
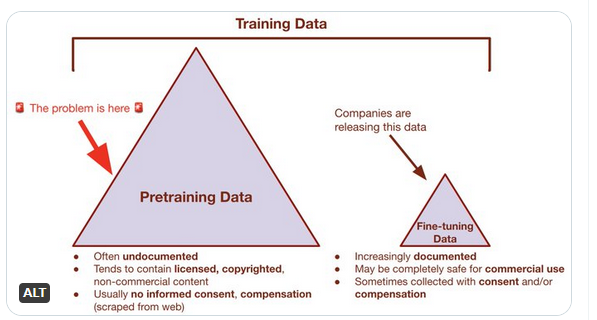
Ha scritto, su questa distinzione, un paio di giorni fa, Margaret Mitchell: "When AI companies release "open training data" for a model, they're generally sharing *fine-tuning* data. The big issues w data and consent are NOT of this type. The issues are with the MAIN DATA used in training" <https://nitter.snopyta.org/mmitchell_ai/status/1646242689862729728> [cid:98ff1663-62f2-4593-9e2b-a4c0486c3fa0] ________________________________ Da: nexa <nexa-bounces@server-nexa.polito.it> per conto di Giacomo Tesio <giacomo@tesio.it> Inviato: venerdì 14 aprile 2023 10:52 A: D. Davide Lamanna Cc: nexa@server-nexa.polito.it Oggetto: Re: [nexa] ChatGPT disabled for users in Italy Purtroppo no, Davide. Per rendere riproducibile ed ispezionabile il processo di programmazione statistica che costruisce un software LLM sono necessarie moltissime informazioni che lì mancano. Non foss'altro che per il semplice fatto che Dolly 2.0 si basa su GPT-3 e quindi, per poterne ispezionare la programmazione e poterne escludere (ad esempio) discriminazioni intenzionali, sarebbe necessario avere tutti i dati ed il processo esatto di programmazione di GPT-3 stesso. La relazione fra la verticalizzazione ("fine-tuning", lo definiscono gli autori dell'articolo associato al dataset che hai condiviso) e programmazione di un LLM è molto più... "intima" di quella che esiste fra un applicazione ed una libreria usata durante il suo sviluppo. E' più simile, se vuoi, a quella che intercorre fra un CMS e le pagine web che ne vengono pubblicate, la cui forma sarà sempre sostanzialmente la stessa perché i limiti (ciò che può o non può essere fatto con quel CMS) non vengono intaccati dal layout grafico del sito web, che si deve adattare inevitabilmente a quei vincoli (a meno di smettere di usare quel CMS, ovviamente). Inoltre, il dataset sorgente come viene solitamente condiviso in questi progetti fintamente "open source", non è sufficiente a riprodurre esattamente lo stato di un LLM. Sono necessari parametri iniziali delle "reti neurali" utilizzate, registrazioni dettagliate dell'ordine in cui i vari record sono stati usati durante la programmazione statistica (ad esempio, nel caso di quella tecnica che viene impropriamente chiamata "Reinforcement Learning") e così via. In sostanza, per poter ambire a dimostrare di NON aver iniettato una particolare discriminazione all'interno di GPT-4, Open AI dovrebbe fornire un bello scriptino, ben documentato, in grado di riprodurre ESATTAMENTE GPT-4 nello stato attualmente in produzione a partire dai testi di partenza (anch'essi inclusi nel pacchetto) e da tutte le altre sorgenti di input. Dovrebbe essere ovviamente uno script ben leggibile e debuggabile passo passo. A quel punto si potrebbe effettuare un confronto binario fra gli output prodotti dallo script e GPT-4 in produzione, e dopo averne verificato la corrispondenza esatta, analizzare i dataset sorgente e il processo di compilazione di tale software alla ricerca di discriminazioni o problemi. Nulla di lontanamente paragonabile a quello che ha fatto Databricks, insomma. Purtuttavia qualcosa di perfettamente fattibile da un punto di vista tecnico, sebbene estremamente costoso. Giacomo On Fri, 14 Apr 2023 09:36:30 +0200 D. Davide Lamanna wrote:
On 4/13/23 12:49, Giacomo Tesio wrote:
Basta imporre che tutti i dataset utilizzati durante la programmazione statistica ("training" nella vulgata), inclusi quelli usati per la cross validation e il test, nonché tutti gli altri dati necessari a riprodurre esattamente il processo ed ottenere esattamente il modello in produzione (e le sue alternative scartate), siano preservati per tutta la durata della sua permanenza in produzione e diciamo 20 anni dopo (in caso di aggiornamento). [1]
Rendendo verficabilmente e completamente riproducibile il processo di programmazione statistica, Open AI (come chiunque altro) potrà facilmente dimostrare di non aver utilizzato dati ottenuti in violazione di qualsisi Legge.
Ciao Giacomo,
una cosa così?
<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...>.
<https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...>.
D.
(null) _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...
_______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://es.sonicurlprotection-fra.com/click?PV=2&MSGID=202304140852190176174...
{kind=link}