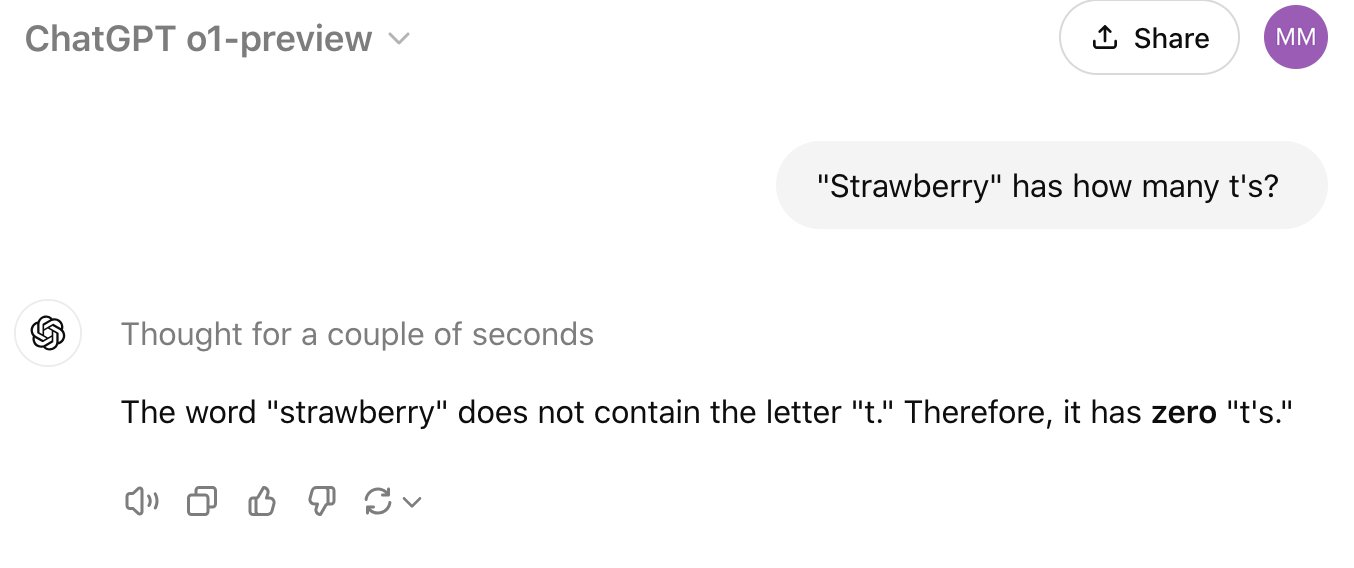
il problema non è tanto che o1 non funzioni [1], ma che persone autorevoli e preparate si bevano le sciocchezze che quelli di Open AI scrivono e si prestino a diffonderle ed amplificarle! Stiamo parlando della stessa Open AI che diffonde benchmark non riproducibili che confronta con statistiche biased [2] per dedurne dichiarazioni sensazionalistiche che vengono ripetute "a pappagallo" da pappagalli stocastici e non. Ma d'altro canto, che aspettarsi da chi utilizzava output cherry-picked dichiaratamente non riproducibili per dichiarare la presenza di "scintille di intelligenza generale" in GPT-4? [3] Tutto ciò è molto deprimente. Talmente deprimente che persino il CEO di HuggingFace [4] ha reagito alla pagliacciata ``` Once again, an AI system is not "thinking", it's "processing", "running predictions",... just like Google or computers do. Giving the false impression that technology systems are human is just cheap snake oil and marketing to fool you into thinking it's more clever than it is. ``` <https://nitter.lucabased.xyz/ClementDelangue/status/1834283206474191320> Che poi, non ci vuole un esperto per riconoscere un sistema soggetto a overfit [5]. Ed infatti la documentazione delle SDK ammonisce ``` Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response. ``` <https://sdk.vercel.ai/docs/guides/o1> Se o1 sapesse "ragionare come un PhD", saprebbe distinguere i dati superflui come fa un bambino alle elementari. Ma poiché riproduce in output versioni alterate dei manuali usati per la sua programmazione statistica, statisticamente correlate ai termini usati nel prompt, ogni termine in più, può alterare la navigazione dei contenuti compressi generando sciocchezze. Lo sapevano e hanno messo le mani avanti. Ma un prompt minimale e attinente ai casi d'uso previsti per o1 come quello provato da Colin Fraser: "can you solve the equation 9.11 - x = 9.9 + x?" dovrebbe funzionare. E invece, no. Sa contare le r in "Strawberry"... ma non le t. Overfitting, appunto. E devono esserne ben consapevoli se Tworek (ricercatore capo di OpenAI) dice a The Verge che non credono si possa comparare "AI model thinking" con "human thinking" [6] e Joanne Jang (OpenAI product manager) ha scritto su Twitter: "There's a lot of o1 hype on my feed, so I'm worried that it might be setting the wrong expectations." Ma nel loro annuncio "reason" compare 18 volte e "think" 9. Perché rischiare la faccia così? https://www.bloomberg.com/news/articles/2024-09-11/openai-fundraising-set-to... Pump & dump. Ed è triste vedere come molti si prestino al loro gioco. Giacomo [1] e non funziona (immagini in allegato, per archiviazione): https://nitter.poast.org/pic/orig/media%2FGXXjx11a4AA4UyG.png https://nitter.poast.org/pic/orig/media%2FGXXj6M0bcAAxruz.png https://nitter.poast.org/pic/orig/media%2FGXXkpmfawAA6Umf.png [2] <https://www.fastcompany.com/91073277/did-openais-gpt-4-really-pass-the-bar-e...> ricorda in questo le ricerche pseudo-scientifiche che dimostravano come un bicchiere di vino al giorno allungasse la vita rispetto a zero bicchieri, includendo nel campione pazienti terminali che non si alimentavano da soli e a cui non venivano somministrati alcolici. [3] <https://arxiv.org/abs/2303.12712> [4] non certo uno stinco di santo [5] <https://en.m.wikipedia.org/wiki/Overfitting> [6] https://www.theverge.com/2024/9/12/24242439/openai-o1-model-reasoning-strawb...
{kind=link}
{kind=link}
{kind=link}
participants (5)
-
 Antonio
Antonio -
 Daniela Tafani
Daniela Tafani -
 Giacomo Tesio
Giacomo Tesio -
 Giuseppe Attardi
Giuseppe Attardi -
 Guido Vetere
Guido Vetere